Pro Momentum Table + Trade Alerts📊 Indicator Name: Pro Momentum Table – ADX + DI + ATR + Astro Timing
🧠 Concept:
This indicator is designed for professional scalpers and intraday traders who want to capture only strong momentum waves — not noise. It combines trend strength, volatility, directional movement, momentum oscillation, vega divergence, and astrological timing into a single compact table on your chart.
⚙️ Components Explained:
Metric Description
ADX (Average Directional Index) Measures the strength of the trend. Values above 20 indicate that a meaningful move is starting.
+DI / -DI (Directional Indicators) Show whether buyers (+DI) or sellers (-DI) are dominating. Increasing +DI with ADX rising = bullish momentum. Increasing -DI with ADX rising = bearish momentum.
ATR (Average True Range) Shows volatility and expected range. Used for setting realistic stop-loss and multi-level targets (1×, 1.5×, 2×, 2.5× ATR).
Price Displays the current price level for quick reference.
CMO (Chande Momentum Oscillator) Measures short-term momentum direction and strength. Helps identify overbought/oversold conditions in trend continuation.
Vega Divergence Shows a synthetic reading of volatility pressure — "Bullish" when volatility expansion supports upward moves, "Bearish" for downward pressure, and "Neutral" otherwise.
Astro Remark Suggests ideal time windows based on planetary cycles for scalping entries. “Bullish Window” often aligns with high-probability long trades; “Bearish Window” favors shorts.
Trade Signal The core momentum condition: “Bullish Momentum” if ADX > 20 and +DI rising, “Bearish Momentum” if ADX > 20 and -DI rising, else “No Clear Momentum.”
📈 How to Use:
Wait for ADX > 20 – This confirms that the market is entering a strong momentum phase.
Check DI direction:
✅ +DI rising: Buyers gaining strength → look for long setups.
✅ -DI rising: Sellers gaining strength → look for short setups.
Use ATR to plan exits:
🎯 TP1 = Entry ± 1 × ATR
🎯 TP2 = Entry ± 1.5 × ATR
🎯 TP3 = Entry ± 2 × ATR
🎯 TP4 = Entry ± 2.5 × ATR
CMO & Vega Divergence: Confirm momentum direction and volatility expansion before committing.
Astro Remark: Align your scalping activity with the planetary support window for higher probability trades.
🪙 Pro Tips for Scalpers:
Only trade when ADX > 20 and DI is consistently rising. Ignore signals in choppy or sideways phases.
Avoid trades if Vega is neutral and CMO is flat – these usually indicate fake breakouts.
If targets aren’t hit within expected ATR-based time, treat the move as false and exit early.
Combine with 9 EMA and 20 EMA (hidden) for wave structure confirmation without cluttering the chart.
💡 Summary:
This indicator acts as a real-time trade decision dashboard. It removes clutter from the chart and delivers everything a professional scalper needs — strength, direction, volatility, momentum, timing, and actionable trade bias — all in one elegant table.
在腳本中搜尋"如何用wind搜索股票的发行价和份数"

Volume-Weighted Money Flow [sgbpulse]Overview
The VWMF indicator is an advanced technical analysis tool that combines and summarizes five leading momentum and volume indicators (OBV, PVT, A/D, CMF, MFI) into one clear oscillator. The indicator helps to provide a clear picture of market sentiment by measuring the pressure from buyers and sellers. Unlike single indicators, VWMF provides a comprehensive view of market money flow by weighting existing indicators and presenting them in a uniform and understandable format.
Indicator Components
VWMF combines the following indicators, each normalized to a range of 0 to 100 before being weighted:
On-Balance Volume (OBV): A cumulative indicator that measures positive and negative volume flow.
Price-Volume Trend (PVT): Similar to OBV, but incorporates relative price change for a more precise measure.
Accumulation/Distribution Line (A/D): Used to identify whether an asset is being bought (accumulated) or sold (distributed).
Chaikin Money Flow (CMF): Measures the money flow over a period based on the close price's position relative to the candle's range.
Money Flow Index (MFI): A momentum oscillator that combines price and volume to measure buying and selling pressure.
Understanding the Normalized Oscillators
The indicator combines the five different momentum indicators by normalizing each one to a uniform range of 0 to 100 .
Why is Normalization Important?
Indicators like OBV, PVT, and the A/D Line are cumulative indicators whose values can become very large. To assess their trend, we use a Moving Average as a dynamic reference line . The Moving Average allows us to understand whether the indicator is currently trending up or down relative to its average behavior over time.
How Does Normalization Work?
Our normalization fully preserves the original trend of each indicator.
For Cumulative Indicators (OBV, PVT, A/D): We calculate the difference between the current indicator value and its Moving Average. This difference is then passed to the normalization process.
- If the indicator is above its Moving Average, the difference will be positive, and the normalized value will be above 50.
- If the indicator is below its Moving Average, the difference will be negative, and the normalized value will be below 50.
Handling Extreme Values: To overcome the issue of extreme values in indicators like OBV, PVT, and the A/D Line , the function calculates the highest absolute value over the selected period. This value is used to prevent sharp spikes or drops in a single indicator from compromising the accuracy of the normalization over time. It's a sophisticated method that ensures the oscillators remain relevant and accurate.
For Bounded Indicators (CMF, MFI): These indicators already operate within a known range (for example, CMF is between -1 and 1, and MFI is between 0 and 100), so they are normalized directly without an additional reference line.
Reference Line Settings:
Moving Average Type: Allows the user to choose between a Simple Moving Average (SMA) and an Exponential Moving Average (EMA).
Volume Flow MA Length: Allows the user to set the lookback period for the Moving Average, which affects the indicator's sensitivity.
The 50 line serves as the new "center line." This ensures that, even after normalization, the determination of whether a specific indicator supports a bullish or bearish trend remains clear.
Settings and Visual Tools
The indicator offers several customization options to provide a rich analysis experience:
VWMF Oscillator (Blue Line): Represents the weighted average of all five indicators. Values above 50 indicate bullish momentum, and values below 50 indicate bearish momentum.
Strength Metrics (Bullish/Bearish Strength %): Two metrics that appear on the status line, showing the percentage of indicators supporting the current trend. They range from 0% to 100%, providing a quick view of the strength of the consensus.
Dynamic Background Colors: The background color of the chart automatically changes to bullish (a blue shade by default) or bearish (a default brown-gray shade) based on the trend. The transparency of the color shows the consensus strength—the more opaque the background, the more indicators support the trend.
Advanced Settings:
- Background Color Logic: Allows the user to choose the trigger for the background color: Weighted Value (based on the combined oscillator) or Strength (based on the majority of individual indicators).
- Weights: Provides full control over the weight of each of the five indicators in the final oscillator.
Using the Data Window
TradingView provides a useful Data Window that allows you to see the exact numerical values of each normalized oscillator separately, in addition to the trend strength data.
You can use this window to:
Get more detailed information on each indicator: Viewing the precise numerical data of each of the five indicators can help in making trading decisions.
Calibrate weights: If you want to manually adjust the indicator weights (in the settings menu), you can do so while tracking the impact of each indicator on the weighted oscillator in the Data Window.
The indicator's default setting is an equal weight of 20% for each of the five indicators.
Alert Conditions
The indicator comes with a variety of built-in alerts that can be configured through the TradingView alerts menu:
VWMF Cross Above 50: An alert when the VWMF oscillator crosses above the 50 line, indicating a potential bullish momentum shift.
VWMF Cross Below 50: An alert when the VWMF oscillator crosses below the 50 line, indicating a potential bearish momentum shift.
Bullish Strength: High But Not Absolute Consensus: An alert when the bullish trend strength reaches 60% or more but is less than 100%, indicating a high but not absolute consensus.
Bullish Strength at 100%: An alert when all five indicators (MFI, OBV, PVT, A/D, CMF) show bullish strength, indicating a full and absolute consensus.
Bearish Strength: High But Not Absolute Consensus: An alert when the bearish trend strength reaches 60% or more but is less than 100%, indicating a high but not absolute consensus.
Bearish Strength at 100%: An alert when all five indicators (MFI, OBV, PVT, A/D, CMF) show bearish strength, indicating a full and absolute consensus.
Summary
The VWMF indicator is a powerful, all-in-one tool for analyzing market momentum, money flow, and sentiment. By combining and normalizing five different indicators into a single oscillator, it offers a holistic and accurate view of the market's underlying trend. Its dynamic visual features and customizable settings, including the ability to adjust indicator weights, provide a flexible experience for both novice and experienced traders. The built-in alerts for momentum shifts and trend consensus make it an effective tool for spotting trading opportunities with confidence. In essence, VWMF distills complex market data into clear, actionable signals.
Important Note: Trading Risk
This indicator is intended for educational and informational purposes only and does not constitute investment advice or a recommendation for trading in any form whatsoever.
Trading in financial markets involves significant risk of capital loss. It is important to remember that past performance is not indicative of future results. All trading decisions are your sole responsibility. Never trade with money you cannot afford to lose.

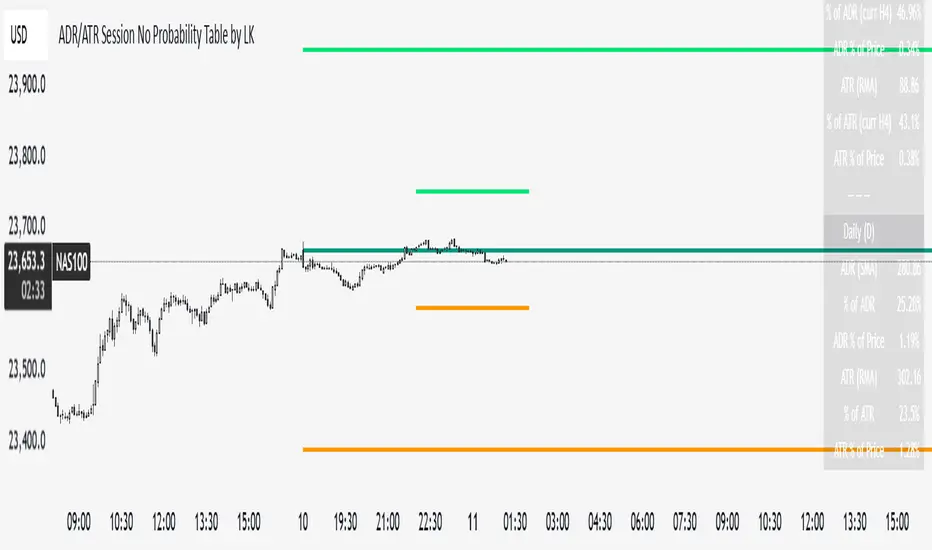
ADR/ATR Session No Probability Table by LKHere you go—clear, English docs you can drop into your script’s description or share with teammates.
ADR/ATR Session by LK — Overview
This indicator summarizes Average Daily Range (ADR) and Average True Range (ATR) for two horizons:
• Session H4 (e.g., 06:00–13:00 on a 4‑hour chart)
• Daily (D)
It shows:
• Current ADR/ATR values (using your chosen smoothing method)
• How much of ADR/ATR today/this bar has already been consumed (% of ADR/ATR)
• ADR/ATR as a percent of price
• Optional probability blocks: likelihood that %ADR will exceed user‑defined thresholds over a lookback window
• Optional on‑chart lines for the current H4 and Daily candles: Open, ADR High, ADR Low
⸻
What the metrics mean
• ADR (H4 / D): Moving average of the bar range (high - low).
• ATR (H4 / D): Moving average of True Range (max(hi-lo, |hi-close |, |lo-close |)).
• % of ADR (curr H4): (H4 range of the current H4 bar) / ADR(H4) × 100. Updates live even if the current time is outside the session.
• % of ADR (Daily): (today’s intra‑day range) / ADR(D) × 100.
• % of ATR (curr H4 / Daily): TR / ATR × 100 for that horizon.
• ADR % of Price / ATR % of Price: ADR or ATR divided by current price × 100 (a quick “volatility vs. price” gauge).
Session logic (H4): ADR/ATR(H4) only update on bars that fall inside the configured session window; outside the window the values hold steady (no recalculation “bleed”).
Daily range tracking: The indicator tracks today’s high/low in real‑time and resets at the day change.
⸻
Inputs (quick reference)
Core
• Length (ADR/ATR): smoothing length for ADR/ATR (default 21).
• Wait for Higher TF Bar Close: if true, updates ADR/ATR only after the higher‑TF bar closes when using request.security.
Timeframes
• Session Timeframe (H4): default 240.
• Daily Timeframe: default D.
Session time
• Session Timezone: “Chart” (default) or a fixed timezone.
• Session Start Hour, End Hour (minutes are fixed to 0 in this version).
Smoothing methods
• H4 ADR Method / H4 ATR Method: SMA/EMA/RMA/WMA.
• Daily ADR Method / Daily ATR Method: SMA/EMA/RMA/WMA.
Table appearance
• Table BG, Table Text, Table Font Size.
Lines (optional)
• Show current H4 segments, Show current Daily segments
• Line colors for Open / ADR High / ADR Low
• Line width
Probability
• H4 Probability Lookback (bars): number of H4 bars to examine (e.g., 300).
• Daily Probability Lookback (days): number of D bars (e.g., 180).
• ADR thresholds (%): CSV list of thresholds (e.g., 25,50,55,60,65,70,75,80,85,90,95,100,125,150).
The table will show the % of lookback bars where %ADR ≥ threshold.
Tip: If you want probabilities only for session H4 bars (not every H4 bar), ask and I can add a toggle to filter by inSess.
⸻
How to read the table
H4 block
• ADR (method) / ATR (method): the session‑aware averages.
• % of ADR (curr H4): live progress of this H4 bar toward the session ADR.
• ADR % of Price: ADR(H4) relative to price.
• % of ATR (curr H4) and ATR % of Price: same idea for ATR.
H4 Probability (lookback N bars)
• Rows like “≥ 80% ADR” show the fraction (in %) of the last N H4 bars that reached at least 80% of ADR(H4).
Daily block
• Mirrors the H4 block, but for Daily.
Daily Probability (lookback M days)
• Rows like “≥ 100% ADR” show the fraction of the last M daily bars whose daily range reached at least 100% of ADR(D).
⸻
Practical usage
• Use % of ADR (curr H4 / Daily) to judge exhaustion or room left in the day/session.
E.g., if Daily %ADR is already 95%, be cautious with momentum continuation trades.
• The probability tables give a quick historical context:
If “≥ 125% ADR” is ~18%, the market rarely stretches that far; your trade sizing/targets can reflect that.
• ADR/ATR % of Price helps normalize volatility between instruments.
⸻
Troubleshooting
• If probability rows are blank: ensure lookback windows are large enough (and that the chart has enough history).
• If ADR/ATR show … (NA): usually you don’t have enough bars for the chosen length/TF yet.
• If line segments are missing: verify you’re on a chart with visible current H4/D bars and the toggles are enabled.
⸻
Notes & customization ideas
• Add a toggle to count only session bars in H4 probability.
• Add separate thresholds for H4 vs Daily.
• Let users pick minutes for session start/end if needed.
• Add alerts when %ADR crosses specified thresholds.
If you want me to bundle any of the “ideas” above into the code, say the word and I’ll ship a clean patch.
Opening Range Breakout🧭 Overview
The Open Range Breakout (ORB) indicator is designed to capture and display the initial price range of the trading day (typically the first 15 minutes), and help traders identify breakout opportunities beyond this range. This is a popular strategy among intraday and momentum traders.
🔧 Features
📊 ORB High/Low Lines
Plots horizontal lines for the session’s high and low
🟩 Breakout Zones
Background highlights when price breaks above or below the range
🏷️ Breakout Labels
Text labels marking breakout events
🧭 Session Control
Customizable session input (default: 09:15–09:30 IST)
📍 ORB Line Labels
Text labels anchored to the ORB high and low lines (aligned right)
🔔 Alerts
Configurable alerts for breakout events
⚙️ Adjustable Settings
Show/hide background, labels, session window, etc.
⏱️ Session Logic
• The ORB range is calculated during a defined session window (default: 09:15–09:30).
• During this window, the highest high and lowest low are recorded as ORB High and ORB Low.
📈 Breakout Detection
• Breakout Above: Triggered when price crosses above the ORB High.
• Breakout Below: Triggered when price crosses below the ORB Low.
• Each breakout can trigger:
• A background highlight (green/red)
• A text label (“Breakout ↑” / “Breakout ↓”)
• An optional alert
🔔 Alerts
Two built-in alert conditions:
1. Breakout Above ORB High
• Message: "🔼 Price broke above ORB High: {{close}}"
2. Breakout Below ORB Low
• Message: "🔽 Price broke below ORB Low: {{close}}"
You can create alerts in TradingView by selecting these from the Add Alert window.
📌 Best Use Cases
• Intraday momentum trading
• Breakout and scalping strategies
• First 15-minute range traders (NSE, BSE markets)

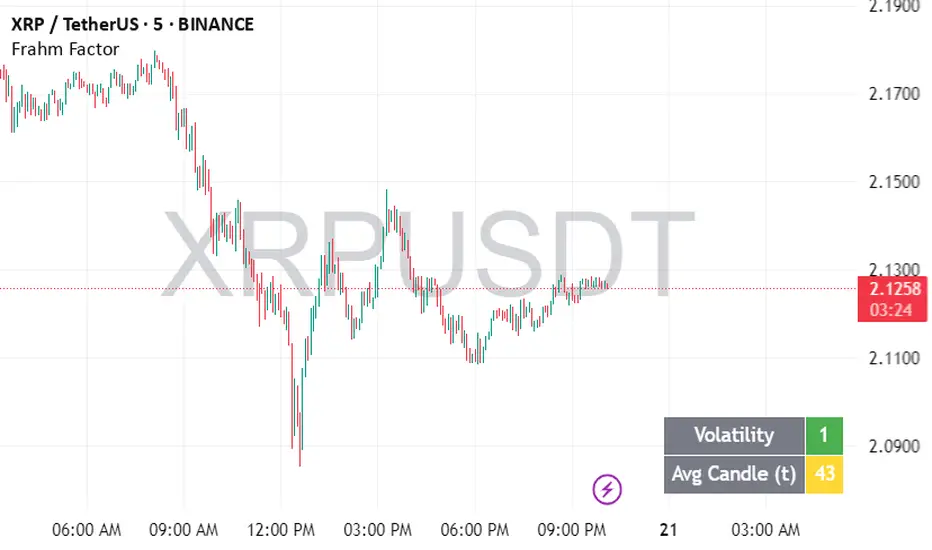
Frahm FactorIntended Usage of the Frahm Factor Indicator
The Frahm Factor is designed to give you a rapid, at-a-glance assessment of how volatile the market is right now—and how large the average candle has been—over the most recent 24-hour window. Here’s how to put it to work:
Gauge Volatility Regimes
Volatility Score (1–10)
A low score (1–3, green) signals calm seas—tight ranges, low risk of big moves.
A mid score (4–6, yellow) warns you that volatility is picking up.
A high score (7–10, red) tells you to prepare for disorderly swings or breakout opportunities.
How to trade off it
In low-volatility periods, you might favor mean-reversion or range-bound strategies.
As the score climbs into the red zone, consider widening stops, scaling back position size, or switching to breakout momentum plays.
Monitor Average Candle Size
Avg Candle (ticks) cell shows you the mean true-range of each bar over that 24h window in ticks.
When candles are small, you know the market is consolidating and liquidity may be thin.
When candles are large, momentum and volume are driving strong directional bias.
The optional dynamic color ramp (green→yellow→red) immediately flags when average bar size is unusually small or large versus its own 24h history.
Customize & Stay Flexible
Timeframes: Works on any intraday chart—from 1-minute scalping to 4-hour swing setups—because it always looks back exactly 24 hours.
Toggles:
Show or hide the Volatility and Avg-Candle cells to keep your screen uncluttered.
Turn on the dynamic color ramp only when you want that extra visual cue.
Alerts: Built-in alerts fire automatically at meaningful thresholds (Volatility ≥ 8 or ≤ 3), so you’ll never miss regime shifts, even if you step away.
Real-World Applications
Risk Management: Automatically adjust your stop-loss distances or position sizing based on the current volatility band.
Strategy Selection: Flip between range-trading and momentum strategies as the volatility regime changes.
Session Analysis: Pinpoint when during the day volatility typically ramps—perfect for doorway sessions like London opening or the US midday news spikes.
Bottom line: the Frahm Factor gives you one compact dashboard to see the pulse of the market—so you can make choices with conviction, dial your risk in real time, and never be caught off guard by sudden volatility shifts.
Logic Behind the Frahm Factor Indicator
24-Hour Rolling Window
On every intraday bar, we append that bar’s True Range (TR) and timestamp to two arrays.
We then prune any entries older than 24 hours, so the arrays always reflect exactly the last day of data.
Volatility Score (1–10)
We count how many of those 24 h TR values are less than or equal to the current bar’s TR.
Dividing by the total array size gives a percentile (0–1), which we scale and round into a 1–10 score.
Average Candle Size (ticks)
We sum all TR values in the same 24 h window, divide by array length to get the mean TR, then convert that price range into ticks.
Optionally, a green→yellow→red ramp highlights when average bar size is unusually small, medium or large versus its own 24 h history.
Color & Alerts
The Volatility cell flips green (1–3), yellow (4–6) or red (7–10) so you see regime shifts at a glance.
Built-in alertcondition calls fire when the score crosses your high (≥ 8) or low (≤ 3) thresholds.
Modularity
Everything—table location, which cells to show, dynamic coloring—is controlled by simple toggles, so you can strip it back or layer on extra visual cues as needed.
That’s the full recipe: a true 24 h look-back, a percentile-ranked volatility gauge, and a mean-bar-size meter, all wrapped into one compact dashboard.
Volume PercentileThis Pine Script indicator highlights bars where the current volume exceeds a configurable percentile threshold (e.g., 80th percentile) based on a rolling window of historical volume data.
🔍 Key Features:
Calculates a user-defined volume percentile (e.g., 75th, 80th, 90th) over a rolling window.
Marks candles where current volume is higher than the selected percentile.
Helps detect volume spikes, breakouts, or unusual activity.
Works directly on the main chart window for easier analysis.
🛠️ Inputs:
Window Length: Number of bars used to calculate the percentile (default = 20).
Percentile: The percentile threshold to trigger a high-volume signal (default = 80).
🖥️ Visualization:
Displays a red triangle marker below bars with volume above the selected percentile.

Double Top/Bottom DetectorDouble Top/Bottom Detector Indicator Description
Overview
The Double Top/Bottom Detector is a technical analysis tool designed to automatically identify and label potential double top and double bottom patterns on price charts. By combining pivot point detection with configurable height tolerance and pullback depth criteria, this indicator helps traders visually spot possible trend reversal zones without manual drawing or guesswork.
Key Features
• Pivot Point Identification
The indicator uses a symmetric window approach to find true highs and lows. A pivot high is confirmed only when a bar’s high exceeds the highs of a specified number of bars both before and after it. Likewise, a pivot low is established when a bar’s low is the lowest in its surrounding window.
• Double Top and Double Bottom Detection
– Height Tolerance: Ensures that the two pivot points forming the pattern are within a user-defined percentage of each other.
– Pullback Depth: Measures the drop (for a double top) or the rise (for a double bottom) between the two pivot points and confirms that it meets a minimum percentage threshold.
• Automatic Drawing and Labeling
When a valid double top is detected, a red line connects the two pivot highs and a “Double Top” label is centered above the line. For a double bottom, a green line connects the two pivot lows and a “Double Bottom” label appears below the midpoint.
• Pivot Visualization for Debugging
Small red and green triangles mark every detected pivot high and pivot low on the chart, making it easy to verify and fine-tune settings.
Parameters
Height Tolerance (%) – The maximum allowable percentage difference between the two pivot heights (default 2.0).
Pullback Minimum (%) – The minimum required percentage pullback (for tops) or rebound (for bottoms) between the two pivots (default 5.0).
Pivot Lookback – The number of bars to look back and forward for validating pivot points (default 5).
Window Length – The number of bars over which to compute pullback extrema, equal to twice the pivot lookback plus one (default derived from pivot lookback).
Usage Instructions
1. Copy the Pine Script code into TradingView’s editor and select version 6.
2. Adjust the parameters based on the asset’s volatility and timeframe. A larger lookback window yields fewer but more reliable pivots; tighter height tolerance produces more precise pattern matches.
3. Observe the chart for red and green triangles marking pivot highs and lows. When two qualifying pivots occur, the indicator draws a connecting line and displays a descriptive label.
4. To extend the number of visible historical lines and labels, increase the max\_lines\_count and max\_labels\_count settings in the indicator declaration.
Customization Ideas
• Add volume or moving average filters to reduce false signals.
• Encapsulate pivot logic into reusable functions for cleaner code.
• Incorporate alert conditions to receive notifications when new double top or bottom patterns form.
This indicator is well suited for medium- to long-term analysis and can be combined with risk management rules to enhance decision making.
Volume-Weighted Pivot BandsThe Volume-Weighted Pivot Bands are meant to be a dynamic, rolling pivot system designed to provide traders with responsive support and resistance levels that adapt to both price volatility and volume participation. Unlike traditional daily pivot levels, this tool recalculates levels bar-by-bar using a rolling window of volume-weighted averages, making it highly relevant for intraday traders, scalpers, swing traders, and algorithmic systems alike.
-- What This Indicator Does --
This tool calculates a rolling VWAP-based pivot level, and surrounds that central pivot with up to five upper bands (R1–R5) and five lower bands (S1–S5). These act as dynamic zones of potential resistance (R) and support (S), adapting in real time to price and volume changes.
Rather than relying on static session or daily data, this indicator provides continually evolving levels, offering more relevant levels during sideways action, trending periods, and breakout conditions.
-- How the Bands Are Calculated --
Pivot (VWAP Pivot):
The core of this system is a rolling Volume-Weighted Average Price, calculated over a user-defined window (default 20 bars). This ensures that each bar’s price impact is weighted by its volume, giving a more accurate view of fair value during the selected lookback.
Volume-Weighted Range (VW Range):
The highest high and lowest low over the same window are used to calculate the volatility range — this acts as a spread factor.
Support & Resistance Bands (S1–S5, R1–R5):
The bands are offset above and below the pivot using multiples of the VW Range:
R1 = Pivot + (VW Range × multiplier)
R2 = R1 + (VW Range × multiplier)
R3 = R2 + (VW Range x multiplier)
...
S1 = Pivot − (VW Range × multiplier)
S2 = S1 − (VW Range × multiplier)
S3 = S2 - (VW Range x multiplier)
...
You can control the multiplier manually (default is 0.25), to widen or tighten band spacing.
Smoothing (Optional):
To prevent erratic movements, you can optionally toggle on/off a simple moving average to the pivot line (default length = 20), providing a smoother trend base for the bands.
-- How to Use It --
This indicator can be used for:
Support and resistance identification:
Price often reacts to R1/S1, and the outer bands (R4/R5 or S4/S5) act as overshoot zones or strong reversal areas.
Trend context:
If price is respecting upper bands (R2–R3), the trend is likely bullish. If price is pressing into S3 or lower, it may indicate sustained selling pressure or a breakdown.
Volatility framing:
The distance between bands adjusts based on price range over the rolling window. In tighter markets, the bands compress — in volatile moves, they expand. This makes the indicator self-adaptive.
Mean reversion trades:
A move into R4/R5 or S4/S5 without continuation can be a sign of exhaustion — potential for reversal toward the pivot.
Alerting:
Built-in alerts are available for crosses of all major bands (R1–R5, S1–S5), enabling trade automation or scalp alerts with ease.
-- Visual Features --
Fuchsia Lines: Mark all Resistance (R1–R5) levels.
Lime Lines: Mark all Support (S1–S5) levels.
Gray Circle Line: Marks the rolling pivot (VWAP-based).
-- Customizable Settings --
Rolling Length: Number of bars used to calculate VWAP and VW Range.
Multiplier: Controls how wide the bands are spaced.
Smooth Pivot: Toggle on/off to smooth the central pivot.
Pivot Smoothing Length: Controls how many bars to average when smoothing is enabled.
Offset: Visually shift all bands forward/backward in time.
-- Why Use This Over Standard Pivots? --
Traditional pivots are based on previous session data and remain fixed. That’s useful for static setups, but may become irrelevant as price action evolves. In contrast:
This system updates every bar, adjusting to current price behavior.
It includes volume — a key feature missing from most static pivots.
It shows multiple bands, giving a full view of compression, breakout potential, or trend exhaustion.
-- Who Is This For? --
This tool is ideal for:
Day traders & scalpers who need relevant intraday levels.
Swing traders looking for evolving areas of confluence.
Algorithmic/systematic traders who rely on quantifiable, volume-aware support/resistance.
Traders on all assets: works on crypto, stocks, futures, forex — any chart that has volume.

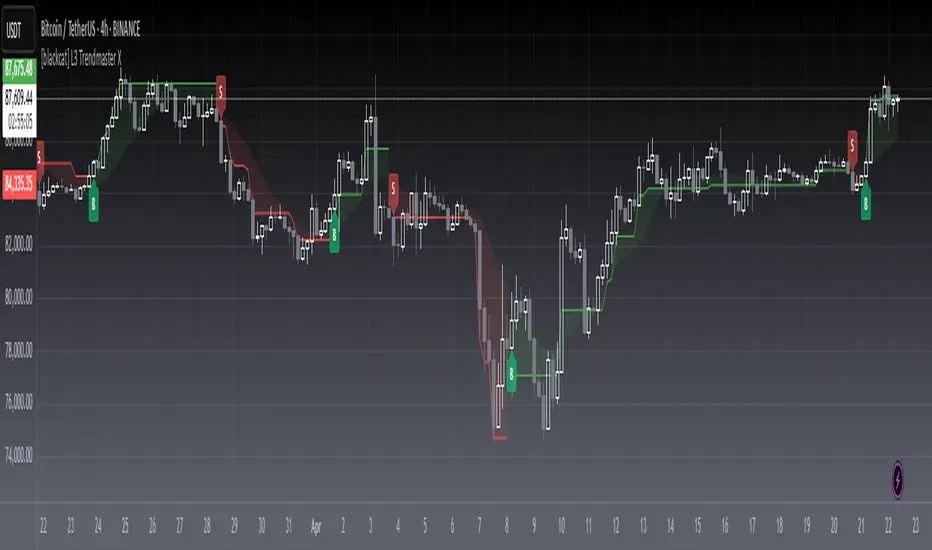
[blackcat] L3 Trendmaster XOVERVIEW
The L3 Trendmaster X is an advanced trend-following indicator meticulously crafted to assist traders in identifying and capitalizing on market trends. This sophisticated tool integrates multiple technical factors, including Average True Range (ATR), volume dynamics, and price spreads, to deliver precise buy and sell signals. By plotting dynamic trend bands directly onto the chart, it offers a comprehensive visualization of potential trend directions, enabling traders to make informed decisions swiftly and confidently 📊↗️.
FEATURES
Customizable Input Parameters: Tailor the indicator to match your specific trading needs with adjustable settings:
Trendmaster X Multiplier: Controls the sensitivity of the ATR-based levels.
Trendmaster X Period: Defines the period over which the ATR is calculated.
Window Length: Specifies the length of the moving window for standard deviation calculations.
Volume Averaging Length: Determines how many periods are considered for averaging volume.
Volatility Factor: Adjusts the impact of volatility on the trend bands.
Core Technical Metrics:
Dynamic Range: Measures the range between high and low prices within each bar.
Candle Body Size: Evaluates the difference between open and close prices.
Volume Average: Assesses the cumulative On-Balance Volume relative to the dynamic range.
Price Spread: Computes the standard deviation of the price ranges over a specified window.
Volatility Factor: Incorporates volatility into the calculation of trend bands.
Advanced Trend Bands Calculation:
Upper Level: Represents potential resistance levels derived from the ATR multiplier.
Lower Level: Indicates possible support levels using the same ATR multiplier.
High Band and Low Band: Dynamically adjust to reflect current trend directions, offering a clear view of market sentiment.
Visual Representation:
Plots distinct green and red trend lines representing bullish and bearish trends respectively.
Fills the area between these trend lines and the middle line for enhanced visibility.
Displays clear buy ('B') and sell ('S') labels on the chart for immediate recognition of trading opportunities 🏷️.
Alert System:
Generates real-time alerts when buy or sell conditions are triggered, ensuring timely action.
Allows customization of alert messages and frequencies to align with individual trading strategies 🔔.
HOW TO USE
Adding the Indicator:
Open your TradingView platform and navigate to the "Indicators" section.
Search for " L3 Trendmaster X" and add it to your chart.
Adjusting Settings:
Fine-tune the input parameters according to your preferences and trading style.
For example, increase the Trendmaster X Multiplier for higher sensitivity during volatile markets.
Decrease the Window Length for shorter-term trend analysis.
Monitoring Trends:
Observe the plotted trend bands and labels on the chart.
Look for buy ('B') labels at potential support levels and sell ('S') labels at resistance levels.
Setting Up Alerts:
Configure alerts based on the generated buy and sell signals.
Choose notification methods (e.g., email, SMS) and set alert frequencies to stay updated without constant monitoring 📲.
Combining with Other Tools:
Integrate the Trendmaster X with other technical indicators like Moving Averages or RSI for confirmation.
Utilize fundamental analysis alongside the indicator for a holistic approach to trading.
Backtesting and Optimization:
Conduct thorough backtests on historical data to evaluate performance.
Optimize parameters based on backtest results to enhance accuracy and reliability.
Real-Time Application:
Apply the optimized settings to live charts and monitor real-time signals.
Execute trades based on confirmed signals while considering risk management principles.
LIMITATIONS
Market Conditions: The indicator might produce false signals in highly volatile or sideways-trending markets due to increased noise and lack of clear direction 🌪️.
Complementary Analysis: Traders should use this indicator in conjunction with other analytical tools to validate signals and reduce the likelihood of false positives.
Asset-Specific Performance: Effectiveness can vary across different assets and timeframes; therefore, testing on diverse instruments is recommended.
NOTES
Data Requirements: Ensure adequate historical data availability for accurate calculations and reliable signal generation.
Demo Testing: Thoroughly test the indicator on demo accounts before deploying it in live trading environments to understand its behavior under various market scenarios.
Parameter Customization: Regularly review and adjust parameters based on evolving market conditions and personal trading objectives.
SYMPL Reversal BandsThis is an expansion of the Hybrid moving average. It uses the same hybrid moving code from the hybrid moving average script with an additional layer using the ta.hma function for some slight additional smoothing. Colors of the bands change dynamically based of the long and short hybrid moving averages running in the background. This can be really helpful in identifying periods to short bounces or long dips.
Below is the explanation of the hybrid moving average
Hybrid Moving Average Market Trend System - , designed to visualize market trends using a combination of three moving averages: FRAMA (Fractal Adaptive Moving Average), VIDYA (Variable Index Dynamic Average), and a Hamming windowed Volume-Weighted Moving Average (VWMA).
Key Features:
FRAMA Calculation:
FRAMA adapts to market volatility by dynamically adjusting its smoothing factor based on the fractal dimension of price movement. This allows it to be more responsive during trending periods while filtering out noise in sideways markets. The FRAMA is calculated for both short and long periods
VIDYA with CMO:
The VIDYA (Variable Index Dynamic Average) is based on a Chande Momentum Oscillator (CMO), which adjusts the smoothing factor dynamically depending on the momentum of the market. Higher momentum periods result in more responsive averages, while low momentum periods lead to smoother averages. Like FRAMA, VIDYA is calculated for both short and long periods.
Hamming Windowed VWMA:
This VWMA variation applies a Hamming window to smooth the weighting of volume across the calculation period. This method emphasizes central data points and reduces noise, making the VWMA more adaptive to volume fluctuations. The Hamming VWMA is calculated for short and long periods, offering another layer of adaptability to the hybrid moving average.
Hybrid Moving Averages:
Dynamic Coloring and Filling:
The script uses dynamic color transitions to visually distinguish between bullish and bearish conditions:

Hybrid Moving Average - Market TrendHybrid Moving Average Market Trend System - , designed to visualize market trends using a combination of three moving averages: FRAMA (Fractal Adaptive Moving Average), VIDYA (Variable Index Dynamic Average), and a Hamming windowed Volume-Weighted Moving Average (VWMA).
Key Features:
FRAMA Calculation:
FRAMA adapts to market volatility by dynamically adjusting its smoothing factor based on the fractal dimension of price movement. This allows it to be more responsive during trending periods while filtering out noise in sideways markets. The FRAMA is calculated for both short and long periods
VIDYA with CMO:
The VIDYA (Variable Index Dynamic Average) is based on a Chande Momentum Oscillator (CMO), which adjusts the smoothing factor dynamically depending on the momentum of the market. Higher momentum periods result in more responsive averages, while low momentum periods lead to smoother averages. Like FRAMA, VIDYA is calculated for both short and long periods.
Hamming Windowed VWMA:
This VWMA variation applies a Hamming window to smooth the weighting of volume across the calculation period. This method emphasizes central data points and reduces noise, making the VWMA more adaptive to volume fluctuations. The Hamming VWMA is calculated for short and long periods, offering another layer of adaptability to the hybrid moving average.
Hybrid Moving Averages:
Dynamic Coloring and Filling:
The script uses dynamic color transitions to visually distinguish between bullish and bearish conditions:

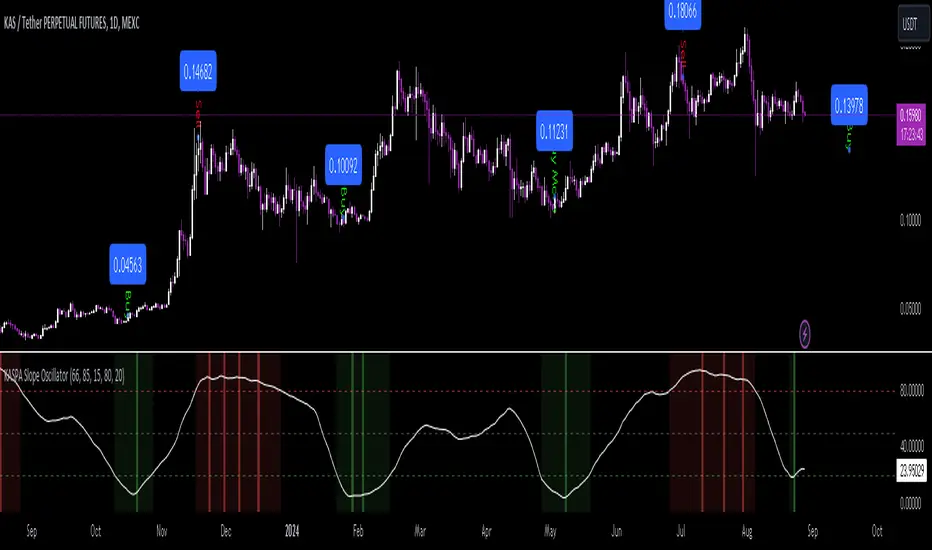
KASPA Slope OscillatorKASPA Slope Oscillator for analyzing KASPA on the 1D (daily) chart.
The indicator is plotted in a separate pane below the price chart and uses a mathematical approach to calculate and visualize the momentum or "slope" of KASPA's price movements.
Input Parameters:
Slope Window (days):
Defines the period (66 days by default) over which the slope is calculated.
Normalization Window (days):
The window size (85 days) for normalizing the slope values between 0 and 100.
Smoothing Period:
The number of days (15 days) over which the slope values are smoothed to reduce noise.
Overbought and Oversold Levels:
Threshold levels set at 80 (overbought) and 20 (oversold), respectively.
Calculation of the Slope:
Logarithmic Price Calculation:
Converts the close price of KASPA into a logarithmic scale to account for exponential growth or decay.
Rolling Slope:
Computes the rate of change in logarithmic prices over the defined slope window.
Normalization:
The slope is normalized between 0 and 100, allowing easier identification of extreme values.
Smoothing and Visualization:
Smoothing the Slope:
A Simple Moving Average (SMA) is applied to the normalized slope for the specified smoothing period.
Plotting the Oscillator:
The smoothed slope is plotted on the oscillator chart. Horizontal lines indicate overbought (80), oversold (20), and the mid-level (50).
Background Color Indications:
Background colors (red or green) indicate when the slope crosses above the overbought or below the oversold levels, respectively, signaling potential buy or sell conditions.
Detection of Local Maxima and Minima:
The code identifies local peaks (maxima) above the overbought level and troughs (minima) below the oversold level.
Vertical background lines are highlighted in red or green at these points, signaling potential reversals.
Short Summary:
The oscillator line fluctuates between 0 and 100, representing the normalized momentum of the price.
Red background areas indicate periods when the oscillator is above the overbought level (80), suggesting a potential overbought condition or a sell signal.
Green background areas indicate periods when the oscillator is below the oversold level (20), suggesting a potential oversold condition or a buy signal.
The vertical lines on the background mark local maxima and minima where price reversals may occur.
(I also want to thank @ForgoWork for optimizing visuality and cleaning up the source code)
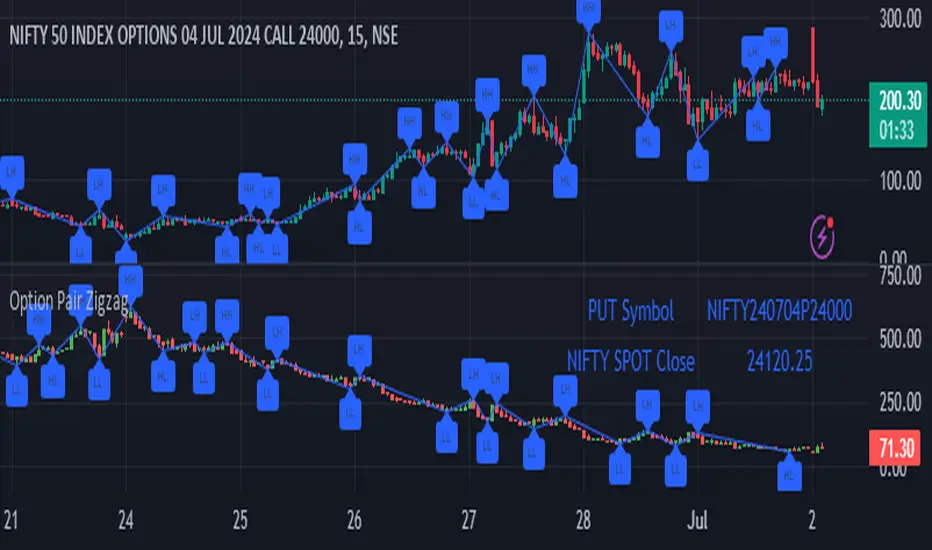
Option Pair ZigzagOptions Pair Zigzag:
Though we can split the chart window and view multiple charts, this indicator is useful when we view options charts.
How this indicator works:
The indicator works in non-overlay mode.
The indicator will find other option pair symbol and load it’s chart in indicator window. It will also draw a zigzag on both the charts. It will also fetch the SPOT symbol and display SPOT Close price of latest candle.
Useful information:
A. Support resistance: Higher High (HH) and Lower Low (LL) markings can be treated as strong support and or resistance and LH, HL markings can be treated as weak support and or resistance.
B. Trend identification: Easy identification of trend based on trend lines and trend markings i.e. Higher High (HH), Lower Low (LL), Lower High (LH), Higher Low (HL)
C. Use of Rate of change (ROC )– Labels drawn on swing points are equipped with ROC% between swing points. ROC% between Call and Put option charts can be compared and used to identify strong and weak moves.
Example:
1. User loads a call option chart of ‘NIFTY240620C23500’ (NIFTY 50 INDEX OPTIONS 20 JUN 2024 CALL 23500)
2. Since user has selected CALL Option, Indicator rules/logic will find PUT Option symbol of same strike and expiry
3. PUT Option chart would then shown in the indicator window
4. Draw zigzag on both the charts
5. Plot labels on both the charts
6. Labels are equipped with a tooltip showing rate of change between 2 pivot points
Input Parameters:
Left bars – Parameter required for plotting zigzag
Right bars – Parameter required for plotting zigzag
Plot HHLL Labels – Enable/disable plotting of labels
Use cases:
Refer to chart snapshots:
1. Buy Call Option or Sell Put Option - How one can trade on formation of a consolidation range
2. Breakdown of Swing structure - One can observe Swing structure (Zigzag) formed on a SPOT chart and trade on break of swing structure
3. Triangle formation - Observe the patterns formed on the SPOT chart and trade either Call or Put options. Example snapshot shows trade based on triangle pattern
Chart Snapshot:
One can split chart window and load base symbol chart which will help to review bases symbol and options chart at the same time.
Buy Call Option or Sell Put Option
Breakdown of Swing structure
Triangle formation
Persistent Homology Based Trend Strength OscillatorPersistent Homology Based Trend Strength Oscillator
The Persistent Homology Based Trend Strength Oscillator is a unique and powerful tool designed to measure the persistence of market trends over a specified rolling window. By applying the principles of persistent homology, this indicator provides traders with valuable insights into the strength and stability of uptrends and downtrends, helping to inform better trading decisions.
What Makes This Indicator Original?
This indicator's originality lies in its application of persistent homology , a method from topological data analysis, to financial markets. Persistent homology examines the shape and features of data across multiple scales, identifying patterns that persist as the scale changes. By adapting this concept, the oscillator tracks the persistence of uptrends and downtrends in price data, offering a novel approach to trend analysis.
Concepts Underlying the Calculations:
Persistent Homology: This method identifies features such as clusters, holes, and voids that persist as the scale changes. In the context of this indicator, it tracks the duration and stability of price trends.
Rolling Window Analysis: The oscillator uses a specified window size to calculate the average length of uptrends and downtrends, providing a dynamic view of trend persistence over time.
Threshold-Based Trend Identification: It differentiates between uptrends and downtrends based on specified thresholds for price changes, ensuring precision in trend detection.
How It Works:
The oscillator monitors consecutive changes in closing prices to identify uptrends and downtrends.
An uptrend is detected when the closing price increase exceeds a specified positive threshold.
A downtrend is detected when the closing price decrease exceeds a specified negative threshold.
The lengths of these trends are recorded and averaged over the chosen window size.
The Trend Persistence Index is calculated as the difference between the average uptrend length and the average downtrend length, providing a measure of trend persistence.
How Traders Can Use It:
Identify Trend Strength: The Trend Persistence Index offers a clear measure of the strength and stability of uptrends and downtrends. A higher value indicates stronger and more persistent uptrends, while a lower value suggests stronger and more persistent downtrends.
Spot Trend Reversals: Significant shifts in the Trend Persistence Index can signal potential trend reversals. For instance, a transition from positive to negative values might indicate a shift from an uptrend to a downtrend.
Confirm Trends: Use the Trend Persistence Index alongside other technical indicators to confirm the strength and duration of trends, enhancing the accuracy of your trading signals.
Manage Risk: Understanding trend persistence can help traders manage risk by identifying periods of high trend stability versus periods of potential volatility. This can be crucial for timing entries and exits.
Example Usage:
Default Settings: Start with the default settings to get a feel for the oscillator’s behavior. Observe how the Trend Persistence Index reacts to different market conditions.
Adjust Thresholds: Fine-tune the positive and negative thresholds based on the asset's volatility to improve trend detection accuracy.
Combine with Other Indicators: Use the Persistent Homology Based Trend Strength Oscillator in conjunction with other technical indicators such as moving averages, RSI, or MACD for a comprehensive analysis.
Backtesting: Conduct backtesting to see how the oscillator would have performed in past market conditions, helping you to refine your trading strategy.
mathLibrary "math"
It's a library of discrete aproximations of a price or Series float it uses Fourier Discrete transform, Laplace Discrete Original and Modified transform and Euler's Theoreum for Homogenus White noice operations. Calling functions without source value it automatically take close as the default source value.
Here is a picture of Laplace and Fourier approximated close prices from this library:
Copy this indicator and try it yourself:
import AutomatedTradingAlgorithms/math/1 as math
//@version=5
indicator("Close Price with Aproximations", shorttitle="Close and Aproximations", overlay=false)
// Sample input data (replace this with your own data)
inputData = close
// Plot Close Price
plot(inputData, color=color.blue, title="Close Price")
ltf32_result = math.LTF32(a=0.01)
plot(ltf32_result, color=color.green, title="LTF32 Aproximation")
fft_result = math.FFT()
plot(fft_result, color=color.red, title="Fourier Aproximation")
wavelet_result = math.Wavelet()
plot(wavelet_result, color=color.orange, title="Wavelet Aproximation")
wavelet_std_result = math.Wavelet_std()
plot(wavelet_std_result, color=color.yellow, title="Wavelet_std Aproximation")
DFT3(xval, _dir)
Discrete Fourier Transform with last 3 points
Parameters:
xval (float) : Source series
_dir (int) : Direction parameter
Returns: Aproxiated source value
DFT2(xval, _dir)
Discrete Fourier Transform with last 2 points
Parameters:
xval (float) : Source series
_dir (int) : Direction parameter
Returns: Aproxiated source value
FFT(xval)
Fast Fourier Transform once. It aproximates usig last 3 points.
Parameters:
xval (float) : Source series
Returns: Aproxiated source value
DFT32(xval)
Combined Discrete Fourier Transforms of DFT3 and DTF2 it aproximates last point by first
aproximating last 3 ponts and than using last 2 points of the previus.
Parameters:
xval (float) : Source series
Returns: Aproxiated source value
DTF32(xval)
Combined Discrete Fourier Transforms of DFT3 and DTF2 it aproximates last point by first
aproximating last 3 ponts and than using last 2 points of the previus.
Parameters:
xval (float) : Source series
Returns: Aproxiated source value
LFT3(xval, _dir, a)
Discrete Laplace Transform with last 3 points
Parameters:
xval (float) : Source series
_dir (int) : Direction parameter
a (float) : laplace coeficient
Returns: Aproxiated source value
LFT2(xval, _dir, a)
Discrete Laplace Transform with last 2 points
Parameters:
xval (float) : Source series
_dir (int) : Direction parameter
a (float) : laplace coeficient
Returns: Aproxiated source value
LFT(xval, a)
Fast Laplace Transform once. It aproximates usig last 3 points.
Parameters:
xval (float) : Source series
a (float) : laplace coeficient
Returns: Aproxiated source value
LFT32(xval, a)
Combined Discrete Laplace Transforms of LFT3 and LTF2 it aproximates last point by first
aproximating last 3 ponts and than using last 2 points of the previus.
Parameters:
xval (float) : Source series
a (float) : laplace coeficient
Returns: Aproxiated source value
LTF32(xval, a)
Combined Discrete Laplace Transforms of LFT3 and LTF2 it aproximates last point by first
aproximating last 3 ponts and than using last 2 points of the previus.
Parameters:
xval (float) : Source series
a (float) : laplace coeficient
Returns: Aproxiated source value
whitenoise(indic_, _devided, minEmaLength, maxEmaLength, src)
Ehler's Universal Oscillator with White Noise, without extra aproximated src.
It uses dinamic EMA to aproximate indicator and thus reducing noise.
Parameters:
indic_ (float) : Input series for the indicator values to be smoothed
_devided (int) : Divisor for oscillator calculations
minEmaLength (int) : Minimum EMA length
maxEmaLength (int) : Maximum EMA length
src (float) : Source series
Returns: Smoothed indicator value
whitenoise(indic_, dft1, _devided, minEmaLength, maxEmaLength, src)
Ehler's Universal Oscillator with White Noise and DFT1.
It uses src and sproxiated src (dft1) to clearly define white noice.
It uses dinamic EMA to aproximate indicator and thus reducing noise.
Parameters:
indic_ (float) : Input series for the indicator values to be smoothed
dft1 (float) : Aproximated src value for white noice calculation
_devided (int) : Divisor for oscillator calculations
minEmaLength (int) : Minimum EMA length
maxEmaLength (int) : Maximum EMA length
src (float) : Source series
Returns: Smoothed indicator value
smooth(dft1, indic__, _devided, minEmaLength, maxEmaLength, src)
Smoothing source value with help of indicator series and aproximated source value
It uses src and sproxiated src (dft1) to clearly define white noice.
It uses dinamic EMA to aproximate src and thus reducing noise.
Parameters:
dft1 (float) : Value to be smoothed.
indic__ (float) : Optional input for indicator to help smooth dft1 (default is FFT)
_devided (int) : Divisor for smoothing calculations
minEmaLength (int) : Minimum EMA length
maxEmaLength (int) : Maximum EMA length
src (float) : Source series
Returns: Smoothed source (src) series
smooth(indic__, _devided, minEmaLength, maxEmaLength, src)
Smoothing source value with help of indicator series
It uses dinamic EMA to aproximate src and thus reducing noise.
Parameters:
indic__ (float) : Optional input for indicator to help smooth dft1 (default is FFT)
_devided (int) : Divisor for smoothing calculations
minEmaLength (int) : Minimum EMA length
maxEmaLength (int) : Maximum EMA length
src (float) : Source series
Returns: Smoothed src series
vzo_ema(src, len)
Volume Zone Oscillator with EMA smoothing
Parameters:
src (float) : Source series
len (simple int) : Length parameter for EMA
Returns: VZO value
vzo_sma(src, len)
Volume Zone Oscillator with SMA smoothing
Parameters:
src (float) : Source series
len (int) : Length parameter for SMA
Returns: VZO value
vzo_wma(src, len)
Volume Zone Oscillator with WMA smoothing
Parameters:
src (float) : Source series
len (int) : Length parameter for WMA
Returns: VZO value
alma2(series, windowsize, offset, sigma)
Arnaud Legoux Moving Average 2 accepts sigma as series float
Parameters:
series (float) : Input series
windowsize (int) : Size of the moving average window
offset (float) : Offset parameter
sigma (float) : Sigma parameter
Returns: ALMA value
Wavelet(src, len, offset, sigma)
Aproxiates srt using Discrete wavelet transform.
Parameters:
src (float) : Source series
len (int) : Length parameter for ALMA
offset (simple float)
sigma (simple float)
Returns: Wavelet-transformed series
Wavelet_std(src, len, offset, mag)
Aproxiates srt using Discrete wavelet transform with standard deviation as a magnitude.
Parameters:
src (float) : Source series
len (int) : Length parameter for ALMA
offset (float) : Offset parameter for ALMA
mag (int) : Magnitude parameter for standard deviation
Returns: Wavelet-transformed series
LaplaceTransform(xval, N, a)
Original Laplace Transform over N set of close prices
Parameters:
xval (float) : series to aproximate
N (int) : number of close prices in calculations
a (float) : laplace coeficient
Returns: Aproxiated source value
NLaplaceTransform(xval, N, a, repeat)
Y repetirions on Original Laplace Transform over N set of close prices, each time N-k set of close prices
Parameters:
xval (float) : series to aproximate
N (int) : number of close prices in calculations
a (float) : laplace coeficient
repeat (int) : number of repetitions
Returns: Aproxiated source value
LaplaceTransformsum(xval, N, a, b)
Sum of 2 exponent coeficient of Laplace Transform over N set of close prices
Parameters:
xval (float) : series to aproximate
N (int) : number of close prices in calculations
a (float) : laplace coeficient
b (float) : second laplace coeficient
Returns: Aproxiated source value
NLaplaceTransformdiff(xval, N, a, b, repeat)
Difference of 2 exponent coeficient of Laplace Transform over N set of close prices
Parameters:
xval (float) : series to aproximate
N (int) : number of close prices in calculations
a (float) : laplace coeficient
b (float) : second laplace coeficient
repeat (int) : number of repetitions
Returns: Aproxiated source value
N_divLaplaceTransformdiff(xval, N, a, b, repeat)
N repetitions of Difference of 2 exponent coeficient of Laplace Transform over N set of close prices, with dynamic rotation
Parameters:
xval (float) : series to aproximate
N (int) : number of close prices in calculations
a (float) : laplace coeficient
b (float) : second laplace coeficient
repeat (int) : number of repetitions
Returns: Aproxiated source value
LaplaceTransformdiff(xval, N, a, b)
Difference of 2 exponent coeficient of Laplace Transform over N set of close prices
Parameters:
xval (float) : series to aproximate
N (int) : number of close prices in calculations
a (float) : laplace coeficient
b (float) : second laplace coeficient
Returns: Aproxiated source value
NLaplaceTransformdiffFrom2(xval, N, a, b, repeat)
N repetitions of Difference of 2 exponent coeficient of Laplace Transform over N set of close prices, second element has for 1 higher exponent factor
Parameters:
xval (float) : series to aproximate
N (int) : number of close prices in calculations
a (float) : laplace coeficient
b (float) : second laplace coeficient
repeat (int) : number of repetitions
Returns: Aproxiated source value
N_divLaplaceTransformdiffFrom2(xval, N, a, b, repeat)
N repetitions of Difference of 2 exponent coeficient of Laplace Transform over N set of close prices, second element has for 1 higher exponent factor, dynamic rotation
Parameters:
xval (float) : series to aproximate
N (int) : number of close prices in calculations
a (float) : laplace coeficient
b (float) : second laplace coeficient
repeat (int) : number of repetitions
Returns: Aproxiated source value
LaplaceTransformdiffFrom2(xval, N, a, b)
Difference of 2 exponent coeficient of Laplace Transform over N set of close prices, second element has for 1 higher exponent factor
Parameters:
xval (float) : series to aproximate
N (int) : number of close prices in calculations
a (float) : laplace coeficient
b (float) : second laplace coeficient
Returns: Aproxiated source value
Machine Learning: Trend Pulse⚠️❗ Important Limitations: Due to the way this script is designed, it operates specifically under certain conditions:
Stocks & Forex : Only compatible with timeframes of 8 hours and above ⏰
Crypto : Only works with timeframes starting from 4 hours and higher ⏰
❗Please note that the script will not work on lower timeframes.❗
Feature Extraction : It begins by identifying a window of past price changes. Think of this as capturing the "mood" of the market over a certain period.
Distance Calculation : For each historical data point, it computes a distance to the current window. This distance measures how similar past and present market conditions are. The smaller the distance, the more similar they are.
Neighbor Selection : From these, it selects 'k' closest neighbors. The variable 'k' is a user-defined parameter indicating how many of the closest historical points to consider.
Price Estimation : It then takes the average price of these 'k' neighbors to generate a forecast for the next stock price.
Z-Score Scaling: Lastly, this forecast is normalized using the Z-score to make it more robust and comparable over time.
Inputs:
histCap (Historical Cap) : histCap limits the number of past bars the script will consider. Think of it as setting the "memory" of model—how far back in time it should look.
sampleSpeed (Sampling Rate) : sampleSpeed is like a time-saving shortcut, allowing the script to skip bars and only sample data points at certain intervals. This makes the process faster but could potentially miss some nuances in the data.
winSpan (Window Size) : This is the size of the "snapshot" of market data the script will look at each time. The window size sets how many bars the algorithm will include when it's measuring how "similar" the current market conditions are to past conditions.
All these variables help to simplify and streamline the k-NN model, making it workable within limitations. You could see them as tuning knobs, letting you balance between computational efficiency and predictive accuracy.
Relative slopeRelative slope metric
Description:
I was in need to create a simple, naive and elegant metric that was able to tell how strong is the trend in a given rolling window. While abstaining from using more complicated and arguably more precise approaches, I’ve decided to use Linearly Weighted Linear Regression slope for this goal. Outright values are useful, but the problem was that I wasn’t able to use it in comparative analysis, i.e between different assets & different resolutions & different window sizes, because obviously the outputs are scale-variant.
Here is the asset-agnostic, resolution-agnostic and window size agnostic version of the metric.
I made it asset agnostic & resolution agnostic by including spread information to the formula. In our case it's weighted stdev over differenced data (otherwise we contaminate the spread with the trend info). And I made it window size agnostic by adding a non-linear relation of length to the output, so finally it will be aprox in (-1, 1) interval, by taking square root of length, nothing fancy. All these / 2 and * 2 in unexpected places all around the formula help us to return the data to it’s natural scale while keeping the transformations in place.
Peace TV
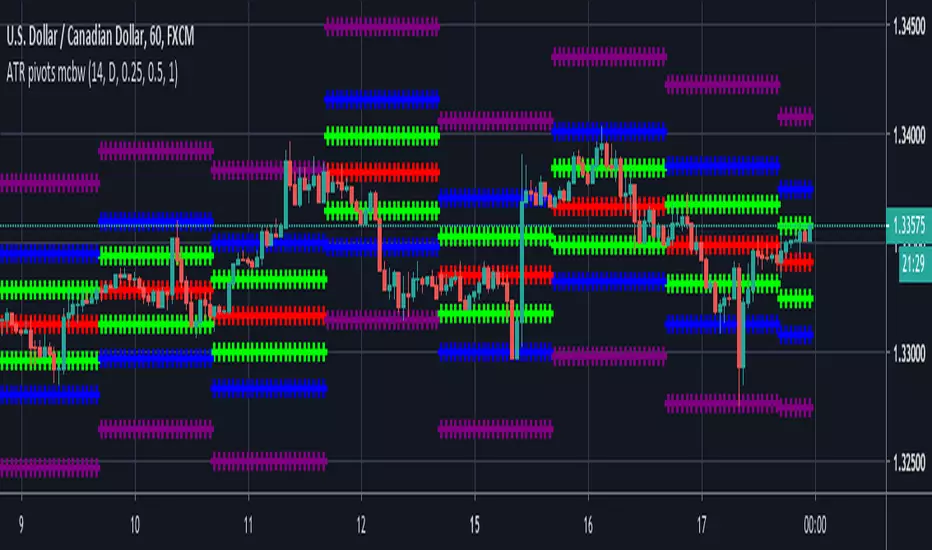
ATR based Pivots mcbwHey everyone this is an exciting new script I have prepared for you.
I was reading an old forex bulletin article some time ago when I came across this: solar.murty.net (or you can download the full bulletin with lots of other good articles here: www.forexfactory.com).
You can already buy this for metatrader (www.mql5.com) so I figured to make it for free for tradingview.
This bulletin suggested that you can reasonably predict daily volatility by adding or subtracting multiples of the daily ATR to the daily opening. Using this you can choose multiples to use as price targets and alternatively as stop losses. For example, if you already have a sense of market direction you can buy at market open place a stop loss at - 1 daily ATR and a profit target at + 3 ATRs for a risk to reward ratio of 3. If you are looking for smaller/quicker moves with a ratio of 3 you can have a stop loss at -0.25 ATR and a take profit at +0.75 ATR.
Alternatively this article also suggests to use this method to catch volatility breakouts. If price is higher than the + 1 ATR area then you can safely assume it will be going to the +2 ATR area so you can put a buy stop at + 1 ATR with a profit target at + 2 ATR with a stop loss at +0.5 ATR to catch a volatility breakout with a risk to reward ratio of 2!
Even further there are methods that you can use with ATRs of multiple window sizes, for example by opening two copies of this indicator and measuring recent volatility with a 1 week window and long term volatility within a 1 month window. If the short term volatility is crossing the long term volatility then there is a high probability chance that even more price movement will occur.
However I have found that this method is good for more than daily volatility , it can also be used to measure weekly volatility , and monthly volatility and use these multiples as good long term price targets.
To select if you want daily, weekly, or monthly values of the ATR of volatility you're using go to the settings and click on the options in the "Opening period". The default window of the ATR here is 14 periods, but you can change this if you want to in "ATR period". Most importantly you are able to select which multiples of the ATR you would like to use in the settings in "ATR multiple 1" which is the green line, "ATR multiple 2" which is the blue line, and "ATR multiple 3" which is the purple line. You can select any values you want to put in these, the choice of 0.25, 0.5, and 1 is not special, some people use fibonacci numbers here or simply 0.33, 0.66, and 0.99.
Repainting issue: This script uses the daily value of the Average True Range (ATR), which measures the volatility that is happening today. If price becomes more volatile then the value of the ATR can increase throughout the day, but it can never decrease. What this means is that the ATR based pivots are able to expand away from the opening price, which should not affect the trades that you take based on these areas. If you base your take profit on one of these ATR multiples and the daily volatility increase this means that your take profit area will be closer to your entry than the ATR multiple. Meaning that your trades will be more conservative.
While this all may sound very technical it is super intuitive, throw this on your chart and play around with it :)
Happy trading!
Volatility Value BandsThis indicator is a modern adaptation of Mark Helweg's original Value Charts concept, focused on visually displaying volatility zones and "extreme value" areas directly on the price chart. It does not replicate the original work but draws inspiration from the logic of normalizing price by volatility to highlight statistically stretched regions.
1. Introduction
This study displays three lines directly on the chart:
- a central reference line (base),
- an upper overvaluation band,
- and a lower undervaluation band.
The bands are calculated from the relationship between price, moving average, and volatility (via true range/ATR), following Mark Helweg's Value Charts concept but with a custom implementation and adjustable parameters for different assets and timeframes. This allows objectively visualizing when price is in a statistically extended region relative to its recent behavior.
2. Key Features
- Volatility-normalized base
The indicator converts price deviation into "value units" using a combination of moving average and smoothed volatility (true range/ATR), making levels comparable across different assets and time horizons.
- Auto-adjusting limits (optional)
An automatic mode can calculate upper and lower limits from recent value unit extremes, using a configurable sampling window and percentile, allowing bands to adapt to the current volatility regime without manual recalibration.
- Direct plot on price chart
The three lines (central, upper, and lower) are drawn directly on the main asset chart (`overlay`), making it easy to read context: it's clear when price "touches" or breaks the volatility bands without switching to a separate pane.
- Flexible parameters
Users can control:
- base moving average period (length)
- volatility factor (manual or automatic)
- independent windows for volatility and limits calculation
- limits mode (auto or manual) and percentile used
This allows adapting behavior to different markets (stocks, indices, forex, crypto).
3. How to Use
- Basic interpretation
- When price approaches or exceeds the upper band, it indicates a statistically overvalued zone where the asset is stretched upward relative to recent volatility.
- When price approaches or exceeds the lower band, it indicates a statistically undervalued zone.
- The central line serves as a reference for recent "average value," derived from the base moving average.
- Recommended initial setup
- Choose the Value Chart period (e.g., 144 bars) for the base.
- Enable automatic limits mode for coherent bands matching the asset's volatility.
- Adjust the limits window and percentile for tighter bands (more signals) or wider bands (fewer but more extreme).
- Best practices
- Use bands as context filters, not standalone buy/sell signals. Combine with trend, market structure, or other confirmation indicators.
- Avoid decisions solely because price touched a band; in strong trends, price can "walk the edge" for extended periods.
- Always follow TradingView community rules when publishing: clearly state in the description that the study is "inspired by Mark Helweg's Value Charts concept," without claiming official status, reproducing proprietary code, or violating copyrights.

Cold Brew Ranges🧭 Core Logic and Calculation
The fundamental logic for each range (OR and CR) is identical:
Time Definition: Each range is defined by a specific Start Time and a fixed 30-second duration. The timestamp function, using the "America/New_York" time zone, is used to calculate the exact start time in Unix milliseconds for the current day.
Example: t0200 = timestamp(TZ, yC, mC, dC, 2, 0, 0) sets the start time for the 02:00 OR to 2:00:00 AM NY time.
Range Data Collection: The indicator uses the request.security_lower_tf() function to collect the High (hArr) and Low (lArr) prices of all bars that fall within the defined 30-second window, using a user-specified, sub-chart-timeframe (openrangetime, defaulted to "1" second, "30S", or "5" minutes). This ensures high precision in capturing the exact high and low during the 30-second window.
High/Low Determination: It iteratively finds the absolute highest price (OR_high) and the absolute lowest price (OR_low) recorded by the bars during that 30-second window.
Range Locking: Once the current chart bar's time (lastTs) passes the 30-second End Time (tEnd), the High and Low are locked (OR_locked = true), meaning the range calculation is complete for the day.
Drawing: Upon locking, the range is drawn on the chart using line.new for the High, Low, and Equilibrium, and box.new for the shaded fill. The lines are extended to a subsequent time anchor point (e.g., the 02:00 OR is extended to 08:20, the 09:30 OR is extended to 16:00).
Equilibrium (EQ): This is calculated as the simple average (midpoint) of the High and Low of the range.
EQ=
2
OR_High+OR_Low
⏰ Defined Trading Ranges
The indicator defines and tracks the following specific 30-second ranges:
Range Name Type Start Time (NY) Line Extension End Time (NY) Common Market Context
02:00 OR Opening 02:00:00 08:20:00 Asian/European Market Overlap
08:20 OR Opening 08:20:00 16:00:00 Pre-New York Open
09:30 OR Opening 09:30:00 16:00:00 New York Stock Exchange Open (Most significant OR)
18:00 OR Opening 18:00:00 20:00:00 Futures Market Open (Sunday/Monday)
20:00 OR Opening 20:00:00 Next Day's session start Asian Session Start
15:50 CR Closing 15:50:00 20:00:00 New York Close Range
⚙️ Key User Inputs and Customization
The script offers extensive control over which ranges are displayed and how they are visualized:
Range Time & History
openrangetime: Sets the sub-timeframe (e.g., "1" for 1 second) used to calculate the precise High/Low of the 30-second range. Crucial for accuracy.
showHistory: A toggle to show the ranges from previous days (up to a histCap of 50 days).
Range Toggles and Styling
On/Off Toggles: Independent input.bool (e.g., OR_0200_on) to enable or disable the display of each individual range.
Colors & Width: Separate color and width inputs for the High/Low lines (hlC), the Equilibrium line (eqC), and the background fill (fillC) for each range.
Line Styles: Global inputs for the line styles of High/Low (lineStyleInput) and Equilibrium (eqLineStyleInput) lines (Solid, Dotted, or Dashed).
showFill: Global toggle to enable the shaded background box that highlights the area between the High and Low.
Extensions
The script calculates and plots extensions (multiples of the initial range) above the High and below the Low.
showExt: Toggles the visibility of the extension lines.
useRangeMultiples: If true, the step size for each extension level is equal to the initial range size:
Step=Range=OR_High−OR_Low
If false, the step size is a fixed value defined by stepPts (e.g., 60.0 points, which is a common value for NQ futures).
stepCnt: Determines how many extension levels (multiples) are drawn above and below the range (default is 10).
📈 Trading Strategy Implications
The Cold Brew Ranges indicator is a tool for session-based support and resistance and range breakout/reversal strategies.
Key Support/Resistance: The High and Low of these defined opening ranges often act as strong, predefined price levels. Traders look for price rejection off these boundaries or a breakout with conviction.
Equilibrium (Midpoint): The EQ often represents a fair value for that specific session's opening. Movements away from it are seen as opportunities, and a return to it is common.
Extensions: The range extensions serve as potential profit targets or stronger, layered support/resistance levels if the market trends aggressively after the opening range is set.
The core idea is that the activity in the first 30 seconds of a significant trading session (like the NYSE or a market session open) sets a bias and initial boundary for the trading period that follows.

RSI Profile [Kodexius]RSI Profile is an advanced technical indicator that turns the classic RSI into a distribution profile instead of a single oscillating line. Rather than only showing where the RSI is at the current bar, it displays where the RSI has spent most of its time or most of its volume over a user defined lookback period.
The script builds a histogram of RSI values between 0 and 100, splits that range into configurable bins, and then projects the result to the right side of the chart. This gives you a clear visual representation of the RSI structure, including the Point of Control (POC), the Value Area High (VAH), and the Value Area Low (VAL). The POC marks the RSI level with the highest activity, while VAH and VAL bracket the percentage based value area around it.
By combining standard RSI, a distribution profile, and value area logic, this tool lets you study RSI behavior statistically instead of only bar by bar. You can immediately see whether the current RSI reading is located inside the dominant zone, extended above it, or depressed below it, and whether the recent regime has been biased toward overbought, oversold, or neutral territory. This is particularly useful for swing traders, mean reversion systems, and anyone who wants to integrate RSI context into a more profile oriented workflow.
🔹 Features
1. RSI-Based Distribution Profile
-Builds a histogram of RSI values between 0 and 100.
-The RSI range is divided into a user-defined number of bins (e.g., 30 bins).
-Each bin represents a band of RSI values, such as 0–3.33, 3.33–6.66, ..., 96.66–100.
-For each bar in the lookback period, the script:
-Finds which bin the RSI value belongs to
Adds either:
-1.0 → if using time/frequency
-volume → if using volume-weighted RSI distribution
This creates a clear profile of where RSI has been concentrated over the chosen lookback window.
2. Time / Volume Weighting Mode
Under Profile Settings, you can choose:
-Weight by Volume = false
→ Profile is built using time spent at each RSI level (frequency).
-Weight by Volume = true
→ Profile is built using volume traded at each RSI level.
This flexibility allows you to decide whether you want:
-A pure momentum structure (time spent at each RSI)
-Or a participation-weighted structure (where higher-volume zones are emphasized)
3. Configurable Lookback & Resolution
-Profile Lookback: number of historical bars to analyze.
-Number of Bins: controls the resolution of the histogram:
Fewer bins → smoother, fewer gaps
More bins → more detail, but potentially more visual sparsity
-Profile Width (Bars): defines how wide the histogram extends into the future (visually), converted into time using average bar duration.
This provides a balance between performance, clarity, and visual density.
4. Value Area, POC, VAH, VAL
The script computes:
-POC (Point of Control)
→ The RSI bin with the highest total value (time or volume).
-Value Area (VA)
→ The range of RSI bins that contain a user-specified percentage of total activity (e.g., 70%).
-VAH & VAL
→ Upper and lower RSI boundaries of this Value Area.
These are then drawn as horizontal lines and labeled:
-POC line and label
-VAH line and label
-VAL line and label
This gives you a profile-style view similar to classical volume profile, but entirely on the RSI axis.
5. Color Coding & Visual Design
The histogram bars (boxes) are colored using a smart scheme:
-Below 30 RSI → Oversold zone, uses the Oversold Color (default: green).
-Above 70 RSI → Overbought zone, uses the Overbought Color (default: red).
-Between 30 and 70 RSI → Neutral zone, uses a gradient between:
A soft blue at lower mid levels
A soft orange at higher mid levels
Additional styling:
-POC bin is highlighted in bright yellow.
-Bins inside the Value Area → lower transparency (more solid).
-Bins outside the Value Area → higher transparency (faded).
This makes it easy to visually distinguish:
-Core RSI activity (VA)
-Extremes (oversold/overbought)
-The single dominant zone (POC)
🔹 Calculations
This section summarizes the core logic behind the script and highlights the main building blocks that power the profile.
1. Profile Structure and Bin Initialization
A custom Profile type groups together configuration, bins and drawing objects. During initialization, the script splits the 0 to 100 RSI range into evenly spaced bins, each represented by a Bin record:
method initBins(Profile p) =>
p.bins := array.new()
float step = 100.0 / p.binCount
for i = 0 to p.binCount - 1
float low = i * step
float high = (i + 1) * step
p.bins.push(Bin.new(low, high, 0.0, box(na)))
2. Filling the Profile Over the Lookback Window
On the last bar, the script clears previous drawings and walks backward through the selected lookback window. For each historical bar, it reads the RSI and volume series and feeds them into the profile:
if barstate.islast
myProfile.reset()
int start = math.max(0, bar_index - lookback)
int end = bar_index
for i = 0 to (end - start)
float r = rsi
float v = volume
if not na(r)
myProfile.add(r, v)
The add method converts each RSI value into a bin index and accumulates either a frequency count or the bar volume, depending on the chosen mode:
method add(Profile p, float rsiValue, float volumeValue) =>
int idx = int(rsiValue / (100.0 / p.binCount))
if idx >= p.binCount
idx := p.binCount - 1
if idx < 0
idx := 0
Bin targetBin = p.bins.get(idx)
float addedValue = p.useVolume ? volumeValue : 1.0
targetBin.value += addedValue
3. Finding POC and Building the Value Area
Inside the draw method, the script first scans all bins to determine the maximum value and the total sum. The bin with the highest value becomes the POC. The value area is then constructed by expanding from that center bin until the desired percentage of total activity is covered:
for in p.bins
totalVal += b.value
if b.value > maxVal
maxVal := b.value
pocIdx := i
float vaTarget = totalVal * (p.vaPercent / 100.0)
float currentVaVol = maxVal
int upIdx = pocIdx
int downIdx = pocIdx
while currentVaVol < vaTarget
float upVol = (upIdx < p.binCount - 1) ? p.bins.get(upIdx + 1).value : 0.0
float downVol = (downIdx > 0) ? p.bins.get(downIdx - 1).value : 0.0
if upVol == 0 and downVol == 0
break
if upVol >= downVol
upIdx += 1
currentVaVol += upVol
else
downIdx -= 1
currentVaVol += downVol

Prime-Time × Vortex (3/6/9) — Ace (clean v3)1️⃣ Prime-Time Index (PT)
A bar becomes Prime-Time when the count satisfies the formula:
4·n − 3 is a perfect square
This generates the sequence:
1, 3, 7, 13, 21, 31, 43, 57, 73, 91, …
These are time windows where price is more likely to form:
Shifts in market structure
Impulses
Reversals
Liquidity expansions
These PT bars are drawn as small circles above the candle.
If labels are enabled, the counter value (n) is also shown.
2️⃣ Vortex 3/6/9 Digital-Root Timing
Every bar also has a digital root, calculated from the counter:
If n → digitalRoot(n) = 3, 6, or 9,
the bar is considered a Vortex bar.
These moments often align with:
Swing highs / swing lows
Micro shifts
Mini-reversals
Minor liquidity grabs
When a Prime-Time bar is also a 3/6/9 bar → high-probability timing.
These bars are highlighted in green by default.
3️⃣ Filters & Display
You can customize:
Anchor time → when counting begins
Reset daily → restart counter each new trading day
Show only 3/6/9 → hides normal PT hits
Label offset → distance above the candle
Color themes
This makes the indicator usable on:
1Min
5Min
15Min
1H
Any timeframe you want
4️⃣ How To Apply It in Trading
Use it as a time confluence tool, not a signal generator.
✔ Best ways to use:
Look for MSS, sweeps, OB retests, FVG reactions when
they occur on or near a Prime-Time or 3/6/9 bar
Expect volatility increases after PT bars
Use 3/6/9 hits to anticipate internal turning points
Combine with:
Session High/Low
Killzones (London, NYO, PM)
Purge Protocol
MMXM Execution
✔ Example:
If price sweeps a level and prints a 3/6/9 vortex bar inside a PT window →
you have a very strong timing alignment for reversal.
5️⃣ Simple Summary
Feature Meaning
Prime-Time Hit (PT) Major time window where price often shifts
3/6/9 Vortex Bar Micro-timing for internal swings
PT + 3/6/9 together High-probability timing for entries
Reset Daily Perfect for intraday models like NYO & London
Anchor Time Defines the entire cycle structure

Volatility Signal-to-Noise Ratio🙏🏻 this is VSNR: the most effective and simple volatility regime detector & automatic volatility threshold scaler that somehow no1 ever talks about.
This is simply an inverse of the coefficient of variation of absolute returns, but properly constructed taking into account temporal information, and made online via recursive math with algocomplexity O(1) both in expanding and moving windows modes.
How do the available alternatives differ (while some’re just worse)?
Mainstream quant stat tests like Durbin-Watson, Dickey-Fuller etc: default implementations are ALL not time aware. They measure different kinds of regime, which is less (if at all) relevant for actual trading context. Mix of different math, high algocomplexity.
The closest one is MMI by financialhacker, but his approach is also not time aware, and has a higher algocomplexity anyways. Best alternative to mine, but pls modify it to use a time-weighted median.
Fractal dimension & its derivatives by John Ehlers: again not time aware, very low info gain, relies on bar sizes (high and lows), which don’t always exist unlike changes between datapoints. But it’s a geometric tool in essence, so this is fundamental. Let it watch your back if you already use it.
Hurst exponent: much higher algocomplexity, mix of parametric and non-parametric math inside. An invention, not a math entity. Again, not time aware. Also measures different kinds of regime.
How to set it up:
Given my other tools, I choose length so that it will match the amount of data that your trading method or study uses multiplied by ~ 4-5. E.g if you use some kind of bands to trade volatility and you calculate them over moving window 64, put VSNR on 256.
However it depends mathematically on many things, so for your methods you may instead need multipliers of 1 or ~ 16.
Additionally if you wanna use all data to estimate SNR, put 0 into length input.
How to use for regime detection:
First we define:
MR bias: mean reversion bias meaning volatility shorts would work better, fading levels would work better
Momo bias: momentum bias meaning volatility longs would work better, trading breakouts of levels would work better.
The study plots 3 horizontal thresholds for VSNR, just check its location:
Above upper level: significant Momo bias
Above 1 : Momo bias
Below 1 : MR bias
Below lower level: significant MR bias
Take a look at the screenshots, 2 completely different volatility regimes are spotted by VSNR, while an ADF does not show different regime:
^^ CBOT:ZN1!
^^ INDEX:BTCUSD
How to use as automatic volatility threshold scaler
Copy the code from the script, and use VSNR as a multiplier for your volatility threshold.
E.g you use a regression channel and fade/push upper and lower thresholds which are RMSEs multiples. Inside the code, multiply RMSE by VSNR, now you’re adaptive.
^^ The same logic as when MM bots widen spreads with vola goes wild.
How it works:
Returns follow Laplace distro -> logically abs returns follow exponential distro , cuz laplace = double exponential.
Exponential distro has a natural coefficient of variation = 1 -> signal to noise ratio defined as mean/stdev = 1 as well. The same can be said for Student t distro with parameter v = 4. So 1 is our main threshold.
We can add additional thresholds by discovering SNRs of Student t with v = 3 and v = 5 (+- 1 from baseline v = 4). These have lighter & heavier tails each favoring mean reversion or momentum more. I computed the SNR values you see in the code with mpmath python module, with precision 256 decimals, so you can trust it I put it on my momma.
Then I use exponential smoothing with properly defined alphas (one matches cumulative WMA and another minimizes error with WMA in moving window mode) to estimate SNR of abs returns.
…
Lightweight huh?
∞