% / ATR Buy, Target, Stop + Overlay & P/L% / ATR Buy, Target, Stop + Overlay & P/L
This tool combines volatility‑based and fixed‑percentage trade planning into a single, on‑chart overlay—with built‑in profit‑and‑loss estimates. Toggle between ATR or percentage modes, plot your Buy, Target and Stop levels, and see the dollar gain or loss for a specified position size—all in one interactive table and chart display.
NOTE: To activate plotted lines, price labels, P/L rows and table values, enter a Buy Price greater than zero.
What It Does
Mode Toggle: Choose between “ATR” (volatility‑based) or “%” (fixed‑percentage) calculations.
Buy Price Input: Manually enter your entry price.
ATR Mode:
Target = Buy + (ATR × Target Multiplier)
Stop = Buy − (ATR × Stop Multiplier)
Percentage Mode:
Target = Buy × (1 + Target % / 100)
Stop = Buy × (1 – Stop % / 100)
P/L Estimates: Specify a dollar amount to “invest” at your Buy price, and the script calculates:
Gain ($): Profit if Target is hit
Loss ($): Cost if Stop is hit
Visual Overlay: Draws horizontal lines for Buy, Target and Stop, with optional price labels on the chart scale.
Interactive Table: Displays Buy, Target, Stop, ATR/timeframe info (in ATR mode), percentages (in % mode), and P/L rows.
Customization Options
Line Settings:
Choose color, style (solid/dashed/dotted), and width for Buy, Target, Stop lines.
Extend lines rightward only or in both directions.
Table Settings:
Position the table (top/bottom × left/right).
Toggle individual rows: Buy Price; Target (multiplier or %); Stop (multiplier or %); Target ATR %; Stop ATR %; ATR Time Frame; ATR Value; Gain ($); Loss ($).
Customize text colors for each row and background transparency.
General Inputs:
ATR length and optional ATR timeframe override (e.g. use daily ATR on an intraday chart).
Target/Stop multipliers or percentages.
Dollar Amount for P/L calculations.
How to Use It for Trading
Plan Your Entry: Enter your intended Buy Price and position size (dollar amount).
Select Mode: Toggle between ATR or % mode depending on whether you prefer volatility‑based or fixed offsets.
Assess R:R and P/L: Instantly see your Target, Stop levels, and potential profit or loss in dollars.
Visual Reference: Lines and price labels update in real time as you tweak inputs—ideal for live trading, backtesting or trade journaling.
Ideal For
Traders who want both volatility‑based and percentage‑based exit options in one tool
Those who need on‑chart P/L estimates based on position size
Swing and intraday traders focused on objective, rule‑based trade management
Anyone who uses ATR for adaptive stops/targets or fixed percentages for simpler exits
Estimate
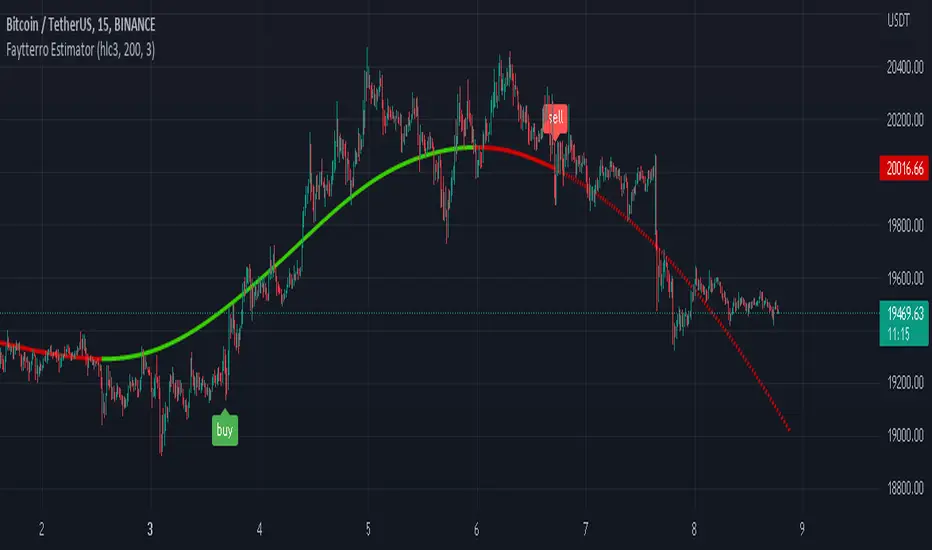
Faytterro EstimatorWhat is Faytterro Estimator?
This indicator is an advanced moving average.
What it does?
This indicator is both a moving average and at the same time, it predicts the future values that the price may take based on the values it has taken before.
How it does it?
takes the weighted average of data of the selected length (reducing the weight from the middle to the ends). then draws a parabola through the last three values, creating a predicted line.
How to use it?
it is simple to use. You can use it both as a regression to review past prices, and to predict the future value of a price. uptrends are in green and downtrends are in red. color change indicates a possible trend change.
Hodrick-Prescott Extrapolation of Price [Loxx]Hodrick-Prescott Extrapolation of Price is a Hodrick-Prescott filter used to extrapolate price.
The distinctive feature of the Hodrick-Prescott filter is that it does not delay. It is calculated by minimizing the objective function.
F = Sum((y(i) - x(i))^2,i=0..n-1) + lambda*Sum((y(i+1)+y(i-1)-2*y(i))^2,i=1..n-2)
where x() - prices, y() - filter values.
If the Hodrick-Prescott filter sees the future, then what future values does it suggest? To answer this question, we should find the digital low-frequency filter with the frequency parameter similar to the Hodrick-Prescott filter's one but with the values calculated directly using the past values of the "twin filter" itself, i.e.
y(i) = Sum(a(k)*x(i-k),k=0..nx-1) - FIR filter
or
y(i) = Sum(a(k)*x(i-k),k=0..nx-1) + Sum(b(k)*y(i-k),k=1..ny) - IIR filter
It is better to select the "twin filter" having the frequency-independent delay Тdel (constant group delay). IIR filters are not suitable. For FIR filters, the condition for a frequency-independent delay is as follows:
a(i) = +/-a(nx-1-i), i = 0..nx-1
The simplest FIR filter with constant delay is Simple Moving Average (SMA):
y(i) = Sum(x(i-k),k=0..nx-1)/nx
In case nx is an odd number, Тdel = (nx-1)/2. If we shift the values of SMA filter to the past by the amount of bars equal to Тdel, SMA values coincide with the Hodrick-Prescott filter ones. The exact math cannot be achieved due to the significant differences in the frequency parameters of the two filters.
To achieve the closest match between the filter values, I recommend their channel widths to be similar (for example, -6dB). The Hodrick-Prescott filter's channel width of -6dB is calculated as follows:
wc = 2*arcsin(0.5/lambda^0.25).
The channel width of -6dB for the SMA filter is calculated by numerical computing via the following equation:
|H(w)| = sin(nx*wc/2)/sin(wc/2)/nx = 0.5
Prediction algorithms:
The indicator features the two prediction methods:
Metod 1:
1. Set SMA length to 3 and shift it to the past by 1 bar. With such a length, the shifted SMA does not exist only for the last bar (Bar = 0), since it needs the value of the next future price Close(-1).
2. Calculate SMA filer's channel width. Equal it to the Hodrick-Prescott filter's one. Find lambda.
3. Calculate Hodrick-Prescott filter value at the last bar HP(0) and assume that SMA(0) with unknown Close(-1) gives the same value.
4. Find Close(-1) = 3*HP(0) - Close(0) - Close(1)
5. Increase the length of SMA to 5. Repeat all calculations and find Close(-2) = 5*HP(0) - Close(-1) - Close(0) - Close(1) - Close(2). Continue till the specified amount of future FutBars prices is calculated.
Method 2:
1. Set SMA length equal to 2*FutBars+1 and shift SMA to the past by FutBars
2. Calculate SMA filer's channel width. Equal it to the Hodrick-Prescott filter's one. Find lambda.
3. Calculate Hodrick-Prescott filter values at the last FutBars and assume that SMA behaves similarly when new prices appear.
4. Find Close(-1) = (2*FutBars+1)*HP(FutBars-1) - Sum(Close(i),i=0..2*FutBars-1), Close(-2) = (2*FutBars+1)*HP(FutBars-2) - Sum(Close(i),i=-1..2*FutBars-2), etc.
The indicator features the following inputs:
Method - prediction method
Last Bar - number of the last bar to check predictions on the existing prices (LastBar >= 0)
Past Bars - amount of previous bars the Hodrick-Prescott filter is calculated for (the more, the better, or at least PastBars>2*FutBars)
Future Bars - amount of predicted future values
The second method is more accurate but often has large spikes of the first predicted price. For our purposes here, this price has been filtered from being displayed in the chart. This is why method two starts its prediction 2 bars later than method 1. The described prediction method can be improved by searching for the FIR filter with the frequency parameter closer to the Hodrick-Prescott filter. For example, you may try Hanning, Blackman, Kaiser, and other filters with constant delay instead of SMA.
Related indicators
Itakura-Saito Autoregressive Extrapolation of Price
Helme-Nikias Weighted Burg AR-SE Extra. of Price
Weighted Burg AR Spectral Estimate Extrapolation of Price
Levinson-Durbin Autocorrelation Extrapolation of Price
Fourier Extrapolator of Price w/ Projection Forecast

Estimate, Earnings, Surprise EarningsThis plot helps you to show estimate earnings , reported earnings , and surprise earnings of a company inside a chart.
Estimate earnings is the projection of earnings of a company by the analysts for a given period of time.
Earnings is a company's reported profits (or sometimes a loss if going negative) in a given quarter or fiscal year.
Surprise earnings is an earning (or sometimes a loss if going negative) which is above (or even below) the estimated or reported earnings.
Estimate earning is plotted by white lines
Reported Earnings is plotted by columns, where positive number is blue and negative number is purple.
Surprise Earnings is plotted by columns, where positive number is green and negative number is red.
You surely will be able to tweak and customize all the colors above with color you find comfortable.
Since earnings are reported every quarter of the year, this plot will gives a good view when you put it inside a 3 Months timeframe.
Hope this helpful.

HEMA - A Fast And Efficient Estimate Of The Hull Moving AverageIntroduction
The Hull moving average (HMA) developed by Alan Hull is one of the many moving averages that aim to reduce lag while providing effective smoothing. The HMA make use of 3 linearly weighted (WMA) moving averages, with respective periods p/2 , p and √p , this involve three convolutions, which affect computation time, a more efficient version exist under the name of exponential Hull moving average (EHMA), this version make use of exponential moving averages instead of linearly weighted ones, which dramatically decrease the computation time, however the difference with the original version is clearly noticeable.
In this post an efficient and simple estimate is proposed, the estimation process will be fully described and some comparison with the original HMA will be presented.
This post and indicator is dedicated to LucF
Estimation Process
Estimating a moving average is easier when we look at its weights (represented by the impulse response), we basically want to find a similar set of weights via more efficient calculations, the estimation process is therefore based on fully understanding the weighting architecture of the moving average we want to estimate.
The impulse response of an HMA of period 20 is as follows :
We can see that the first weights increases a bit before decaying, the weights then decay, cross under 0 and increase again. More recent closing price values benefits of the highest weights, while the oldest values have negatives ones, negative weighting is what allow to drastically reduce the lag of the HMA. Based on this information we know that our estimate will be a linear combination of two moving averages with unknown coefficients :
a × MA1 + b × MA2
With a > 0 and b < 0 , the lag of MA1 is lower than the lag of MA2 . We first need to capture the general envelope of the weights, which has an overall non-linearly decaying shape, therefore the use of an exponential moving average might seem appropriate.
In orange the impulse response of an exponential moving average of period p/2 , that is 10. We can see that such impulse response is not a bad estimate of the overall shape of the HMA impulse response, based on this information we might perform our linear combination with a simple moving average :
2EMA(p/2) + -1SMA(p)
this gives the following impulse response :
As we can see there is a clear lack of accuracy, but because the impulse response of a simple moving is a constant we can't have the short increasing weights of the HMA, we therefore need a non-constant impulse response for our linear combination, a WMA might be appropriate. Therefore we will use :
2WMA(p/2) + -1EMA(p/2)
Note that the lag a WMA is inferior to the lag of an EMA of same period, this is why the period of the WMA is p/2 . We obtain :
The shape has improved, but the fit is poor, which mean we should change our coefficients, more precisely increasing the coefficient of the WMA (thus decreasing the one of the EMA). We will try :
3WMA(p/2) + -2EMA(p/2)
We then obtain :
This estimate seems to have a decent fit, and this linear combination is therefore used.
Comparison
HMA in blue and the estimate in fuchsia with both period 50, the difference can be noted, however the estimate is relatively accurate.
In the image above the period has been set to 200.
Conclusion
In this post an efficient estimate of the HMA has been proposed, we have seen that the HMA can be estimated via the linear combinations of a WMA and an EMA of each period p/2 , this isn't important for the EMA who is based on recursion but is however a big deal for the WMA who use recursion, and therefore p indicate the number of data points to be used in the convolution, knowing that we use only convolution and that this convolution use twice less data points then one of the WMA used in the HMA is a pretty great thing.
Subtle tweaking of the coefficients/moving averages length's might help have an even more accurate estimate, the fact that the WMA make use of a period of √p is certainly the most disturbing aspect when it comes to estimating the HMA. I also described more in depth the process of estimating a moving average.
I hope you learned something in this post, it took me quite a lot of time to prepare, maybe 2 hours, some pinescripters pass an enormous amount of time providing content and helping the community, one of them being LucF, without him i don't think you'll be seeing this indicator as well as many ones i previously posted, I encourage you to thank him and check his work for Pinecoders as well as following him.
Thanks for reading !

Standard Deviation - Sum Of The Squares Minus Square Of The SumsIntroduction
The standard deviation measure the dispersion of a data set, in short this metric will tell you if your data is on average closer or farther away from the mean. Its one of the most important tools in statistics and living without it is pretty much impossible, without it you can forget about Bollinger-bands, CCI, and even the LSMA (ouch this hurt) .
Now i don't want to extend myself about the standard deviation since that would require a huge post but i want to show you how to calculate the standard deviation from the stdev pinescript function.
Sum Of The Squares Minus Square Of The Sums
Any metric calculated from a moving average can be classified as "running", this mean that the metric constantly update itself and is not constant, this is why it is better to say "running standard deviation" but its okay. If we use the standard calculation for the standard deviation which would be sqrt(sma(pow(close - sma,2))) we might get something totally different from the stdev function :
In white the pine stdev function and in red the standard calculation of both period 4, its clear that both are not the same, one might try to use the Bessel's correction but that won't do either, this is because most technical analysis tools will calculate the square root of the "Sum Of The Squares Minus Square Of The Sums" method to estimate the standard deviation
Another way is to use :
a = sqrt(sma(pow(close,2),length) - pow(sma(close,length),2))
By returning the difference we might still see some errors :
Nothing relevant of course.
Conclusion
Some of you might already be aware of this but a reminder is always good since it can be confusing to make what can be considered the good standard deviation formula and then have something totally different from the pine function, i hope this post will be useful and that you learned something from it.
Thanks for reading :)

Japanese Correlation CoefficientIntroduction
This indicator was asked and named by a trading meetup participant in Sevilla. The original question was "How to estimate the correlation between the price and a line as easy as possible", a question who got little attention. I previously proposed a correlation estimate using a modification of the standard score (see at the end of the post) for the estimation of a Savitzky-Golay moving average (LSMA) of order 1, however something faster could maybe be done and this is why i accepted the challenge.
Japanese Correlation
Correlation is defined as the linear relationship between two variables x and y , if x and y follow the same direction then the correlation increase else decrease. The correlation coefficient is always equal or below 1 and equal or above -1, it also have to be taken into account that this coefficient is quite smooth. Smoothing is not a problem, scaling however require more attention, high price > closing price > low price, therefore scaling can be done. First we smooth the closing/high/low price with a simple moving average of period p/2 , then we take the difference of the smoothed close with the smoothed close p/2 bars back, this result is then divided by the difference between the highest smoothed high's with the lowest smoothed low's over period p/2 .
Since we use information provided by candlesticks (close/high/low) i have been asked to publish this estimator with the name Japanese correlation coefficient , this name don't imply the use of data from Japanese markets, "Japanese" is used because of the candlestick method coming from Japan.
Comparison
I compare this estimation with the correlation coefficient provided in pinescript by the correlation function.
The estimation in orange with the original correlation coefficient using n as independent variable in blue with both length = 50.
comparison with length = 200.
Conclusion
I have shown that it is possible to roughly estimate the correlation coefficient between price and a linear function by using different price information. Correlation can be further estimated by using homogeneous bridge OHLC volatility estimators thus making able the use of different independent variables. I really hope you like this indicator and thanks to the meetup participant asking the question, i had a lot of fun making the indicator.
An alternative method

