在腳本中搜尋"curve"
Branch CurveLibrary "branch"
Generates a branch made of segments with a starting angle
and a turning angle for each segment. The branch is generated from a starting point
and a number of nodes to generate. The length of each segment and angle of each segment
can be adjusted. The branch can be generated in 2D or 3D, render as you wish.
method branch(origin, nodes, segment_length, segment_growth, angle_start, angle_turn)
# Branch Generation.
- `origin`: CommonTypesMath.Vector3 - The starting point of the branch. If the z value is not zero, it will be used as the starting angle.
- `nodes`: int - The number of nodes to generate.
- `segment_length`: float - The length of each segment.
- `segment_growth`: float - The growth of each segment. 0 = no growth, 100 = double the length of the previous segment.
- `angle_start`: float - The starting angle of the branch in degrees.
- `angle_turn`: float - The turning angle of each segment in degrees.
Namespace types: CommonTypesMath.Vector3
Parameters:
origin (Vector3 type from RicardoSantos/CommonTypesMath/1) : The starting point of the branch. If the z value is not zero, it will be used as the starting angle.
nodes (int) : The number of nodes to generate.
segment_length (float) : The length of each segment.
segment_growth (float) : The growth of each segment. 0 = no growth, 100 = double the length of the previous segment.
angle_start (float) : The starting angle of the branch in degrees.
angle_turn (float) : The turning angle of each segment in degrees.
@return segments The list of segments that make up the branch.

Oscillating Length Moving Averages***CREDIT TO TradingView's TA Library*** (), Attempted to use "import TradingView/ta/4" to import the library, but for whatever reason
some of the functions failed to work, while others had no issue, so I opted to just copy paste what I wanted to use.
This moving average uses an oscillator to influence the length used during calculation. Extremely customizable/tunable with ability to change Max and Min length values, length multiplier, length multiple,4 different settings ,( Decline , <>Peak, >Decline , <>Peak, >
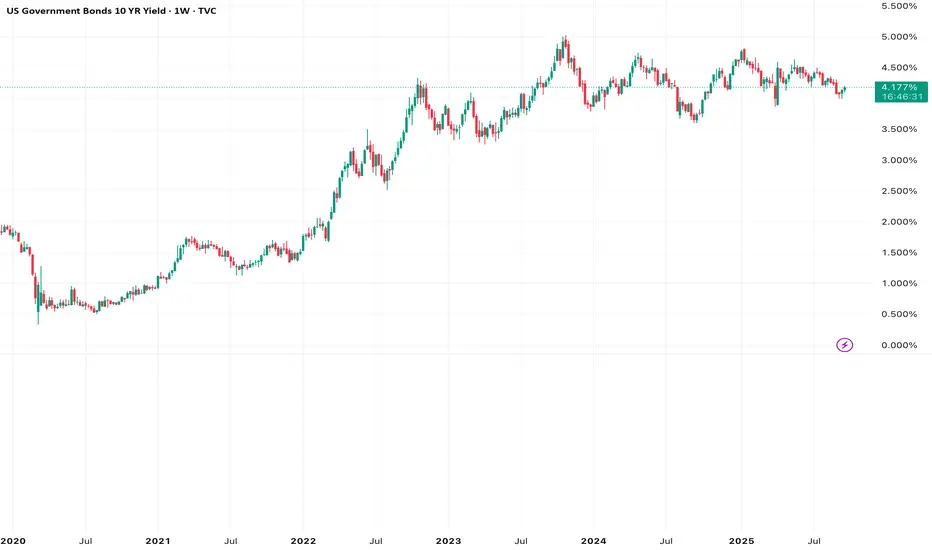
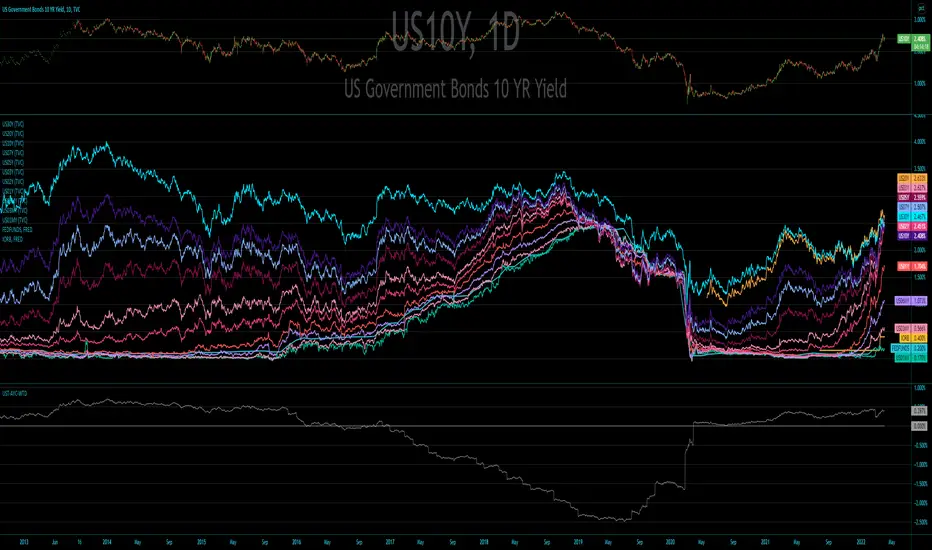
US Treasury All Yield Curve IORB WeightedI've updated my US Treasury All Yield Curve indicator to use the new FRED:IORB (interest on reserve balances), instead of the FRED:FEDFUNDS which is only updated monthly.
The new IORB doesn't provide very long lookback for data, so I'm publishing this as a new version and not an update, making it possible for users to choose which version best suits their needs.

US Treasury All Yield CurveRather than using one pair of treasuries, this indicator weighs them all in an overlapping fashion, to produce a composite yield curve that indicates the level of stress in the bond market.
US Bond Yield Magma CurveBond Market is the most important to monitor while investing and making macroeconomic desicions.
Inverted bond yeld curve is when short term bond yelds are greater than long term ones and this is a signal of fear for an imminent recession and disaster like a vulcano's eruption
The indicatior is applied to US Bond market but you can try to other countries like EU, China and so on. The code is free.
No further word is more powerful than a clear image as following:
Let's enjoy in making yourself decisions

US Treasury All Yield Curve FEDFUNDS WeightedRather than picking a benchmark pair of treasuries to express a yield curve, this indicator weighs all (excluding the new 20 Year) durations, each against the next, and weights that against the FEDFUNDS rate.
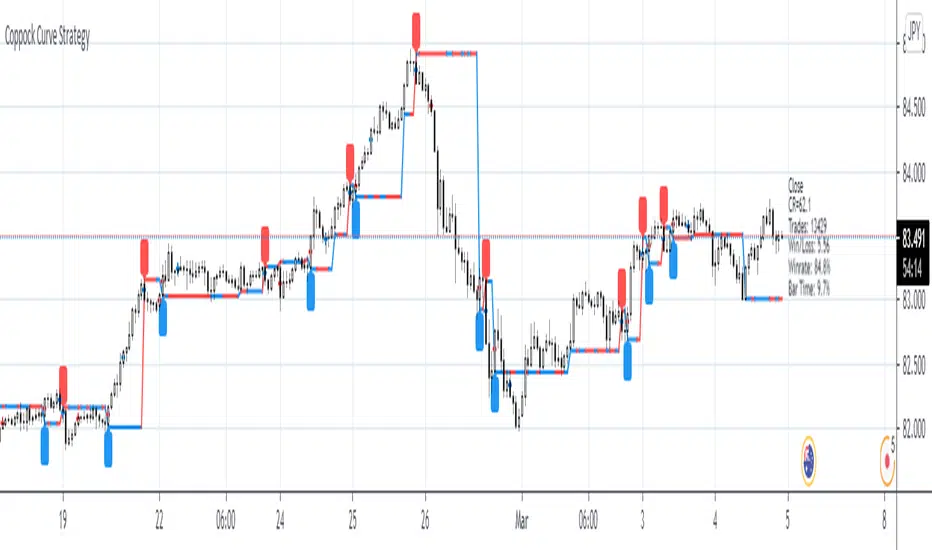
Coppock Curve StrategyCoppock Curve Strategy
Description:
The Coppock Indicator is a long-term price momentum oscillator which is used primarily to pinpoint major bottoms in the stock market. Crosses above the zero line indicate buying pressure, crosses below the center (zero) line indicate selling pressure.
This script generates a long entry signal when the Coppock value crosses over a signal line, and/or generates a short entry signal when the value crosses under a signal line.
Also it generates a long exit signal when the Coppock value crosses under a signal line, and/or generates a short exit signal when the value crosses over a signal line.
Signals can be filtered out by volatility, volume or both. To minimize repainting use higher percentage values of Time Threshold parameter.
Straightened Price CurveThis is another among zillions of attempts at a moving average of a security. More precisely, two attempts at one go). The zzoid function generates a zigzag-like MA that can adopt different forms. The stepline function creates, sure enough, a stepline.

US Treasury Yield CurveThis indicator plots the US treasury yield curve as maturity (x-axis/time) vs yield (y-axis/price)

Coppock CurveThis indicator was originally developed by Edwin "Sedge" Coppock (Barron's Magazine, October 1962).
Specially for @AlexMayorov :
1) Buy when indicator crosses the zero line upside
2) Sell when indicator crosses the zero line downside
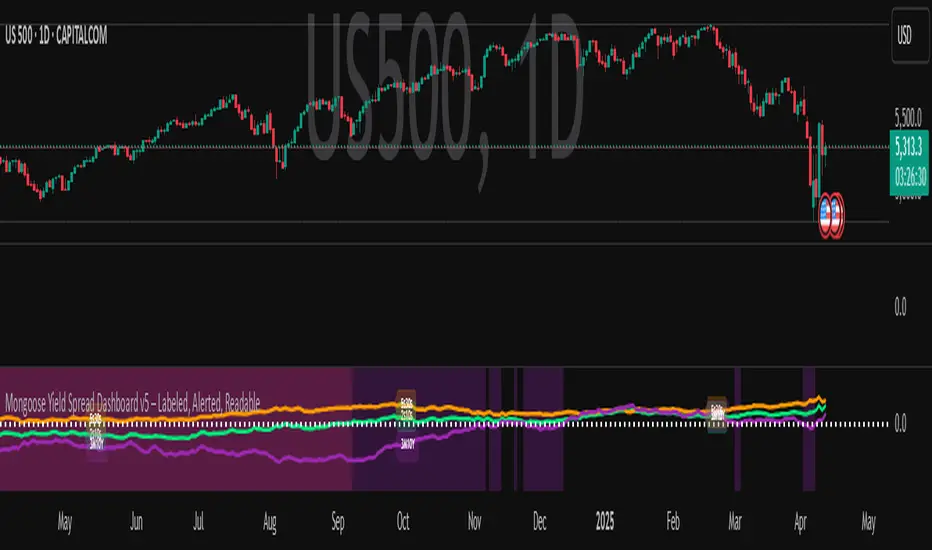
Mongoose Yield Spread Dashboard v5 – Labeled, Alerted, ReadableCurveGuard: Mongoose Edition
Track the macro tide before it turns.
This tool visualizes the three most-watched U.S. Treasury yield curve spreads:
2s10s (10Y - 2Y)
5s30s (30Y - 5Y)
3M10Y (10Y - 3M)
Each spread is plotted with dynamic color logic, inversion alerts, and floating labels. Background shading highlights historical inversion zones to help spot macro regime shifts in real time.
✅ Alert-ready
✅ Dark mode optimized
✅ Floating labels
✅ Clean layout for fast macro insight
📌 For educational and informational purposes only.
This script does not provide financial advice or trade recommendations.
Grid Bot Parabolic [xxattaxx]🟩 The Grid Bot Parabolic, a continuation of the Grid Bot Simulator Series , enhances traditional gridbot theory by employing a dynamic parabolic curve to visualize potential support and resistance levels. This adaptability is particularly useful in volatile or trending markets, enabling traders to explore grid-based strategies and gain deeper market insights. The grids are divided into customizable trade zones that trigger signals as prices move into new zones, empowering traders to gain deeper insights into market dynamics and potential turning points.
While traditional grid bots excel in ranging markets, the Grid Bot Parabolic’s introduction of acceleration and curvature adds new dimensions, enabling its use in trending markets as well. It can function as a traditional grid bot with horizontal lines, a tilted grid bot with linear slopes, or a fully parabolic grid with curves. This dynamic nature allows the indicator to adapt to various market conditions, providing traders with a versatile tool for visualizing dynamic support and resistance levels.
🔑 KEY FEATURES 🔑
Adaptable Grid Structures (Horizontal, Linear, Curved)
Buy and Sell Signals with Multiple Trigger/Confirmation Conditions
Secondary Buy and Secondary Sell Signals
Projected Grid Lines
Customizable Grid Spacing and Zones
Acceleration and Curvature Control
Sensitivity Adjustments
📐 GRID STRUCTURES 📐
Beyond its core parabolic functionality, the Parabolic Grid Bot offers a range of grid configurations to suit different market conditions and trading preferences. By adjusting the "Acceleration" and "Curvature" parameters, you can transform the grid's structure:
Parabolic Grids
Setting both acceleration and curvature to non-zero values results in a parabolic grid.This configuration can be particularly useful for visualizing potential turning points and trend reversals. Example: Accel = 10, Curve = -10)
Linear Grids
With a non-zero acceleration and zero curvature, the grid tilts to represent a linear trend, aiding in identifying potential support and resistance levels during trending phases. Example: Accel =1.75, Curve = 0
Horizontal Grids
When both acceleration and curvature are set to zero, the indicator reverts to a traditional grid bot with horizontal lines, suitable for ranging markets. Example: Accel=0, Curve=0
⚙️ INITIAL SETUP ⚙️
1.Adding the Indicator to Your Chart
Locate a Starting Point: To begin, visually identify a price point on your chart where you want the grid to start.This point will anchor your grid.
2. Setting Up the Grid
Add the Grid Bot Parabolic Indicator to your chart. A “Start Time/Price” dialog will appear
CLICK on the chart at your chosen start point. This will anchor the start point and open a "Confirm Inputs" dialog box.
3. Configure Settings. In the dialog box, you can set the following:
Acceleration: Adjust how quickly the grid reacts to price changes.
Curve: Define the shape of the parabola.
Intervals: Determine the distance between grid levels.
If you choose to keep the default settings, with acceleration set to 0 and curve set to 0, the grid will display as traditional horizontal lines. The grid will align with your selected price point, and you can adjust the settings at any time through the indicator’s settings panel.
⚙️ CONFIGURATION AND SETTINGS ⚙️
Grid Settings
Accel (Acceleration): Controls how quickly the price reacts to changes over time.
Curve (Curvature): Defines the overall shape of the parabola.
Intervals (Grid Spacing): Determines the vertical spacing between the grid lines.
Sensitivity: Fine tunes the magnitude of Acceleration and Curve.
Buy Zones & Sell Zones: Define the number of grid levels used for potential buy and sell signals.
* Each zone is represented on the chart with different colors:
* Green: Buy Zones
* Red: Sell Zones
* Yellow: Overlap (Buy and Sell Zones intersect)
* Gray: Neutral areas
Trigger: Chooses which part of the candlestick is used to trigger a signal.
* `Wick`: Uses the high or low of the candlestick
* `Close`: Uses the closing price of the candlestick
* `Midpoint`: Uses the middle point between the high and low of the candlestick
* `SWMA`: Uses the Symmetrical Weighted Moving Average
Confirm: Specifies how a signal is confirmed.
* `Reverse`: The signal is confirmed if the price moves in the opposite direction of the initial trigger
* `Touch`: The signal is confirmed when the price touches the specified level or zone
Sentiment: Determines the market sentiment, which can influence signal generation.
* `Slope`: Sentiment is based on the direction of the curve, reflecting the current trend
* `Long`: Sentiment is bullish, favoring buy signals
* `Short`: Sentiment is bearish, favoring sell signals
* `Neutral`: Sentiment is neutral. No secondary signals will be generated
Show Signals: Toggles the display of buy and sell signals on the chart
Chart Settings
Grid Colors: These colors define the visual appearance of the grid lines
Projected: These colors define the visual appearance of the projected lines
Parabola/SWMA: Adjust colors as needed. These are disabled by default.
Time/Price
Start Time & Start Price: These set the starting point for the parabolic curve.
* These fields are automatically populated when you add the indicator to the chart and click on an initial location
* These can be adjusted manually in the settings panel, but he easiest way to change these is by directly interacting with the start point on the chart
Please note: Time and Price must be adjusted for each chart when switching assets. For example, a Start Price on BTCUSD of $60,000 will not work on an ETHUSD chart.
🤖 ALGORITHM AND CALCULATION 🤖
The Parabolic Function
At the core of the Parabolic Grid Bot lies the parabolic function, which calculates a dynamic curve that adapts to price action over time. This curve serves as the foundation for visualizing potential support and resistance levels.
The shape and behavior of the parabola are influenced by three key user-defined parameters:
Acceleration: This parameter controls the rate of change of the curve's slope, influencing its tilt or steepness. A higher acceleration value results in a more pronounced tilt, while a lower value leads to a gentler slope. This applies to both curved and linear grid configurations.
Curvature: This parameter introduces and controls the curvature or bend of the grid. A higher curvature value results in a more pronounced parabolic shape, while a lower value leads to a flatter curve or even a straight line (when set to zero).
Sensitivity: This setting fine-tunes the overall responsiveness of the grid, influencing how strongly the Acceleration and Curvature parameters affect its shape. Increasing sensitivity amplifies the impact of these parameters, making the grid more adaptable to price changes but potentially leading to more frequent adjustments. Decreasing sensitivity reduces their impact, resulting in a more stable grid structure with fewer adjustments. It may be necessary to adjust Sensitivity when switching between different assets or timeframes to ensure optimal scaling and responsiveness.
The parabolic function combines these parameters to generate a curve that visually represents the potential path of price movement. By understanding how these inputs influence the parabola's shape and behavior, traders can gain valuable insights into potential support and resistance areas, aiding in their decision-making process.
Sentiment
The Parabolic Grid Bot incorporates sentiment to enhance signal generation. The "Sentiment" input allows you to either:
Manually specify the market sentiment: Choose between 'Long' (bullish), 'Short' (bearish), or 'Neutral'.
Let the script determine sentiment based on the slope of the parabolic curve: If 'Slope' is selected, the sentiment will be considered 'Long' when the curve is sloping upwards, 'Short' when it's sloping downwards, and 'Neutral' when it's flat.
Buy and Sell Signals
The Parabolic Grid Bot generates buy and sell signals based on the interaction between the price and the grid levels.
Trigger: The "Trigger" input determines which part of the candlestick is used to trigger a signal (wick, close, midpoint, or SWMA).
Confirmation: The "Confirm" input specifies how a signal is confirmed ('Reverse' or 'Touch').
Zones: The number of "Buy Zones" and "Sell Zones" determines the areas on the grid where buy and sell signals can be generated.
When the trigger condition is met within a buy zone and the confirmation criteria are satisfied, a buy signal is generated. Similarly, a sell signal is generated when the trigger and confirmation occur within a sell zone.
Secondary Signals
Secondary signals are generated when a regular buy or sell signal contradicts the prevailing sentiment. For example:
A buy signal in a bearish market (Sentiment = 'Short') would be considered a "secondary buy" signal.
A sell signal in a bullish market (Sentiment = 'Long') would be considered a "secondary sell" signal.
These secondary signals are visually represented on the chart using hollow triangles, differentiating them from regular signals (filled triangles).
While they can be interpreted as potential contrarian trade opportunities, secondary signals can also serve other purposes within a grid trading strategy:
Exit Signals: A secondary signal can suggest a potential shift in market sentiment or a weakening trend. This could be a cue to consider exiting an existing position, even if it's currently profitable, to lock in gains before a potential reversal
Risk Management: In a strong trend, secondary signals might offer opportunities for cautious counter-trend trades with controlled risk. These trades could utilize smaller position sizes or tighter stop-losses to manage potential downside if the main trend continues
Dollar-Cost Averaging (DCA): During a prolonged trend, the parabolic curve might generate multiple secondary signals in the opposite direction. These signals could be used to implement a DCA strategy, gradually accumulating a position at potentially favorable prices as the market retraces or consolidates within the larger trend
Secondary signals should be interpreted with caution and considered in conjunction with other technical indicators and market context. They provide additional insights into potential market reversals or consolidation phases within a broader trend, aiding in adapting your grid trading strategy to the evolving market dynamics.
Examples
Trigger=Wick, Confirm=Touch. Signals are generated when the wick touches the next gridline.
Trigger=Close, Confirm=Touch. Signals require the close to touch the next gridline.
Trigger=SWMA, Confirm=Reverse. Signals are triggered when the Symmetrically Weighted Moving Average reverse crosses the next gridline.
🧠THEORY AND RATIONALE 🧠
The innovative approach of the Parabolic Grid Bot can be better understood by first examining the limitations of traditional grid trading strategies and exploring how this indicator addresses them by incorporating principles of market cycles and dynamic price behavior
Traditional Grid Bots: One-Dimensional and Static
Traditional grid bots operate on a simple premise: they divide the price chart into a series of equally spaced horizontal lines, creating a grid of trading zones. These bots excel in ranging markets where prices oscillate within a defined range. Buy and sell orders are placed at these grid levels, aiming to profit from mean reversion as prices bounce between the support and resistance zones.
However, traditional grid bots face challenges in trending markets. As the market moves in one direction, the bot continues to place orders in that direction, leading to a stacking of positions. If the market eventually reverses, these stacked trades can be profitable, amplifying gains. But the risk lies in the potential for the market to continue trending, leaving the trader with a series of losing trades on the wrong side of the market
The Parabolic Grid Bot: Adding Dimensions
The Parabolic Grid Bot addresses the limitations of traditional grid bots by introducing two additional dimensions:
Acceleration (Second Dimension): This parameter introduces a second dimension to the grid, allowing it to tilt upwards or downwards to align with the prevailing market trend. A positive acceleration creates an upward-sloping grid, suitable for uptrends, while a negative acceleration results in a downward-sloping grid, ideal for downtrends. The magnitude of acceleration controls the steepness of the tilt, enabling you to fine-tune the grid's responsiveness to the trend's strength
Curvature (Third Dimension): This parameter adds a third dimension to the grid by introducing a parabolic curve. The curve's shape, ranging from gentle bends to sharp turns, is controlled by the curvature value. This flexibility allows the grid to closely mirror the market's evolving structure, potentially identifying turning points and trend reversals.
Mean Reversion in Trending Markets
Even in trending markets, the Parabolic Grid Bot can help identify opportunities for mean reversion strategies. While the grid may be tilted to reflect the trend, the buy and sell zones can capture short-term price oscillations or consolidations within the broader trend. This allows traders to potentially pinpoint entry and exit points based on temporary pullbacks or reversals.
Visualize and Adapt
The Parabolic Grid Bot acts as a visual aid, enhancing your understanding of market dynamics. It allows you to "see the curve" by adapting the grid to the market's patterns. If the market shows a parabolic shape, like an upward curve followed by a peak and a downward turn (similar to a head and shoulders pattern), adjust the Accel and Curve to match. This highlights potential areas of interest for further analysis.
Beyond Straight Lines: Visualizing Market Cycle
Traditional technical analysis often employs straight lines, such as trend lines and support/resistance levels, to interpret market movements. However, many analysts, including Brian Millard, contend that these lines can be misleading. They propose that what might appear as a straight line could represent just a small part of a larger curve or cycle that's not fully visible on the chart.
Markets are inherently cyclical, marked by phases of expansion, contraction, and reversal. The Parabolic Grid Bot acknowledges this cyclical behavior by offering a dynamic, curved grid that adapts to these shifts. This approach helps traders move beyond the limitations of straight lines and visualize potential support and resistance levels in a way that better reflects the market's true nature
By capturing these cyclical patterns, whether subtle or pronounced, the Parabolic Grid Bot offers a nuanced understanding of market dynamics, potentially leading to more accurate interpretations of price action and informed trading decisions.
⚠️ DISCLAIMER⚠️
This indicator utilizes a parabolic curve fitting approach to visualize potential support and resistance levels. The mathematical formulas employed have been designed with adaptability and scalability in mind, aiming to accommodate various assets and price ranges. While the resulting curves may visually resemble parabolas, it's important to note that they might not strictly adhere to the precise mathematical definition of a parabola.
The indicator's calculations have been tested and generally produce reliable results. However, no guarantees are made regarding their absolute mathematical accuracy. Traders are encouraged to use this tool as part of their broader analysis and decision-making process, combining it with other technical indicators and market context.
Please remember that trading involves inherent risks, and past performance is not indicative of future results. It is always advisable to conduct your own research and exercise prudent risk management before making any trading decisions.
🧠 BEYOND THE CODE 🧠
The Parabolic Grid Bot, like the other grid bots in this series, is designed with education and community collaboration in mind. Its open-source nature encourages exploration, experimentation, and the development of new grid trading strategies. We hope this indicator serves as a framework and a starting point for future innovations in the field of grid trading.
Your comments, suggestions, and discussions are invaluable in shaping the future of this project. We welcome your feedback and look forward to seeing how you utilize and enhance the Parabolic Grid Bot.

Flexible S/R Channels🟩 Flexible S/R Channels is a visualization tool that draws curved support and resistance boundaries through user-defined anchor points. Unlike traditional trendlines and channels that force linear interpretation onto price action, this indicator captures the curved structures that markets frequently form—rounded tops and bottoms, parabolic advances and declines, arcing rallies and pullbacks. Three anchor points per curve define the shape; the indicator fits a smooth mathematical curve through these points and projects it forward. The approach is simple: draw what you see. Curved market structure that resists precise definition with traditional tools can now be rendered with mathematical accuracy.
The indicator bridges the gap between static drawing tools and programmable indicators. TradingView's arc tool draws curves but produces only visual pixels with no analytical value. Flexible S/R Channels creates live data series that integrate with other analysis tools. Four curve-fitting methods—Quadratic, Quadratic-Linear, Weighted Linear, and Natural Cubic Spline—accommodate different market structures. The curved levels naturally lend themselves to breakout and reversion strategies—applications left to the trader's discretion. The open-source code invites experimentation and customization.
💡 THEORY AND CONCEPT 💡
Traders have long relied on horizontal levels and diagonal trendlines to define support and resistance. Linear tools assume constant slope—a property rarely exhibited by actual market movement. When momentum accelerates or decelerates, price trajectories curve rather than hold to fixed angles. The resulting structures—parabolic advances during expansion phases, arcing pullbacks during consolidation, rounded formations at reversal points—represent changes in the rate of change itself. Traditional drawing tools cannot accommodate this variable geometry without sacrificing mathematical precision..
Flexible S/R Channels extends familiar support and resistance concepts into curved space. The approach is simple: draw what you see. When the eye recognizes a curved boundary in price action, this indicator provides the means to define it precisely. Three anchor points per curve—an initial point, an intermediate point, and a recent point—are all that is required. The indicator fits a smooth mathematical curve through these points and extends it forward as a projection.
This indicator represents a blend of human pattern recognition and algorithmic precision. Fully automated indicators make decisions without user input—efficient but detached from trader discretion. Manual drawing tools rely entirely on freehand skill—expressive but imprecise. Flexible S/R Channels occupies the middle ground. The trader identifies the curved structure; the algorithm renders it mathematically. The result is human insight expressed with computational accuracy—for traders who recognize curved structure in price action but lack precise tools to define it.
This projection is not a prediction. It is a visual hypothesis—a structured way of asking "if this trajectory continues, where would price be?" The underlying assumption is simple: like Newton's first law of motion, a trajectory in motion tends to continue unless acted upon by an external force. Future price action validates or invalidates the projection, just as it does with any trendline or channel.
TradingView offers an arc drawing tool for freehand curved lines, but these are purely visual—static pixels on a screen with no programmable value. Flexible S/R Channels bridges this gap. The fitted curves exist as data series that can generate alerts, trigger signals, and interact with other analysis tools. The visual drawing becomes operational structure.
🔁 CURVE METHODS 🔁
The indicator offers four curve-calculation methods, each producing different shapes suited to different market structures:
Quadratic — Fits a parabolic arc through the three anchor points. Best for smooth, continuous curves such as rounded tops and bottoms. It captures the natural "swing" of the market, assuming the momentum will maintain its current rate of acceleration or deceleration.
Quadratic-Linear — Uses a parabolic curve through the anchor points, then transitions to a straight line after the final anchor. Useful when curved structure gives way to linear trend continuation. This is the "bridge" between a turning market and a steady, directed move, preventing the projection from curving back on itself when the price begins to run.
Weighted Linear — Connects anchor points with straight line segments rather than a smooth curve. Suited for angular market structures with distinct inflection points. It treats the market as a series of rigid shifts, providing a clear "corridor" when the price is bouncing between sharp, diagonal levels.
Natural Cubic Spline — Produces the smoothest curve by minimizing abrupt directional changes. Ideal for organic, flowing market movements. It acts as a flexible spine that adapts to complex transitions without the rigid constraints of a fixed geometric shape.
Quadratic Fitting : A smooth, parabolic arc defines a curved resistance boundary. By fitting a mathematical path through three anchor points, the curve captures rounded structures and arcing price action that traditional linear trendlines fail to represent.
Weighted Linear Fitting : This method produces an angular, segmented path by connecting anchor points with distinct linear slopes. Unlike the continuous smoothness of a quadratic arc, the weighted linear approach creates a more jointed geometry, allowing for a precise match to market structures that exhibit sharp, localized changes in trajectory.
Natural Cubic Spline Fitting : This method creates a highly fluid, elastic curve that can accommodate complex price oscillations. In this instance, the curves define a narrowing range as support and resistance converge, highlighting the volatility compression that often precedes a significant breakout or breakdown from established structures.
🖱️ HOW IT WORKS 🖱️
1️⃣ Initial Setup
Unlike traditional indicators that calculate values automatically from price data, Flexible S/R Channels requires user-defined anchor points. This is intentional. The trader's eye is the pattern recognition engine—no algorithm can see the curved structure that experience and intuition reveal. The indicator waits for this input, then applies mathematical precision to render what the trader has identified.
The Recognition of Natural Structure : Effective analysis begins when a curved rhythm becomes visible within price action that traditional trendlines cannot satisfy. Identifying the specific swing highs and swing lows that define these boundaries is the first step in organizing a chart. By isolating three key pivots for resistance and three for support, the underlying framework of the market's trajectory is established, providing the necessary coordinates to accurately map the path.
Interactive Setup Workflow : Upon loading, the indicator prompts for the sequential selection of six points—three swing highs and three swing lows—to serve as the raw data for the calculation. While the chart remains blank during this initial phase, the curves generate instantly once the final anchor is confirmed. These points are not permanent; they appear as interactive grips that can be dragged in real time to refine the boundaries as the market structure evolves.
The indicator prompts for six sequential selections—three for resistance, three for support. The first three selections define the resistance boundary; the final three define support. This sequential grouping is distinct from zigzag-style selection patterns. Within each group, clicking order is flexible—the algorithm automatically sorts points chronologically, allowing traders to select visually prominent pivots in whatever sequence feels natural.
Structural Anchor Identification : Identifying three key swing highs and three key swing lows provides the foundation for the dual-curve geometry. These specific structural peaks and troughs serve as the coordinates for the mathematical models, ensuring that the resulting boundaries accurately reflect the underlying skeleton of the market action.
2️⃣ Interactive Adjustment
After the initial setup, all six anchor points are fully adjustable:
Points are automatically sorted chronologically regardless of selection order
Grip handles appear at each anchor location
Any point can be repositioned by clicking and dragging its grip handle
The curves recalculate instantly as points are adjusted
The algorithm produces a mathematically perfect curve based on the anchor points provided. If the result does not match the trader's vision, adjustments are immediate. This iterative refinement—see, adjust, refine—continues until the rendered curve represents what the trader sees in the price action. The user remains in control; the algorithm remains in service.
Interactive Channel Boundaries : Six user-defined anchor points—three for resistance and three for support —establish a non-linear range that moves beyond the constraints of a flat, horizontal channel. This configuration captures the arcing trajectory of the market while showing price action respecting the curved boundaries in a classic reversion pattern. By manually positioning these anchors, a dynamic dimension is added to the chart that maintains structural integrity even as the price follows a rounded path.
🛠️ SETTINGS 🛠️
Customizable Visual Feedback : Beyond the core geometry, the visualization offers various user-defined settings to tailor the chart's information density. From identifying specific price targets to toggling structural labels, these options allow the trader to adjust the level of detail to suit their personal analysis style while maintaining a clear view of the non-linear boundaries.
Configuration Options
Curve Method — Select the curve-fitting algorithm: Quadratic, Quadratic-Linear, Weighted Linear, or Natural Cubic Spline.
Projection Length — Number of bars to project the curves beyond current price action. Projections appear as dashed lines.
Visual Settings
Grip Size — Size of the draggable handles displayed at each anchor point. Set to zero to hide grips entirely.
Line Width — Thickness of the support and resistance curves.
Support Color / Resistance Color — Color settings for each curve.
Show Info Table — Toggle display of the info table showing the current curve method in the chart corner.
Advanced: Time/Price Coordinates
The settings panel includes precise time and price values for each of the six anchor points, grouped under Resistance Time/Price and Support Time/Price. These values are populated automatically when points are selected on the chart.
Adjusting anchor points by dragging the grip handles directly on the chart is faster and more intuitive. The time/price fields are available for situations requiring exact coordinate entry—such as aligning an anchor to a specific candle timestamp or a precise price level. These fields can be safely ignored unless fine-tuning is necessary.
🖼️ CHART EXAMPLES 🖼️
The Flexible S/R Channels indicator adapts to diverse market structures across multiple timeframes and instruments. Curved boundaries can define subtle momentum shifts in near-linear trends, dramatic reversals in rounding formations, or volatility compression as channels converge toward breakout points. The four curve-fitting methods accommodate different geometries—smooth parabolic arcs for continuous momentum changes, segmented linear paths for angular structures, and elastic splines for complex oscillations. Each anchor point adjustment instantly recalculates the curves, allowing iterative refinement until the rendered boundaries align with the trader's interpretation of market structure. Forward projections extend these mathematical relationships into future territory, providing visual context for hypothetical support and resistance levels if current trajectories persist.
Subtle Curve Alignment : Even in structures that appear linear, subtle curvature allows the channel boundaries to breathe with the market’s internal momentum. By utilizing three anchor points rather than two, the channel adapts to the slight acceleration of a trend, providing a more precise fit than a rigid, straight corridor.
Decelerating Momentum and Convergence : This classic rounding structure illustrates a transition where the initial wide oscillations between highs and lows begin to contract. As the boundaries converge, the curve captures the diminishing volatility and the shift in market energy, providing a clear visual representation of a trend losing its expansive momentum as it approaches a potential turning point.
Organic Trend Modeling : In an accelerating uptrend, the Natural Cubic Spline provides a highly adaptable boundary that mirrors the organic flow of momentum. This non-traditional approach allows the channel to follow complex price pulses that a standard linear trendline would likely cut through, maintaining a precise fit even as the angle of the trend shifts over time.
Non-Linear Projections : Unlike standard trendlines that converge at a fixed rate, curved projections adapt to the historical momentum of the move. This allows the indicator to map a dynamic squeeze, capturing the subtle nuances of how price action tightens toward an apex. It provides a more sophisticated view of future convergence points that traditional linear channels often fail to anticipate.
The "Draw What You See" Philosophy : Market structures are rarely perfect, and this example highlights the indicator’s ability to map unconventional rhythms. Rather than forcing price into a predefined category, the tool remains flexible enough to define any structural path the trader identifies. If you can see a trend's trajectory, the indicator can provide the mathematical framework to support it.
Comparative Projection Modeling : Using identical anchor points as above, this example demonstrates how selecting a different calculation method can alter the projected path. While the historical fit remains precise, the variation in the forward-looking trajectory allows traders to explore multiple mathematical interpretations of the same market structure, choosing the model that best aligns with the current volatility and trend behavior.
Extended Timeframe Channel Definition : This multi-year perspective demonstrates the indicator's ability to define curved channel boundaries across extended timeframes spanning hundreds of bars and multiple market cycles. The resistance curve captures the rounded distribution of swing highs while the support curve follows the accelerating base formation, creating a non-linear channel that frames long-term structural trends more precisely than traditional parallel channels or static trendlines.
Rounding Bottom Reversal and Channel Convergence : This example captures a classic rounding bottom formation—a reversal pattern that linear tools cannot adequately define. The Quadratic method produces a smooth parabolic arc through the resistance anchors, tracing the deceleration of the downtrend, the capitulation low, and the subsequent re-acceleration upward as a single continuous curve. The support boundary mirrors this momentum shift from below, creating a curved channel that narrows toward current price. This convergence represents structural compression—the boundaries tightening as volatility contracts and directional resolution approaches. Price action oscillates within these non-linear boundaries, demonstrating that channel behavior persists even when the geometry is curved rather than parallel. The projection extends both curves forward, mapping the hypothetical trajectory if the current momentum structure continues, providing visual context for potential breakout or breakdown levels as the channel reaches its apex.
Built-in Precision vs. Algorithmic Power : While TradingView offers basic curve drawing tools (shown here as dashed lines), the Flexible S/R Channels indicator elevates this concept into a functional analytical framework. By converting manual observations into mathematical models, it moves beyond mere drawing to provide a data-driven structure that can be utilized for advanced technical analysis and future Pine Script trading logic.
⚙️ TECHNICAL DETAILS ⚙️
Curve Fitting vs. Overfitting: The term curve fitting often carries negative connotations in quantitative analysis due to its association with overfitting—the practice of adjusting a model until it perfectly matches historical data, producing an illusion of accuracy that fails when applied to new data. The application here is fundamentally different. Flexible S/R Channels does not optimize parameters to maximize historical fit; it constructs a mathematical curve through user-selected anchor points, then projects that curve into unknown territory. The curve is not fitted to price data—it is fitted to structural pivots identified by the trader. The projection represents a hypothesis about trajectory continuation, not a prediction derived from statistical optimization. Future price action validates or invalidates this hypothesis in real time, exactly as it does with any trendline or channel. The anchor points remain fixed unless manually adjusted, ensuring the curve does not adapt to new data retroactively.
Non-Repainting Behavior: The indicator does not repaint historical bars. The mathematical coefficients that define each curve are calculated once—when the final anchor point is set—and stored as fixed values. These coefficients remain constant unless an anchor point is manually repositioned. The backfit polyline is drawn once using these coefficients, spanning the known range from the first to last anchor point. The plot() function applies the same coefficients to each subsequent bar, updating in real-time as new bars form but never altering previously plotted values. The projection polyline extends forward from the current bar using the same fixed coefficients, projecting a user-defined number of future bars (maximum 500). This projection redraws on each tick to maintain its position relative to the moving current bar, but the mathematical trajectory remains constant—only the starting point advances. The current bar's curve value will update tick-by-tick as price develops, which is standard real-time behavior, not repainting. Once a bar closes, all curve values on that bar are permanent. The hybrid architecture (backfit polyline for known history, plot() for unlimited real-time range, projection polyline for controlled forward extension) prevents overflow errors while maintaining non-repainting integrity across all components.
🗒️ NOTES 🗒️
The indicator renders curves based on any anchor points provided without validation. Unusual anchor placement produces mathematically accurate but potentially non-useful results. Adjustment is iterative—if the curve doesn't match expectations, reposition the anchors.
Because anchor points are stored as specific time and price coordinates, a new instance of the indicator should be added when analyzing a different chart or timeframe.
Grip handles can be hidden by setting Grip Size to zero in the settings. This is useful for clean chart screenshots or presentations where interactive elements are not needed.
Projection length can be set to zero if forward-looking curves are not desired. The indicator will still render the backfit curves through the anchor points and continue plotting in real-time without the dotted projection extensions.
Anchor points remain fixed at their selected time-price coordinates as new bars form. The curves extend forward automatically from these historical anchors, allowing observation of how projected trajectories align with developing price action.
⚠️ DISCLAIMER ⚠️
The Flexible S/R Channels indicator is a visual analysis tool designed to illustrate geometric market inertia and serve as a framework for understanding dynamic support and resistance. While the indicator generates structural channels and projected paths, no guarantee is made regarding the accuracy or profitability of these projections. Like all technical indicators, the curves and boundaries generated by this tool may appear to align with favorable trading opportunities in hindsight. However, these visualizations are not intended as standalone recommendations for trading decisions. This indicator is intended for educational and analytical purposes, complementing other tools and methods of market analysis.
🧠 BEYOND THE CODE 🧠
Flexible S/R Channels is part of a broader collection of tools designed to provide structured market analysis. This includes the Grid Bot Simulator , the Grid Bot Auto , the Grid Bot Parabolic , and the Gridbot Ping Pong . While each tool serves a distinct purpose, they all utilize dynamic anchor mechanics and non-linear boundaries to adapt to evolving market conditions.
This indicator shares the same educational philosophy as the Fibonacci Time-Price Zones and the Fibonacci Geometry Series - providing frameworks for understanding market concepts through visualization and experimentation rather than black-box signals.
The Flexible S/R Channels indicator, like other xxattaxx indicators , is designed to encourage both education and community engagement. Feedback and insights are invaluable to refining and enhancing this tool. We look forward to the creative applications, observations, and discussions this indicator inspires within the trading community.

MIDAS VWAP Jayy his is just a bash together of two MIDAS VWAP scripts particularly AkifTokuz and drshoe.
I added the ability to show more MIDAS curves from the same script.
The algorithm primarily uses the "n" number but the date can be used for the 8th VWAP
I have not converted the script to version 3.
To find bar number go into "Chart Properties" select " "background" then select Indicator Titles and "Indicator values". When you place your cursor over a bar the first number you see adjacent to the script title is the bar number. Put that in the dialogue box midline is MIDAS VWAP . The resistance is a MIDAS VWAP using bar highs. The resistance is MIDAS VWAP using bar lows.
In most case using N will suffice. However, if you are flipping around charts inputting a specific date can be handy. In this way, you can compare the same point in time across multiple instruments eg first trading day of the year or an election date.
Adding dates into the dialogue box is a bit cumbersome so in this version, it is enabled for only one curve. I have called it VWAP and it follows the typical VWAP algorithm. (Does that make a difference? Read below re my opinion on the Difference between MIDAS VWAP and VWAP ).
I have added the ability to start from the bottom or top of the initiating bar.
In theory in a probable uptrend pick a low of a bar for a low pivot and start the MIDAS VWAP there using the support.
For a downtrend use the high pivot bar and select resistance. The way to see is to play with these values.
Difference between MIDAS VWAP and the regular VWAP
MIDAS itself as described by Levine uses a time anchored On-Balance Volume (OBV) plotted on a graph where the horizontal (abscissa) arm of the graph is cumulative volume not time. He called his VWAP curves Support/Resistance VWAP or S/R curves. These S/R curves are often referred to as "MIDAS curves".
These are the main components of the MIDAS chart. A third algorithm called the Top-Bottom Finder was also described. (Separate script).
Additional tools have been described in "MIDAS_Technical_Analysis"
Midas Technical Analysis: A VWAP Approach to Trading and Investing in Today’s Markets by Andrew Coles, David G. Hawkins
Copyright © 2011 by Andrew Coles and David G. Hawkins.
Denoting the different way in which Levine approached the calculation.
The difference between "MIDAS" VWAP and VWAP is, in my opinion, much ado about nothing. The algorithms generate identical curves albeit the MIDAS algorithm launches the curve one bar later than the VWAP algorithm which can be a pain in the neck. All of the algorithms that I looked at on Tradingview step back one bar in time to initiate the MIDAS curve. As such the plotted curves are identical to traditional VWAP assuming the initiation is from the candle/bar midpoint.
How did Levine intend the curves to be drawn?
On a reversal, he suggested the initiation of the Support and Resistance VVWAP (S/R curve) to be started after a reversal.
It is clear in his examples this happens occasionally but in many cases he initiates the so-called MIDAS S/R VWAP right at the reversal point. In any case, the algorithm is problematic if you wish to start a curve on the first bar of an IPO .
You will get nothing. That is a pain. Also in Levine's writings, he describes simply clicking on the point where a
S/R VWAP is to be drawn from. As such, the generally accepted method of initiating the curve at N-1 is a practical and sensible method. The only issue is that you cannot draw the curve from the first bar on any security, as mentioned without resorting to the typical VWAP algorithm. There is another difference. VWAP is launched from the middle of the bar (as per AlphaTrends), You can also launch from the top of the bar or the bottom (or anywhere for that matter). The calculation proceeds using the top or bottom for each new bar.
The potential applications are discussed in the MIDAS Technical Analysis book.
TZtraderTZtrader
This is a TrendZones version with features to set stoploss and targets in short and long positions meant for use in intraday charts. It aims to provide signals for opening and closing long and short positions. In the comments under the TrendZones publication several people expressed a need for features for a short position similar to those for a long position as implemented in TrendZones, some want to use it for scalping, some asked for alerts. When I proposed to create a version for day trading with target lines based on ATR, several people liked the idea.
Full disclosure: I don’t do day trading, because, after I lost a lot of money, I had to promise my wife to stay away from it. I restrict myself to long term investing in stocks which are in uptrend. However I understand what a day trader needs. I gather from my experience that day trading or scalping is an attempt to earn something by opening a position in the morning and close, reopen and close it again during the day with a profit. It is usually done with leveraged instruments like CFD’s, futures, options, and what have you. Opening and closing positions is done within minutes, so the trader needs a quick and efficient way to set proper stoploss and target. TZtrader supports this by showing only three or four numbers on the price bar: The price of the instrument, The logical stop level (gray or green or maroon dots), and the target level (navy). All other numbers are suppressed to prevent mistakes. Also a clear feedback for current settings at the top-center of the pane and an alert feedback at bottom that flashes alerts during the development of the current bar and gives suppression status.
The script
First I made a bare bones version of TrendZones to which I added code for long and short trading setups and a bare setup for no position. The code for the logical stops in long setup had to be reviewed, after which this became the basis for stops in short setup.
Then I added code for 10 alert messages, which was a hassle, because this is the first time I coded alerts and the first time I used an array as a stack to avoid a complicated if-then construction. During testing the array caused a runtime error which I solved by adding ‘array.clear’ to the code, also I discovered that in TradingView separate alerts have to be created for all three setups - short, long and bare. Flipping setups is done in the inputs with a dropdown menu because Pine Script has no function for a clickable button.
One visual with three setups.
The visual has the TrendZones structure: Three near parallel very smooth curves, which border the moderate uptrend (green) and downtrend (orange) zone over and under the curve in the middle, the COG (Center Of Gravity). Where the price breaks out of these curves, strong trend zones show up over and under the curves, respectively strong uptrend (blue) and strong downtrend (red).
Three setups were made clearly different to avoid confusion and to provide oversight in case of multiple trades going on simultaneously which I imagine are monitored in one screen. You have to see which one is long, which short and which have no position. The long setup should not trigger short signals, nor should the short trigger long signals nor the bare setup exclusive long or short signals.
The Long setup is default, shown on the example chart. In this setup the Stoploss suggestions (green, gray and maroon dots) are under the price bars and the target line (navy) at a set distance above the High Border. A zone with a width of 1 ATR is drawn under the Low Border. In this setup 5 specific alerts are provided
The Short setup has the Stoploss suggestions over the price bars, the target line at a set distance under the Low Border. A zone with a width of 1 ATR is drawn above the High Border. This setup also has 5 specific alerts.
The Bare setup has no Stoploss suggestions, no target line and supports 4 alerts, 2 in common with the Long setup and 2 with Short.
The table below gives a summary of scripted alerts:
Setup = Where = When = Purpose
Long, Bare = Green Zone = Bars come from lower zones = Uptrend starts
Long, Bare = Green Zone = Sideways ends in uptrend = Uptrend resumes
Long = COG = First crossing = Uptrend might end warning
Long = Orange Zone = Bars come from higher zones = Uptrend ended take care
Long = Red Zone = Bars come from higher zones = Strong downtrend->close Long
Short, Bare = Orange Zone = Bars come from higher zones = Downtrend starts
Short, Bare = Orange Zone = Sideways ends in downtrend = Downtrend resumes
Short = COG = First crossing = Downtrend might end warning
Short = Green Zone = Bars come from lower zones = Downtrend ended take care
Short = Blue Zone = Bars come from lower zones = Strong uptrend -> close short
You can use script alerts in TradingView by clicking the clock in the sidebar, then ‘create alert’ or plus, as condition you choose ‘Tztrader’ in the dialog box, then the “Any alert() function call” option (the first item in the list). The script lets the valid alert trigger by TradingView after the bar is completed, this can differ from the flashed messages during its formation.
When you create alerts in Tradingview, I advice to do that for each setup, then to make only the alert active which matches the current setup, pause the other ones.
Suppressing false and annoying signals
The script has two ways to suppress such signals, which have to do with the numbers in the alert feedback. The numbers left and right of the message with a colored background, depict the zones in which the previous (left) and current (right) bar move. 1 is the strong downtrend zone (red), 2 the moderate downtrend zone (orange), 3 the sideways zones (gray), 4 the COG (gray), 5 the moderate uptrend zone (green), 6 the strong uptrend zone (blue), 7 something went wrong with assigning a zone (black). In extensive testing the number 7 never occurs, because I catch that error in the code. The idea is that an alert is only triggered if the previous bar was in a different zone. When the bars are in the same zone, no alert is possible. This way all annoying signals are suppressed and long, short and bare get the appropriate alerts.
The third number is a counter. It counts how often the COG is crossed without touching the outer curves. The counter will reset to zero when the upper or lower curve is touched. When the count is 1 you have zone situation 4 and appropriate alerts are flashed. When the count is 2 or higher, a sideways situation (3) is called and while the recrossings are going on, no alerts can be flashed. This suppresses false signals. The ATR zone and curves are brownish-gray where sideways happens(ed). When the channel is narrowed down to just the three curves, some false signals still might occur.
Inputs
“Setup”, default is long, drop down menu provides long, short and bare.
“Target ATR”, default is 2, sets the amount of ATR for the target line. In 1 minute charts 4 seems an appropriate setting, you have to learn by experience which setting works.
“show feedback …” default is on, This creates two feedback labels, a Setup feedback on top of the pane, which shows charted instrument, Setup type, Trend and timeframe of the chart. Background color of Trend feedback is green when it matches the setup, red when mismatches and gray when no match. The alert feedback at the bottom of the pane shows a number, a message and two numbers. The numbers will be explained in the chapter about false and annoying signals below. During formation of the bar, valid alerts are flashed with a blue background, otherwise the message ‘alerts for current bar suppressed’.
Logical Stops
The curves are the logical place to put stops, because, as these are averages of the high and low border of a Donchian channel, they signify the ‘natural’ current highest, lowest and main level in the lookback period that fit the monitored trend setup. A downtrend turns into an uptrend when a breakout of the upper curve occurs. If you are short, that is where you want to close position, so the logical place for the stoploss is the upper curve. Vice versa, when you are long, the logical stop is on the lower curve. The stops show up as green or gray dots on the curves, the green dots signify a nice entry level, the gray stops are there to suggest levels where unrealized profits might be secured, the maroon dots indicate that the trend mismatches the setup.
COG versus other lines
Any line used to identify a trend, be it some MA or some other line, is interpreted the same way: When the bars move above the line there is an uptrend and when below, a downtrend. COG is not different in that sense. If you put such a line in the same chart as TZtrader, you can see situations in which the other line shows uptrend or downtrend earlier than COG, also some other lines, e.g. Hull MA, are very good at showing tops and bottoms, while COG ignores these. On the other hand the other lines are usually a little nervous and let you shake out of position too soon. Just like the other lines, COG gives false signals when it is near horizontal. The advantage of the placement COG is the tolerance for pull backs. This way TZtrader keeps you longer in the trend. Such pull backs are often ‘flags’ which are interpreted in TA as confirming the trend. Tztrader aims to get you in position reasonably soon when a trend begins and out of position as soon as the trend turns against you. The placement of COG is done with a fundamentally different algorithm than other lines as it is not an average of prices, but the middle of two averages of borders of a Donchian channel. This gives the two zones between the curves the same quality as the two zones above and below the middle line of a standard Donchian Channel.
A multi timeframe application.
In this scenario you put a 5 minutes and 1 minute chart with Tztrader side by side. If the 5 minutes shows uptrend, set the 1 minute on long trading and open positions when the trend matches uptrend en close when it mismatches. Don’t open short positions. Once the 5 minute changes to downtrend, set Tztrader in the 1 minute to short trading and open positions when the trend matches downtrend and close when it mismatches.
The idea is that in a long ‘context’, provided by the 5 minutes, the uptrends in the 1 minute will last longer and go further, vice versa for the short ‘context’. This way you do swing trading in the 5 minute in a smart way, maximizing profits.
You can do this with any timeframe pairs with a proportion of around 5:1, 4:1, 6:1, like e.g. 60 minutes and 15 minutes or weeks and days (5 trading days in a week).
Dear day-traders, may this tool be helpful and may your days be blessed.
Take care

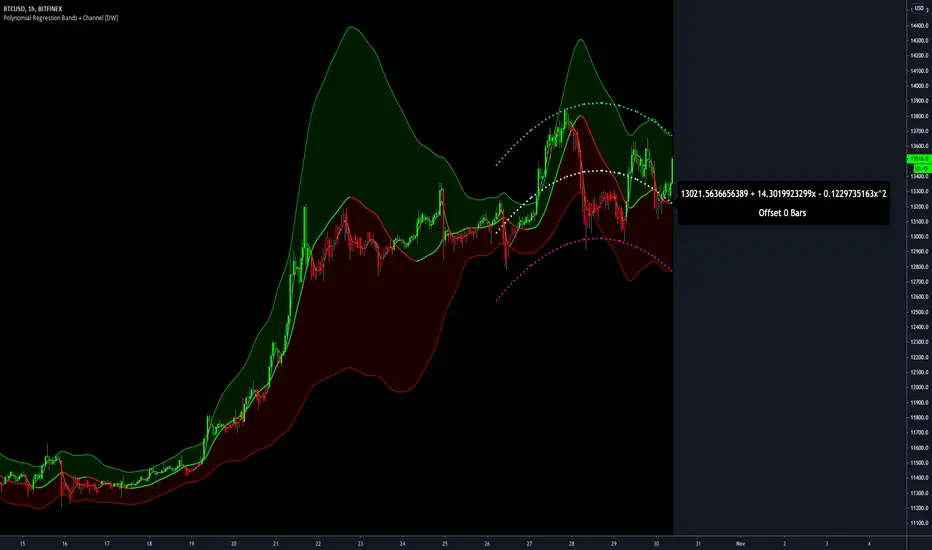
Polynomial Regression Bands + Channel [DW]This is an experimental study designed to calculate polynomial regression for any order polynomial that TV is able to support.
This study aims to educate users on polynomial curve fitting, and the derivation process of Least Squares Moving Averages (LSMAs).
I also designed this study with the intent of showcasing some of the capabilities and potential applications of TV's fantastic new array functions.
Polynomial regression is a form of regression analysis in which the relationship between the independent variable x and the dependent variable y is modeled as a polynomial of nth degree (order).
For clarification, linear regression can also be described as a first order polynomial regression. The process of deriving linear, quadratic, cubic, and higher order polynomial relationships is all the same.
In addition, although deriving a polynomial regression equation results in a nonlinear output, the process of solving for polynomials by least squares is actually a special case of multiple linear regression.
So, just like in multiple linear regression, polynomial regression can be solved in essentially the same way through a system of linear equations.
In this study, you are first given the option to smooth the input data using the 2 pole Super Smoother Filter from John Ehlers.
I chose this specific filter because I find it provides superior smoothing with low lag and fairly clean cutoff. You can, of course, implement your own filter functions to see how they compare if you feel like experimenting.
Filtering noise prior to regression calculation can be useful for providing a more stable estimation since least squares regression can be rather sensitive to noise.
This is especially true on lower sampling lengths and higher degree polynomials since the regression output becomes more "overfit" to the sample data.
Next, data arrays are populated for the x-axis and y-axis values. These are the main datasets utilized in the rest of the calculations.
To keep the calculations more numerically stable for higher periods and orders, the x array is filled with integers 1 through the sampling period rather than using current bar numbers.
This process can be thought of as shifting the origin of the x-axis as new data emerges.
This keeps the axis values significantly lower than the 10k+ bar values, thus maintaining more numerical stability at higher orders and sample lengths.
The data arrays are then used to create a pseudo 2D matrix of x power sums, and a vector of x power*y sums.
These matrices are a representation the system of equations that need to be solved in order to find the regression coefficients.
Below, you'll see some examples of the pattern of equations used to solve for our coefficients represented in augmented matrix form.
For example, the augmented matrix for the system equations required to solve a second order (quadratic) polynomial regression by least squares is formed like this:
(∑x^0 ∑x^1 ∑x^2 | ∑(x^0)y)
(∑x^1 ∑x^2 ∑x^3 | ∑(x^1)y)
(∑x^2 ∑x^3 ∑x^4 | ∑(x^2)y)
The augmented matrix for the third order (cubic) system is formed like this:
(∑x^0 ∑x^1 ∑x^2 ∑x^3 | ∑(x^0)y)
(∑x^1 ∑x^2 ∑x^3 ∑x^4 | ∑(x^1)y)
(∑x^2 ∑x^3 ∑x^4 ∑x^5 | ∑(x^2)y)
(∑x^3 ∑x^4 ∑x^5 ∑x^6 | ∑(x^3)y)
This pattern continues for any n ordered polynomial regression, in which the coefficient matrix is a n + 1 wide square matrix with the last term being ∑x^2n, and the last term of the result vector being ∑(x^n)y.
Thanks to this pattern, it's rather convenient to solve the for our regression coefficients of any nth degree polynomial by a number of different methods.
In this script, I utilize a process known as LU Decomposition to solve for the regression coefficients.
Lower-upper (LU) Decomposition is a neat form of matrix manipulation that expresses a 2D matrix as the product of lower and upper triangular matrices.
This decomposition method is incredibly handy for solving systems of equations, calculating determinants, and inverting matrices.
For a linear system Ax=b, where A is our coefficient matrix, x is our vector of unknowns, and b is our vector of results, LU Decomposition turns our system into LUx=b.
We can then factor this into two separate matrix equations and solve the system using these two simple steps:
1. Solve Ly=b for y, where y is a new vector of unknowns that satisfies the equation, using forward substitution.
2. Solve Ux=y for x using backward substitution. This gives us the values of our original unknowns - in this case, the coefficients for our regression equation.
After solving for the regression coefficients, the values are then plugged into our regression equation:
Y = a0 + a1*x + a1*x^2 + ... + an*x^n, where a() is the ()th coefficient in ascending order and n is the polynomial degree.
From here, an array of curve values for the period based on the current equation is populated, and standard deviation is added to and subtracted from the equation to calculate the channel high and low levels.
The calculated curve values can also be shifted to the left or right using the "Regression Offset" input
Changing the offset parameter will move the curve left for negative values, and right for positive values.
This offset parameter shifts the curve points within our window while using the same equation, allowing you to use offset datapoints on the regression curve to calculate the LSMA and bands.
The curve and channel's appearance is optionally approximated using Pine's v4 line tools to draw segments.
Since there is a limitation on how many lines can be displayed per script, each curve consists of 10 segments with lengths determined by a user defined step size. In total, there are 30 lines displayed at once when active.
By default, the step size is 10, meaning each segment is 10 bars long. This is because the default sampling period is 100, so this step size will show the approximate curve for the entire period.
When adjusting your sampling period, be sure to adjust your step size accordingly when curve drawing is active if you want to see the full approximate curve for the period.
Note that when you have a larger step size, you will see more seemingly "sharp" turning points on the polynomial curve, especially on higher degree polynomials.
The polynomial functions that are calculated are continuous and differentiable across all points. The perceived sharpness is simply due to our limitation on available lines to draw them.
The approximate channel drawings also come equipped with style inputs, so you can control the type, color, and width of the regression, channel high, and channel low curves.
I also included an input to determine if the curves are updated continuously, or only upon the closing of a bar for reduced runtime demands. More about why this is important in the notes below.
For additional reference, I also included the option to display the current regression equation.
This allows you to easily track the polynomial function you're using, and to confirm that the polynomial is properly supported within Pine.
There are some cases that aren't supported properly due to Pine's limitations. More about this in the notes on the bottom.
In addition, I included a line of text beneath the equation to indicate how many bars left or right the calculated curve data is currently shifted.
The display label comes equipped with style editing inputs, so you can control the size, background color, and text color of the equation display.
The Polynomial LSMA, high band, and low band in this script are generated by tracking the current endpoints of the regression, channel high, and channel low curves respectively.
The output of these bands is similar in nature to Bollinger Bands, but with an obviously different derivation process.
By displaying the LSMA and bands in tandem with the polynomial channel, it's easy to visualize how LSMAs are derived, and how the process that goes into them is drastically different from a typical moving average.
The main difference between LSMA and other MAs is that LSMA is showing the value of the regression curve on the current bar, which is the result of a modelled relationship between x and the expected value of y.
With other MA / filter types, they are typically just averaging or frequency filtering the samples. This is an important distinction in interpretation. However, both can be applied similarly when trading.
An important distinction with the LSMA in this script is that since we can model higher degree polynomial relationships, the LSMA here is not limited to only linear as it is in TV's built in LSMA.
Bar colors are also included in this script. The color scheme is based on disparity between source and the LSMA.
This script is a great study for educating yourself on the process that goes into polynomial regression, as well as one of the many processes computers utilize to solve systems of equations.
Also, the Polynomial LSMA and bands are great components to try implementing into your own analysis setup.
I hope you all enjoy it!
--------------------------------------------------------
NOTES:
- Even though the algorithm used in this script can be implemented to find any order polynomial relationship, TV has a limit on the significant figures for its floating point outputs.
This means that as you increase your sampling period and / or polynomial order, some higher order coefficients will be output as 0 due to floating point round-off.
There is currently no viable workaround for this issue since there isn't a way to calculate more significant figures than the limit.
However, in my humble opinion, fitting a polynomial higher than cubic to most time series data is "overkill" due to bias-variance tradeoff.
Although, this tradeoff is also dependent on the sampling period. Keep that in mind. A good rule of thumb is to aim for a nice "middle ground" between bias and variance.
If TV ever chooses to expand its significant figure limits, then it will be possible to accurately calculate even higher order polynomials and periods if you feel the desire to do so.
To test if your polynomial is properly supported within Pine's constraints, check the equation label.
If you see a coefficient value of 0 in front of any of the x values, reduce your period and / or polynomial order.
- Although this algorithm has less computational complexity than most other linear system solving methods, this script itself can still be rather demanding on runtime resources - especially when drawing the curves.
In the event you find your current configuration is throwing back an error saying that the calculation takes too long, there are a few things you can try:
-> Refresh your chart or hide and unhide the indicator.
The runtime environment on TV is very dynamic and the allocation of available memory varies with collective server usage.
By refreshing, you can often get it to process since you're basically just waiting for your allotment to increase. This method works well in a lot of cases.
-> Change the curve update frequency to "Close Only".
If you've tried refreshing multiple times and still have the error, your configuration may simply be too demanding of resources.
v4 drawing objects, most notably lines, can be highly taxing on the servers. That's why Pine has a limit on how many can be displayed in the first place.
By limiting the curve updates to only bar closes, this will significantly reduce the runtime needs of the lines since they will only be calculated once per bar.
Note that doing this will only limit the visual output of the curve segments. It has no impact on regression calculation, equation display, or LSMA and band displays.
-> Uncheck the display boxes for the drawing objects.
If you still have troubles after trying the above options, then simply stop displaying the curve - unless it's important to you.
As I mentioned, v4 drawing objects can be rather resource intensive. So a simple fix that often works when other things fail is to just stop them from being displayed.
-> Reduce sampling period, polynomial order, or curve drawing step size.
If you're having runtime errors and don't want to sacrifice the curve drawings, then you'll need to reduce the calculation complexity.
If you're using a large sampling period, or high order polynomial, the operational complexity becomes significantly higher than lower periods and orders.
When you have larger step sizes, more historical referencing is used for x-axis locations, which does have an impact as well.
By reducing these parameters, the runtime issue will often be solved.
Another important detail to note with this is that you may have configurations that work just fine in real time, but struggle to load properly in replay mode.
This is because the replay framework also requires its own allotment of runtime, so that must be taken into consideration as well.
- Please note that the line and label objects are reprinted as new data emerges. That's simply the nature of drawing objects vs standard plots.
I do not recommend or endorse basing your trading decisions based on the drawn curve. That component is merely to serve as a visual reference of the current polynomial relationship.
No repainting occurs with the Polynomial LSMA and bands though. Once the bar is closed, that bar's calculated values are set.
So when using the LSMA and bands for trading purposes, you can rest easy knowing that history won't change on you when you come back to view them.
- For those who intend on utilizing or modifying the functions and calculations in this script for their own scripts, I included debug dialogues in the script for all of the arrays to make the process easier.
To use the debugs, see the "Debugs" section at the bottom. All dialogues are commented out by default.
The debugs are displayed using label objects. By default, I have them all located to the right of current price.
If you wish to display multiple debugs at once, it will be up to you to decide on display locations at your leisure.
When using the debugs, I recommend commenting out the other drawing objects (or even all plots) in the script to prevent runtime issues and overlapping displays.
TrendZonesTrendZones
This is an indicator which I use, have tested, tweaked and added features to for use in my trend following investing system. I got the idea for it when for some reason I was looking for a dynamic reference to measure the height of a channel or something. In search of this I made MA’s of the high and low borders of a Donchian channel which turned out to be two near parallel and stunningly smooth curves. This visual was so appealing that I immediately tried to turn it into a replacement for the KeltCOG which I previously used in my system. First I created a curve in the middle of the upper and lower curves, which I called COG (Center Of Gravity). Then I decided to enter only one lookback and let the script create a Donchian channel with half the lookback and use this to create the curves with an MA of whole lookback. For this reason the minimum lookback is set to 14, enough room for the Donchian Channel of 7 periods. This Donchian ChanneI has a special way of calculating the borders, involving a 5 period Median value. Thanks to this these borders are really a resistance and support level, which won’t change at a whim, e.g. when a ‘dead cat bounce’ occurs. I prevented the Donchian channel to show itself between the curves and only pop out from behind these. These pop outs now function as “strong trend zones”. I gave it colors (blue:-strong up, green: moderate up, orange: moderate down, red: strong down, near COG: gray, curves horizontal: gray) and it looked very appealing. I tested it in different time frames. In some weekend, when I was bored, I observed for a few hours the minute chart of bitcoin. It turned out that you can reliably tell that an uptrend ends when the candles go under the COG beginning a downtrend. Uptrend starts again once the candles go above COG. As Trends on minute charts only last around half an hour, this entertainment made the potential of this indicator very clear to me in just one afternoon.
Risk Management, Safe Level and Logical Stops.
In the inputs are settings for “Risk Tolerance”, and to activate “Show Logical Stop Level” (activated in example chart) and “Show Safe Level”. As a rule of thump a trade should not expose the invested capital to a risk of losing more than 2 percent. I divided my investment capital in ten equal parts which are allocated to ten different stocks or other instruments or kept liquid. This means that when a position is closed by triggering a Stop with a loss of 20 percent, the invested capital suffers only 2 percent (20% x 10% = 2%). This is why the value for “Risk Tolerance” has a default of 20. Because I put my Stops on the lower curve, a “Safe Level” can be calculated such that when you buy for a price below or at this level, the stop will protect the position sufficiently. Because I only buy when the instrument is in uptrend, the buying price should be between COG and Safe Level. Although I never do that, putting the stop at other curves is feasible and when you want to widen the stop (I never lower my stops btw) in a downtrend situation, even 1 ATR below the “Low Border”. I call these “Logical Stop Levels”, marked with dark green circles on the lower curve when safe buying by placing the Stoploss on this curve is possible, gray circles on the other curves, on the Upper Curve navy when price enters very profitable level. In a downtrend situation maroon circles appear.
Target lines
When I open a position I always set a Stoploss and a Target, for this purpose two types of Target values can be set and corresponding Target lines activated. These lines are drawn above the “High Border” at the set distance. If one expects some price to be used, differences will occur.
Other Features
Support Zone, this is 1 ATR below the “Low Border”, the maroon circles of the “Logal Stops” are placed on this “Support level”.
Stop distance and Channel Width. (activated in example chart) These are reported in a two cell table in the right lower corner of the main panel. I created this because I want to be able to check the volatility, whether the channel shows a situation in which safe buying in most levels of the channel is possible or what risk you take when you buy now and set the Stop at the nearest logical level (which is not always the “Lower curve”). This feature comes in handy for creating a setup I propose in the “Day Trading Fantasy” below.
Some General and User Settings. I never activate this, perhaps you will.
Use Of TrendZones In My System.
Create a list of stocks in uptrend. I define ‘stock in uptrend’ as in uptrend zone in all three monthly, weekly and daily charts, all three should at the same time be in uptrend. The advantage of TrendZones is that you can immediately see in which zone the candle moves.
Opening a position in a stock from the above list. I do this only when in both the daily and weekly the green dot on the lower curve indicates a buying opportunity. This is usually not the case in most of the items of the list, this feature thus provides a good timing for opening a position. Sometimes you need to wait a few weeks for this to happen.
Setting a target over a position. For this I use the Target percent line of the weekly chart with the default value of 10.
Updating the Stoploss and Target values. Every week or two weeks I set these to the new values of the “Lower Curve” and the Target line of the weekly. Attention: never shift down Stops, only up or let them stay the same when the curve moves down. I never use Stop levels on other curves.
I Check the charts whenever I like to do this. Close the position when the uptrend obviously shifts down. Otherwise I let the profits run until the Target triggers which closes the position with some profit.
For selecting stocks an checking charts for volume events, I also use a subpanel indicator called “TZanalyser”, which borrows the visual of my “Fibonacci Zone Oscillator”, is based on TrendZones and includes code from my REVE indicators. I intend to publish that as well.
Day Trading Fantasy.
Day trading is an attempt to earn a dime by opening a position in the morning and close it during the day again with a profit (or a loss). Before the market closes, you close all day trading positions.
In my fantasy the “Logical Stop Level” is repurposed for use as entry point and the ATR-based Target line is used to provide a target setting in an intraday chart, like e.g. 15 minute. To do this the “Safe Level” should be limited to between Channel width and COG. This can be done by showing “Safe Level” and “Channel Width” and then set “Risk Tolerance” to around the shown Channel Width. In this setting you can then wait for the green circle to show up for entering your trade and protect it with the stop.
I don’t know if this works fine or if it’s better than other day trade systems, because I don’t do day trading.
Take care and have fun.

Sigmoid Allocation Indicator & DashboardTL;DR This sigmoid-based allocation indicator tells you percentage of your portfolio to invest based on how much the market has dropped.
Market at all-time high? → Stay defensive, invest less (e.g., 30%)
Market crashed hard? → Get aggressive, invest more (e.g., 100%)
The "sigmoid" part just means the transition between these two extremes follows a smooth S-shaped curve.
Description
This indicator is a sigmoid-based allocation system that dynamically adjusts a portfolio exposure based on market drawdown.
It compares multiple steepness curves (K values) to find your optimal risk profile for leveraged ETF strategies, but it can also be used to scale in-out from stocks, crypto and to understand whether to use leverage or not.
The Sigmoid Allocation Dashboard helps you to dynamically adjust a portfolio allocation based on how much a market has dropped from its all-time high.
I've implemented it using a sigmoid (S-curve) function, that dynamically calculates the optimal allocation percentages. Depending on the market conditions, the S curves transition between defensive and aggressive allocations.
The Math Behind It (if you are a geek like me)
This indicator uses the sigmoid function to create smooth S-curve transitions:
α(D) = α_min + (α_max - α_min) × σ(k × (D - D_mid))
Where:
σ(x) = 1 / (1 + e^(-x)) ← Standard sigmoid function
You can also check it here:
// Sigmoid function: σ(x) = 1 / (1 + e^(-x))
sigmoid(float x) =>
1.0 / (1.0 + math.exp(-x))
// Alpha calculation: α(D) = α_min + (α_max - α_min) × σ(k × (D - D_mid))
calcAlpha(float drawdown, float k, float a_min, float a_max, float d_midpoint) =>
sig_input = k * (drawdown - d_midpoint) / 100.0
a_min + (a_max - a_min) * sigmoid(sig_input)
User parameters (you can tweak this):
Allocation Min (%): Your baseline allocation when markets are at ATH (default: 30%)
Allocation Max (%): Your maximum allocation during deep drawdowns (default: 100%)
D_mid (%): The drawdown level where you want to be at the midpoint (default: 25%)
Why do I like sigmoid and not a linear line?
Unlike linear models, the sigmoid creates "floors" and "ceilings" for your allocation. It transitions smoothly, no sudden jumps, and you never exceed your defined min/max bounds.
Understand the K Values (Steepness)
The K parameter controls how quickly your allocation shifts from defensive to aggressive.
Lower K (for example K=5) will give you a gradual transition, but at 0% drawdown you are already at a 46% allocation.
A higher like (like K=40) will give you a sharp transition, but at 0% drawdown you are close to the minimum allocation. On the other hand, a higher K will give close to 100% allocation when the markets are at new lows.
The example below illustrates this well, then the S&P 500 reached new lows in October 2022:
Different K values will affect the sigmoid curves (and you allocations differently). The chart below illustrates well how K affects the sigmoid curves:
Read the Dashboard
The main dashboard shows:
Current drawdown from ATH
Allocation % for each K value
Suggested action (Defensive → MAX LONG)
Use the Reference Chart
The static reference panel shows what your allocation would be at various drawdown levels (0%, 10%, 20%, 30%, 40%, 50%), helping you plan ahead.
Identify Zones
The color-coded chart background shows:
- 🟢 Green Zone: Aggressive positioning - "Buy the Dip"
- 🟡 Yellow Zone: Transition zone - Scaling in/out
- 🔴 Red Zone: Defensive positioning - Protect ya gains
Use Cases
Use case 1: Leveraged ETF Portfolio Management (this is my main use case)
When holding leveraged ETFs like TQQQ or UPRO, volatility makes it important to:
- Reduce exposure near all-time highs (when crashes hurt most)
- Increase exposure during drawdowns (when recovery potential is highest)
Example Strategy:
- At ATH: Hold 30% TQQQ, 70% cash/bonds or other uncorrelated assets
- At 25% drawdown: Hold 65% TQQQ, 35% cash/bonds
- At 40%+ drawdown: Hold 100% TQQQ
Use case 2: Diversified Leveraged Portfolio
Compare different K values for different assets:
- Use K = 10 for broad market (QQQ/SPY exposure via TQQQ/UPRO)
- Use K = 25 for sector bets (TECL, SOXL, TMF) that you want to scale into faster
Use case 3: Systematic Rebalancing Signals
Use the alerts to trigger rebalancing:
- Alert when K3 allocation crosses above 90% (time to add)
- Alert when drawdown exceeds your D_mid threshold
- Alert when market returns to within 5% of ATH
Tips for Best Results
It works best in longer time frames
Adjust the ATR lookback window
Match your risk tolerance level
I use this for index investing and stocks and haven't tried with crypto
Thanks for using the indicator and let me know if you have any feedback :)
- Henrique Centieiro

Linear Regression AngleThere are several Linear Regression indicator in the Public Library, but I don't think there is one that converts the Linear Regression (LR) curve into angle in degrees, relative to a set reference frame. Due to the large price range between tickers, creating this indicator isn't as straight forward as I originally thought. For example, given the same time period, a stock that fluctuate in the 10's will have a true linear regression angle dramatically different from a penny stock. Even changing the scale on your chart will affect the "apparent" angle you see on the chart. Hence, this indicator DOES NOT provide the true linear regression angle, but only a relative one based on a defined number of historical bars.
Originality and usefulness
This indicator provides Linear Regression (LR) Angle in degree that may be more easily interpreted by some traders as we are more accustomed to line angles in degree and know how to visualize them.
This script also provides the option to overlay up to four LR curves of different periods, as well as an average curve of the enabled curves. This allows traders to analysis short to long term trends.
Furthermore, slope (rate of change) of each LR curves can be toggled. The slope plot can help traders visualize accelerations and decelerations of the LR curves which may help in spotting trend reversals.
Data table provides real time data for each curve.
Example of using slope plot with a 30 bars Linear Regression Angle:

Historical Returns [BigBeluga]🔵 OVERVIEW
The Historical Returns indicator visualizes daily and monthly return data to help traders assess seasonal performance and volatility behavior. It provides a clean and informative dashboard showing the current month’s daily return bubbles, monthly return curves, and a snapshot of the current month and year performance. This tool is ideal for spotting recurring return patterns and understanding the broader profitability context of a symbol.
🔵 CONCEPTS
Daily Return Bubbles: Each trading day is analyzed for its return percentage, and plotted as a bubble with size proportional to the return magnitude.
Monthly Performance Curves: Average or cumulative returns are calculated and plotted to show how the current month is performing relative to historical averages.
Current Year Return: Current year performance as a single return value, giving traders context on long-term profitability.
Current Month Average Return: Current month average performance as a single return value, giving traders context on short-term profitability.
Extreme Return Labels: Optionally highlights daily returns above +4% or below -4% with labeled percentages for spike recognition.
🔵 FEATURES
Shows daily return bubbles (1%–7%+), color-coded by direction.
Labels monthly returns with the month name and percentage value.
Displays a performance dashboard with:
Daily return heatmap for the current month.
Average return for the current month.
Year-to-date return.
Toggle between average and cumulative modes for monthly return curves.
Clearly marks days with abnormal return spikes using optional labels.
Clean fallback warning if not on a daily chart ("⚠️USE DAILY TIMEFRAME").
Custom color themes for bullish and bearish values.
🔵 HOW TO USE
Use the monthly return curve to compare how the current month is performing against historical averages.
Look for clusters of positive or negative bubbles as signals of strong directional weeks.
Watch extreme return labels for volatility spikes or catalyst days.
Use year-to-date return to assess how the asset is trending in the broader macro cycle.
Combine with other BigBeluga tools to align trades with historically favorable periods.
🔵 CONCLUSION
Historical Returns is your visual companion for return analytics — helping you identify profitable months, detect volatility surges, and understand historical seasonality at a glance. With a clean dashboard and insightful overlays, this tool supports better timing and improved statistical edge in both short- and long-term trades.

Buy And Hold Performance Screener - [JTCAPITAL]Buy And Hold Performance Screener – is a script designed to track and display multi-asset “buy and hold” performance curves and performance statistics over defined timeframes for selected symbols. It doesn’t attempt to time entries or exits; rather, it shows what would happen if one simply bought the asset at the defined start date and held it.
The indicator works by calculating in the following steps:
Start Date Definition
The script begins by reading an input for the start date. This defines the bar from which the equity curves begin.
Symbol Definitions & Close Price Retrieval
The script allows the user to specify up to ten tickers. For each ticker it uses request.security() on the “1D” timeframe to retrieve the daily close price of that symbol.
Plot Enable Inputs
For each ticker there is an input boolean controlling whether the equity curve for that ticker should be plotted.
Asset Name Cleaning
The helper function clean_name(string asset) => … takes the asset string (e.g., “CRYPTO:SOLUSD”) and manipulates it (via string splitting and replacements) to derive a cleaned short name (e.g., “SOL”). This name is used for visuals (labels, table headers).
Equity Curve Calculation (“HODL”)
The helper function f_HODL(closez) defines a variable equity that assumes a starting equity of 1 unit at the start date and then multiplies by the ratio of each bar’s close to the prior bar’s close: i.e. daily compounding of returns.
Performance Metrics Calculation
The helper function f_performance(closez) calculates, for each symbol’s close series, the percentage change of the current close relative to its close 30 days ago, 90 days ago, 180 days ago, 1 year ago (365 days), 2 years ago (730 days) and 3 years ago (1095 days).
Equity Curve Plots
For each ticker, if the corresponding plot input is true, the script assigns a plotted variable equal to the equity curve value. Its then drawing each selected equity curve on the chart, each in a distinct color.
Table Construction
If the plottable input is true, the script constructs a table and populates it with rows and column corresponding to the assigned tickers and the set 6 timeframes used for display.
Buy and Sell Conditions:
Since this is strictly a “buy-and-hold” performance screener, there are no explicit buy or sell signals generated or plotted. The script assumes: buy at the defined start_date, hold continuously to present. There are no filters, no exit logic, no take-profit or stop-loss. The benefit of this approach is to provide a clean benchmark of how selected assets would have performed if one simply adopted a passive “buy & hold” approach from a given start date.
Features and Parameters:
start_date (input.time) : Defines the date from which performance and equity curves begin.
ticker1 … ticker10 (input.symbol) : User-selectable asset symbols to include in the screener.
plot1 … plot10 (input.bool) : Boolean flags to enable/disable plotting of each asset’s equity curve.
plottable (input.bool) : Flag to enable/disable drawing the performance table.
Colored plotting + Labels for identifying each asset curve on the chart.
Specifications:
Here is a detailed breakdown of every calculation/variable/function used in the script and what each part means:
start_date
This is defined via input.time(timestamp("1 Jan 2025"), title = "Start Date"). It allows the user to pick a specific calendar date from which the equity curves and performance calculations will start.
ticker1 … ticker10
These inputs allow the user to select up to ten different assets (symbols) to monitor. The script uses each of these to fetch daily close prices.
plot1 … plot10
Boolean inputs controlling which of the ten asset equity curves are plotted. If plotX is true, the equity curve for ticker X will be visible; otherwise it will be not plotted. This gives the user flexibility to include or exclude specific assets on the chart.
Returns the cleaned asset short name.
This provides friendly text labels like “BTC”, “ETH”, “SOL”, etc., instead of full symbol codes.
The choice of distinct colours for each asset helps differentiate curves visually when multiple assets are overlaid.
Colour definitions
Variables color1…color10 are explicitly defined via color.rgb(r,g,b) to give each asset a unique colour (e.g., red, orange, yellow, green, cyan, blue, purple, pink, etc.).
What are the benefits of combining these calculations?
By computing equity curves for multiple assets from the same start date and overlaying them, you can visualise comparative performance of different assets under a uniform “buy & hold” assumption.
The performance table adds multi-horizon returns (30 D, 90 D, 180 D, 1 Y, 2 Y, 3 Y) which helps the user see both short-term and longer-term performance without having to manually compute returns.
The use of daily close data via request.security(..., "1D") removes dependency on the chart’s timeframe, thereby standardising the comparison across assets.
The equity curve and table together provide both visual (curve) and numerical (table) summaries of performance, making it easier to spot trends, divergences, and cross-asset comparisons at a glance.
Because it uses compounding (equity := equity * (closez / closez )), the curves reflect the real growth of a 1-unit investment held over time, rather than only simple returns.
The labelling of curves and the color-coding make the multi-asset overlay easier to interpret.
Using a clean start date ensures that all curves begin at the same point (1 unit at start_date), making relative performance intuitive.
Because of this, the script is useful as a benchmarking tool: rather than trying to pick entries or exit points, you can simply compare “what if I had held these assets since Jan 1 2025” (or your chosen date), and see which assets out-/under-performed in that period. It helps an investor or trader evaluate the long-term benefits of passive vs. active management, or of allocation decisions.
Please note:
The script assumes continuous daily data and does not account for dividends, fees, slippage, or tax implications.
It does not attempt to optimise timing or provide trading signals.
Returns prior to the start date are ignored (equity only begins once time >= start_date).
For newly listed assets with fewer than 365 or 730 or 1095 days of history, the longer-horizon returns may return na or misleading values.
Because it uses request.security() without specifying lookahead, and on “1D” timeframe, it complies with standard usage but you should verify there is no look-ahead bias in your particular setup.
ENJOY!