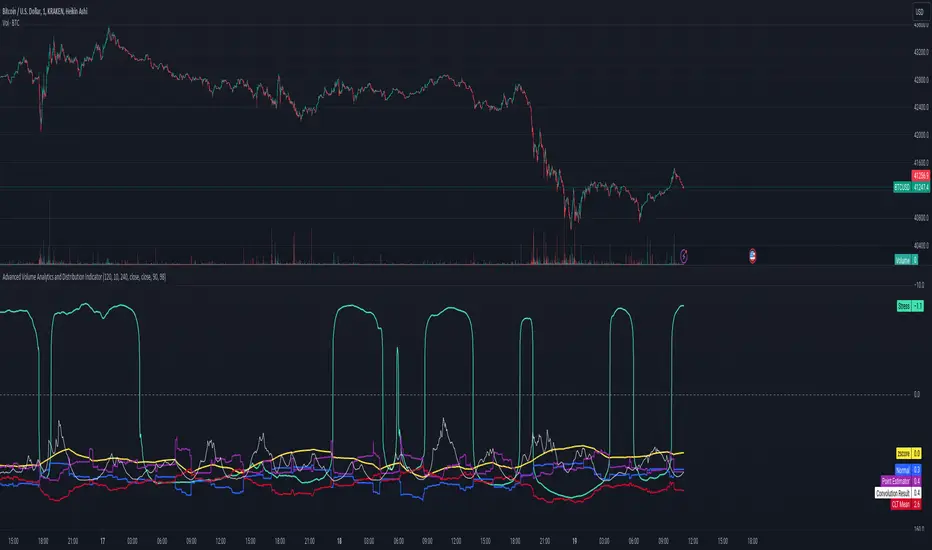
Advanced Volume Analytics and Distribution IndicatorThe Advanced Volume Analytics and Distribution Indicator is a sophisticated tool designed for financial analysts and traders who seek in-depth insights into market volume dynamics. This Pine Script-based indicator is a comprehensive solution, offering a rich set of features that analyze volume data using various statistical methods and theories. It's tailored for those who require a deeper understanding of market movements and volume distribution.
Key Features:
Volume Distribution Analysis: Utilizes standard deviation and mean calculations to analyze the distribution of trading volume. Employs z-scores to measure the standard deviations of volume from its mean, offering insights into volume anomalies.
Bell Curve Modeling: Constructs a bell curve (normal distribution) based on volume data, enabling users to visualize and assess the distribution of volume in a standard statistical format.
Provides a z-score based bell curve, offering a normalized view of volume deviations.
Exponential Smoothing: Applies exponential smoothing to volume data, giving more weight to recent observations. This feature is crucial for analyzing trending behaviors in volume data.
Stress Metric Calculation: Introduces a unique 'stress' metric, calculated using a custom formula. This metric is designed to evaluate the volatility or variability in the volume data over a specified period.
Central Limit Theorem (CLT) Mean Estimation: Implements CLT for estimating the mean of volume data. The CLT states that the distribution of sample means approximates a normal distribution as the sample size becomes larger.
Variance Point Estimation: Calculates the variance of volume data, providing insights into its variability and consistency over time.
Chi-Squared Test (Commented): Although not active in the initial release, the script includes a framework for a Chi-Squared Test to compare observed and expected volume frequencies, offering potential for future statistical comparisons.
Percentile Calculations and Convolution: Performs percentile calculations on volume data and employs convolution to these percentiles, enabling a more nuanced analysis of volume distribution.
Customizability: Users can input various parameters like anchor period, degrees of freedom, and smoothing preferences, making the tool adaptable to different analysis needs.
Visualization and Plotting: Features multiple plots for easy visualization of volume metrics, including stress, bell curves, point estimators, and smoothed data.
Theoretical Foundations:
This indicator is grounded in established statistical theories and methods, including the Central Limit Theorem, Chi-Squared Test (for future implementations), and convolution techniques. These foundations ensure that the indicator not only provides practical insights but also maintains a high standard of statistical rigor.
Intended Users:
This indicator is ideal for technical analysts, traders, and financial professionals who require a deep and statistically sound understanding of market volume behavior.
Release Notes:
This tool is designed a theoretical test of established statistical models and requires familiarity with Pine Script for customization. Future updates may include activation and expansion of the Chi-Squared Test functionality and additional statistical modules based on user feedback. It should be noted that it is advisable to use a logarithmic-inverted scale; when combined, these scales can provide a unique perspective that neither could offer alone. This combination might be particularly useful in highlighting exponential growth or decay trends, or in cases where the most significant data points are in the lower range of the dataset.
Notes of Stress Calculations:
The "stress metric" in the script is a custom-designed feature intended to measure the level of variability or volatility in the volume data over a given time period. This metric is calculated using a novel approach with concepts similar to those used in the field of engineering , particularly in stress analysis and finite element analysis (FEA).
Segmentation of Time Frame:
The script divides the given time frame (timeFrame) into smaller segments based on a specified number of units (units). This segmentation essentially breaks down the entire period into smaller, more manageable intervals for analysis. For each segment, the script calculates a 'stress' value. This involves iterating through each segment and performing calculations based on the source data (src), the default src is the volume data.
Calculation per Segment:
For each segment, the script identifies two points: the starting point (x1) and the ending point (x2). It then retrieves the corresponding values of the source data at these points (y1 and y2).
It calculates the difference in the x-axis (delta_x, the length of the segment) and the difference in the y-axis (delta_y, the change in volume over that segment).
Stress Calculation:
The script then calculates the 'stress' for each segment as the ratio of delta_y to delta_x. This ratio gives a measure of how much the volume has changed per unit of time within each segment. The stress values for each segment are then summed up to provide a cumulative measure of stress over the entire time frame.
The stress metric is essentially a measure of the volatility or variability in volume data. High stress values indicate larger changes in volume over shorter periods, suggesting more volatile market conditions. For traders and analysts, understanding the level of volatility is crucial. It can inform decision-making processes, risk management strategies, and provide insights into market sentiment. By comparing stress levels across different time frames or different securities, analysts can gain insights into relative market dynamics.
在腳本中搜尋"curve"
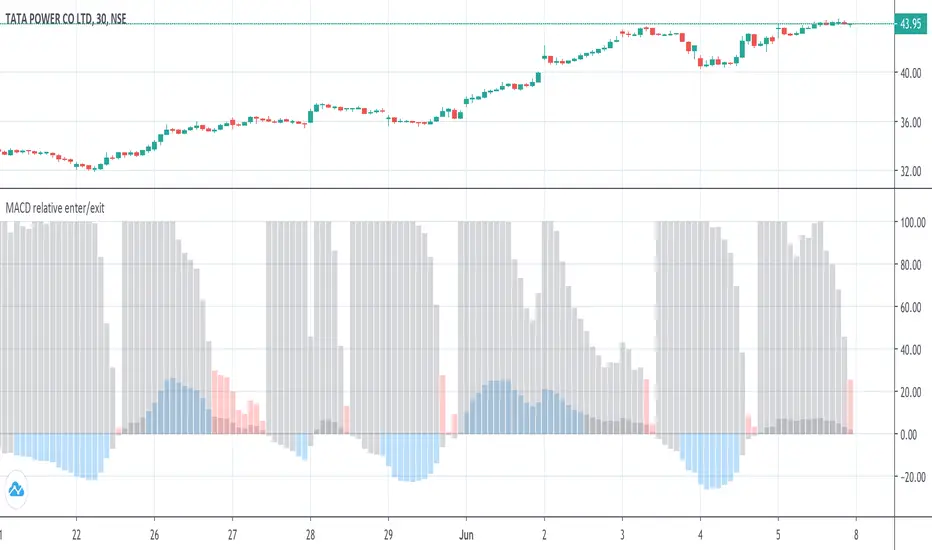
MACD histogram relative open/closePrelude
This script makes it easy to capture MACD Histogram open/close for automated trading.
There seems to be no "magic" value for MACD Histogram that always works as a cut-off for trade entry/exit, because of the variation in market price over time.
The idea behind this script is to replicate the view of the MACD graph we (humans) see on the screen, in mathematics, so the computer can approximately detect when the curve is opening/closing.
Math
The maths for this is composed of 2 sections -
1. Entry -
i. To trigger entry, we normalize the Histogram value by first determining the lowest and highest values on the MACD curves (MACD, Signal & Hist).
ii. The lowest and highest values are taken over the "Frame of reference" which is a hyperparameter.
iii. Once the frame of reference is determined, the entry cutoff param can be defined with respect to the values from (i) (10% by default)
2. Exit
To trigger an exit, a trader searches for the point where the Histogram starts to drop "steeply".
To convert the notion of "steep" into mathematics -
i. Take the max histogram value reached since last MACD curve flip
ii. Define the cutoff with reference to the value from (i) (30% by default)
Plots
Gray - Dead region
Blue - Histogram opening
Red - Histogram is closing
Notes
A good value for the frame of reference can be estimated by looking at the timescale of the graph you generally work with during manual trading.
For me, that turned out to be ~2.5 hours. (as shown in the above graph)
For a 3-minute ticker, frame of reference = 2.5 * 60 / 3 = 50
Which is the default given in this script.
Ultimately, it is up to you to do grid search and find these hyperparams for the stock and ticker size you're working with.
Also, this script only serves the purpose of detecting the Histogram curve opening/closing.
You may want to add further checks to perform proper trading using MACD.
Dynamic Flow Ribbon [Adaptive]The Dynamic Flow Ribbon is a next-generation trend-following tool designed to solve the two biggest problems traders face: Lag and Noise .
Unlike traditional Moving Averages (SMA/EMA) that are often too slow to catch reversals or too sensitive to chop, this indicator utilizes Rational Quadratic Kernel Smoothing . This advanced mathematical approach creates a "Flow Ribbon" that hugs price action tightly during trends while remaining silky smooth, filtering out the random noise that leads to false signals.
This is not just a crossover indicator; it is a complete Market Regime Detector . It automatically identifies when the market is trending and when it is ranging, helping you stay out of dangerous "chop" zones.
Why Use This?
Zero-Lag Smoothing: Experience the responsiveness of a fast EMA with the smoothness of a slow SMA.
Chop Filter: The ribbon automatically turns Gray when volatility (ADX) drops, signaling you to sit on your hands and preserve capital.
Visual Clarity: No messy lines. Just a clean, glowing ribbon that tells you the trend direction instantly.
How It Works
The indicator calculates two dynamic curves:
Fast Flow Line: Tracks immediate price action using a tight kernel window.
Base Flow Line: A slower, weighted baseline that acts as the trend anchor.
The Ribbon: The space between these lines forms the "Ribbon."
Green (Bullish): Fast Flow > Base Flow. The trend is Up.
Red (Bearish): Fast Flow < Base Flow. The trend is Down.
Gray (Flat): Volatility is too low (ADX < Threshold). The market is sideways.
How to Trade
This tool is best used for Trend Continuation and Reversal Catching .
The Entry: Wait for a Crossover Signal (Small Circle).
Buy when the Ribbon flips Green.
Sell when the Ribbon flips Red.
The Filter: If the Ribbon is Gray , ignore all signals. This prevents you from getting whipsawed in a ranging market.
The Exit: You can ride the trend until the Ribbon flips color, or use your own support/resistance targets.
Settings
Bandwidth (Smoothness): Adjusts the sensitivity of the kernel. Higher values = smoother ribbon (better for swing trading). Lower values = faster reaction (better for scalping).
Trend Filter: Toggle the ADX-based chop filter on/off.
Visuals: Fully customizable colors to match your chart aesthetic.
Pro Tip: Combine for Maximum Accuracy
While the Dynamic Flow Ribbon is excellent for Trend Direction, it does not plot Support & Resistance levels.
For the ultimate trading setup, I highly recommend pairing this with my AIO Pivot Master
or any other pivot indicator, which you can easily find on TradingView.
Use Dynamic Flow to determine the Direction .
Use AIO Pivot Master to find your Entry and Exit targets .
Disclaimer
For Educational and Informational Purposes Only
This indicator is provided for educational and informational purposes only and DOES NOT constitute financial, investment, or trading advice. It does not predict future market movements with certainty.
Risk Warning
Trading in financial markets (Stocks, Crypto, Futures, Forex, etc.) involves a high degree of risk and may not be suitable for all investors. You could lose some or all of your initial investment. Past performance of any trading system or methodology is not necessarily indicative of future results.
No Liability
The author of this script assumes no responsibility or liability for any errors or omissions in the content of this indicator, or for any trading losses or damages incurred as a result of using this tool. Users are solely responsible for their own trading decisions and should always use proper risk management. By using this script, you acknowledge and agree to these terms.

Ultimate RSI [captainua]Ultimate RSI
Overview
This indicator combines multiple RSI calculations with volume analysis, divergence detection, and trend filtering to provide a comprehensive RSI-based trading system. The script calculates RSI using three different periods (6, 14, 24) and applies various smoothing methods to reduce noise while maintaining responsiveness. The combination of these features creates a multi-layered confirmation system that reduces false signals by requiring alignment across multiple indicators and timeframes.
The script includes optimized configuration presets for instant setup: Scalping, Day Trading, Swing Trading, and Position Trading. Simply select a preset to instantly configure all settings for your trading style, or use Custom mode for full manual control. All settings include automatic input validation to prevent configuration errors and ensure optimal performance.
Configuration Presets
The script includes preset configurations optimized for different trading styles, allowing you to instantly configure the indicator for your preferred trading approach. Simply select a preset from the "Configuration Preset" dropdown menu:
- Scalping: Optimized for fast-paced trading with shorter RSI periods (4, 7, 9) and minimal smoothing. Noise reduction is automatically disabled, and momentum confirmation is disabled to allow faster signal generation. Designed for quick entries and exits in volatile markets.
- Day Trading: Balanced configuration for intraday trading with moderate RSI periods (6, 9, 14) and light smoothing. Momentum confirmation is enabled for better signal quality. Ideal for day trading strategies requiring timely but accurate signals.
- Swing Trading: Configured for medium-term positions with standard RSI periods (14, 14, 21) and moderate smoothing. Provides smoother signals suitable for swing trading timeframes. All noise reduction features remain active.
- Position Trading: Optimized for longer-term trades with extended RSI periods (24, 21, 28) and heavier smoothing. Filters are configured for highest-quality signals. Best for position traders holding trades over multiple days or weeks.
- Custom: Full manual control over all settings. All input parameters are available for complete customization. This is the default mode and maintains full backward compatibility with previous versions.
When a preset is selected, it automatically adjusts RSI periods, smoothing lengths, and filter settings to match the trading style. The preset configurations ensure optimal settings are applied instantly, eliminating the need for manual configuration. All settings can still be manually overridden if needed, providing flexibility while maintaining ease of use.
Input Validation and Error Prevention
The script includes comprehensive input validation to prevent configuration errors:
- Cross-Input Validation: Smoothing lengths are automatically validated to ensure they are always less than their corresponding RSI period length. If you set a smoothing length greater than or equal to the RSI length, the script automatically adjusts it to (RSI Length - 1). This prevents logical errors and ensures valid configurations.
- Input Range Validation: All numeric inputs have minimum and maximum value constraints enforced by TradingView's input system, preventing invalid parameter values.
- Smart Defaults: Preset configurations use validated default values that are tested and optimized for each trading style. When switching between presets, all related settings are automatically updated to maintain consistency.
Core Calculations
Multi-Period RSI:
The script calculates RSI using the standard Wilder's RSI formula: RSI = 100 - (100 / (1 + RS)), where RS = Average Gain / Average Loss over the specified period. Three separate RSI calculations run simultaneously:
- RSI(6): Uses 6-period lookback for high sensitivity to recent price changes, useful for scalping and early signal detection
- RSI(14): Standard 14-period RSI for balanced analysis, the most commonly used RSI period
- RSI(24): Longer 24-period RSI for trend confirmation, provides smoother signals with less noise
Each RSI can be smoothed using EMA, SMA, RMA (Wilder's smoothing), WMA, or Zero-Lag smoothing. Zero-Lag smoothing uses the formula: ZL-RSI = RSI + (RSI - RSI ) to reduce lag while maintaining signal quality. You can apply individual smoothing lengths to each RSI period, or use global smoothing where all three RSIs share the same smoothing length.
Dynamic Overbought/Oversold Thresholds:
Static thresholds (default 70/30) are adjusted based on market volatility using ATR. The formula: Dynamic OB = Base OB + (ATR × Volatility Multiplier × Base Percentage / 100), Dynamic OS = Base OS - (ATR × Volatility Multiplier × Base Percentage / 100). This adapts to volatile markets where traditional 70/30 levels may be too restrictive. During high volatility, the dynamic thresholds widen, and during low volatility, they narrow. The thresholds are clamped between 0-100 to remain within RSI bounds. The ATR is cached for performance optimization, updating on confirmed bars and real-time bars.
Adaptive RSI Calculation:
An adaptive RSI adjusts the standard RSI(14) based on current volatility relative to average volatility. The calculation: Adaptive Factor = (Current ATR / SMA of ATR over 20 periods) × Volatility Multiplier. If SMA of ATR is zero (edge case), the adaptive factor defaults to 0. The adaptive RSI = Base RSI × (1 + Adaptive Factor), clamped to 0-100. This makes the indicator more responsive during high volatility periods when traditional RSI may lag. The adaptive RSI is used for signal generation (buy/sell signals) but is not plotted on the chart.
Overbought/Oversold Fill Zones:
The script provides visual fill zones between the RSI line and the threshold lines when RSI is in overbought or oversold territory. The fill logic uses inclusive conditions: fills are shown when RSI is currently in the zone OR was in the zone on the previous bar. This ensures complete coverage of entry and exit boundaries. A minimum gap of 0.1 RSI points is maintained between the RSI plot and threshold line to ensure reliable polygon rendering in TradingView. The fill uses invisible plots at the threshold levels and the RSI value, with the fill color applied between them. You can select which RSI (6, 14, or 24) to use for the fill zones.
Divergence Detection
Regular Divergence:
Bullish divergence: Price makes a lower low (current low < lowest low from previous lookback period) while RSI makes a higher low (current RSI > lowest RSI from previous lookback period). Bearish divergence: Price makes a higher high (current high > highest high from previous lookback period) while RSI makes a lower high (current RSI < highest RSI from previous lookback period). The script compares current price/RSI values to the lowest/highest values from the previous lookback period using ta.lowest() and ta.highest() functions with index to reference the previous period's extreme.
Pivot-Based Divergence:
An enhanced divergence detection method that uses actual pivot points instead of simple lowest/highest comparisons. This provides more accurate divergence detection by identifying significant pivot lows/highs in both price and RSI. The pivot-based method uses a tolerance-based approach with configurable constants: 1% tolerance for price comparisons (priceTolerancePercent = 0.01) and 1.0 RSI point absolute tolerance for RSI comparisons (pivotTolerance = 1.0). Minimum divergence threshold is 1.0 RSI point (minDivergenceThreshold = 1.0). It looks for two recent pivot points and compares them: for bullish divergence, price makes a lower low (at least 1% lower) while RSI makes a higher low (at least 1.0 point higher). This method reduces false divergences by requiring actual pivot points rather than just any low/high within a period. When enabled, pivot-based divergence replaces the traditional method for more accurate signal generation.
Strong Divergence:
Regular divergence is confirmed by an engulfing candle pattern. Bullish engulfing requires: (1) Previous candle is bearish (close < open ), (2) Current candle is bullish (close > open), (3) Current close > previous open, (4) Current open < previous close. Bearish engulfing is the inverse: previous bullish, current bearish, current close < previous open, current open > previous close. Strong divergence signals are marked with visual indicators (🐂 for bullish, 🐻 for bearish) and have separate alert conditions.
Hidden Divergence:
Continuation patterns that signal trend continuation rather than reversal. Bullish hidden divergence: Price makes a higher low (current low > lowest low from previous period) but RSI makes a lower low (current RSI < lowest RSI from previous period). Bearish hidden divergence: Price makes a lower high (current high < highest high from previous period) but RSI makes a higher high (current RSI > highest RSI from previous period). These patterns indicate the trend is likely to continue in the current direction.
Volume Confirmation System
Volume threshold filtering requires current volume to exceed the volume SMA multiplied by the threshold factor. The formula: Volume Confirmed = Volume > (Volume SMA × Threshold). If the threshold is set to 0.1 or lower, volume confirmation is effectively disabled (always returns true). This allows you to use the indicator without volume filtering if desired.
Volume Climax is detected when volume exceeds: Volume SMA + (Volume StdDev × Multiplier). This indicates potential capitulation moments where extreme volume accompanies price movements. Volume Dry-Up is detected when volume falls below: Volume SMA - (Volume StdDev × Multiplier), indicating low participation periods that may produce unreliable signals. The volume SMA is cached for performance, updating on confirmed and real-time bars.
Multi-RSI Synergy
The script generates signals when multiple RSI periods align in overbought or oversold zones. This creates a confirmation system that reduces false signals. In "ALL" mode, all three RSIs (6, 14, 24) must be simultaneously above the overbought threshold OR all three must be below the oversold threshold. In "2-of-3" mode, any two of the three RSIs must align in the same direction. The script counts how many RSIs are in each zone: twoOfThreeOB = ((rsi6OB ? 1 : 0) + (rsi14OB ? 1 : 0) + (rsi24OB ? 1 : 0)) >= 2.
Synergy signals require: (1) Multi-RSI alignment (ALL or 2-of-3), (2) Volume confirmation, (3) Reset condition satisfied (enough bars since last synergy signal), (4) Additional filters passed (RSI50, Trend, ADX, Volume Dry-Up avoidance). Separate reset conditions track buy and sell signals independently. The reset condition uses ta.barssince() to count bars since the last trigger, returning true if the condition never occurred (allowing first signal) or if enough bars have passed.
Regression Forecasting
The script uses historical RSI values to forecast future RSI direction using four methods. The forecast horizon is configurable (1-50 bars ahead). Historical data is collected into an array, and regression coefficients are calculated based on the selected method.
Linear Regression: Calculates the least-squares fit line (y = mx + b) through the last N RSI values. The calculation: meanX = sumX / horizon, meanY = sumY / horizon, denominator = sumX² - horizon × meanX², m = (sumXY - horizon × meanX × meanY) / denominator, b = meanY - m × meanX. The forecast projects this line forward: forecast = b + m × i for i = 1 to horizon.
Polynomial Regression: Fits a quadratic curve (y = ax² + bx + c) to capture non-linear trends. The system of equations is solved using Cramer's rule with a 3×3 determinant. If the determinant is too small (< 0.0001), the system falls back to linear regression. Coefficients are calculated by solving: n×c + sumX×b + sumX²×a = sumY, sumX×c + sumX²×b + sumX³×a = sumXY, sumX²×c + sumX³×b + sumX⁴×a = sumX²Y. Note: Due to the O(n³) computational complexity of polynomial regression, the forecast horizon is automatically limited to a maximum of 20 bars when using polynomial regression to maintain optimal performance. If you set a horizon greater than 20 bars with polynomial regression, it will be automatically capped at 20 bars.
Exponential Smoothing: Applies exponential smoothing with adaptive alpha = 2/(horizon+1). The smoothing iterates from oldest to newest value: smoothed = alpha × series + (1 - alpha) × smoothed. Trend is calculated by comparing current smoothed value to an earlier smoothed value (at 60% of horizon): trend = (smoothed - earlierSmoothed) / (horizon - earlierIdx). Forecast: forecast = base + trend × i.
Moving Average: Uses the difference between short MA (horizon/2) and long MA (horizon) to estimate trend direction. Trend = (maShort - maLong) / (longLen - shortLen). Forecast: forecast = maShort + trend × i.
Confidence bands are calculated using RMSE (Root Mean Squared Error) of historical forecast accuracy. The error calculation compares historical values with forecast values: RMSE = sqrt(sumSquaredError / count). If insufficient data exists, it falls back to calculating standard deviation of recent RSI values. Confidence bands = forecast ± (RMSE × confidenceLevel). All forecast values and confidence bands are clamped to 0-100 to remain within RSI bounds. The regression functions include comprehensive safety checks: horizon validation (must not exceed array size), empty array handling, edge case handling for horizon=1 scenarios, division-by-zero protection, and bounds checking for all array access operations to prevent runtime errors.
Strong Top/Bottom Detection
Strong buy signals require three conditions: (1) RSI is at its lowest point within the bottom period: rsiVal <= ta.lowest(rsiVal, bottomPeriod), (2) RSI is below the oversold threshold minus a buffer: rsiVal < (oversoldThreshold - rsiTopBottomBuffer), where rsiTopBottomBuffer = 2.0 RSI points, (3) The absolute difference between current RSI and the lowest RSI exceeds the threshold value: abs(rsiVal - ta.lowest(rsiVal, bottomPeriod)) > threshold. This indicates a bounce from extreme levels with sufficient distance from the absolute low.
Strong sell signals use the inverse logic: RSI at highest point, above overbought threshold + rsiTopBottomBuffer (2.0 RSI points), and difference from highest exceeds threshold. Both signals also require: volume confirmation, reset condition satisfied (separate reset for buy vs sell), and all additional filters passed (RSI50, Trend, ADX, Volume Dry-Up avoidance).
The reset condition uses separate logic for buy and sell: resetCondBuy checks bars since isRSIAtBottom, resetCondSell checks bars since isRSIAtTop. This ensures buy signals reset based on bottom conditions and sell signals reset based on top conditions, preventing incorrect signal blocking.
Filtering System
RSI(50) Filter: Only allows buy signals when RSI(14) > 50 (bullish momentum) and sell signals when RSI(14) < 50 (bearish momentum). This filter ensures you're buying in uptrends and selling in downtrends from a momentum perspective. The filter is optional and can be disabled. Recommended to enable for noise reduction.
Trend Filter: Uses a long-term EMA (default 200) to determine trend direction. Buy signals require price above EMA, sell signals require price below EMA. The EMA slope is calculated as: emaSlope = ema - ema . Optional EMA slope filter additionally requires the EMA to be rising (slope > 0) for buy signals or falling (slope < 0) for sell signals. This provides stronger trend confirmation by requiring both price position and EMA direction.
ADX Filter: Uses the Directional Movement Index (calculated via ta.dmi()) to measure trend strength. Signals only fire when ADX exceeds the threshold (default 20), indicating a strong trend rather than choppy markets. The ADX calculation uses separate length and smoothing parameters. This filter helps avoid signals during sideways/consolidation periods.
Volume Dry-Up Avoidance: Prevents signals during periods of extremely low volume relative to average. If volume dry-up is detected and the filter is enabled, signals are blocked. This helps avoid unreliable signals that occur during low participation periods.
RSI Momentum Confirmation: Requires RSI to be accelerating in the signal direction before confirming signals. For buy signals, RSI must be consistently rising (recovering from oversold) over the lookback period. For sell signals, RSI must be consistently falling (declining from overbought) over the lookback period. The momentum check verifies that all consecutive changes are in the correct direction AND the cumulative change is significant. This filter ensures signals only fire when RSI momentum aligns with the signal direction, reducing false signals from weak momentum.
Multi-Timeframe Confirmation: Requires higher timeframe RSI to align with the signal direction. For buy signals, current RSI must be below the higher timeframe RSI by at least the confirmation threshold. For sell signals, current RSI must be above the higher timeframe RSI by at least the confirmation threshold. This ensures signals align with the larger trend context, reducing counter-trend trades. The higher timeframe RSI is fetched using request.security() from the selected timeframe.
All filters use the pattern: filterResult = not filterEnabled OR conditionMet. This means if a filter is disabled, it always passes (returns true). Filters can be combined, and all must pass for a signal to fire.
RSI Centerline and Period Crossovers
RSI(50) Centerline Crossovers: Detects when the selected RSI source crosses above or below the 50 centerline. Bullish crossover: ta.crossover(rsiSource, 50), bearish crossover: ta.crossunder(rsiSource, 50). You can select which RSI (6, 14, or 24) to use for these crossovers. These signals indicate momentum shifts from bearish to bullish (above 50) or bullish to bearish (below 50).
RSI Period Crossovers: Detects when different RSI periods cross each other. Available pairs: RSI(6) × RSI(14), RSI(14) × RSI(24), or RSI(6) × RSI(24). Bullish crossover: fast RSI crosses above slow RSI (ta.crossover(rsiFast, rsiSlow)), indicating momentum acceleration. Bearish crossover: fast RSI crosses below slow RSI (ta.crossunder(rsiFast, rsiSlow)), indicating momentum deceleration. These crossovers can signal shifts in momentum before price moves.
StochRSI Calculation
Stochastic RSI applies the Stochastic oscillator formula to RSI values instead of price. The calculation: %K = ((RSI - Lowest RSI) / (Highest RSI - Lowest RSI)) × 100, where the lookback is the StochRSI length. If the range is zero, %K defaults to 50.0. %K is then smoothed using SMA with the %K smoothing length. %D is calculated as SMA of smoothed %K with the %D smoothing length. All values are clamped to 0-100. You can select which RSI (6, 14, or 24) to use as the source for StochRSI calculation.
RSI Bollinger Bands
Bollinger Bands are applied to RSI(14) instead of price. The calculation: Basis = SMA(RSI(14), BB Period), StdDev = stdev(RSI(14), BB Period), Upper = Basis + (StdDev × Deviation Multiplier), Lower = Basis - (StdDev × Deviation Multiplier). This creates dynamic zones around RSI that adapt to RSI volatility. When RSI touches or exceeds the bands, it indicates extreme conditions relative to recent RSI behavior.
Noise Reduction System
The script includes a comprehensive noise reduction system to filter false signals and improve accuracy. When enabled, signals must pass multiple quality checks:
Signal Strength Requirement: RSI must be at least X points away from the centerline (50). For buy signals, RSI must be at least X points below 50. For sell signals, RSI must be at least X points above 50. This ensures signals only trigger when RSI is significantly in oversold/overbought territory, not just near neutral.
Extreme Zone Requirement: RSI must be deep in the OB/OS zone. For buy signals, RSI must be at least X points below the oversold threshold. For sell signals, RSI must be at least X points above the overbought threshold. This ensures signals only fire in extreme conditions where reversals are more likely.
Consecutive Bar Confirmation: The signal condition must persist for N consecutive bars before triggering. This reduces false signals from single-bar spikes or noise. The confirmation checks that the signal condition was true for all bars in the lookback period.
Zone Persistence (Optional): Requires RSI to remain in the OB/OS zone for N consecutive bars, not just touch it. This ensures RSI is truly in an extreme state rather than just briefly touching the threshold. When enabled, this provides stricter filtering for higher-quality signals.
RSI Slope Confirmation (Optional): Requires RSI to be moving in the expected signal direction. For buy signals, RSI should be rising (recovering from oversold). For sell signals, RSI should be falling (declining from overbought). This ensures momentum is aligned with the signal direction. The slope is calculated by comparing current RSI to RSI N bars ago.
All noise reduction filters can be enabled/disabled independently, allowing you to customize the balance between signal frequency and accuracy. The default settings provide a good balance, but you can adjust them based on your trading style and market conditions.
Alert System
The script includes separate alert conditions for each signal type: buy/sell (adaptive RSI crossovers), divergence (regular, strong, hidden), crossovers (RSI50 centerline, RSI period crossovers), synergy signals, and trend breaks. Each alert type has its own alertcondition() declaration with a unique title and message.
An optional cooldown system prevents alert spam by requiring a minimum number of bars between alerts of the same type. The cooldown check: canAlert = na(lastAlertBar) OR (bar_index - lastAlertBar >= cooldownBars). If the last alert bar is na (first alert), it always allows the alert. Each alert type maintains its own lastAlertBar variable, so cooldowns are independent per signal type. The default cooldown is 10 bars, which is recommended for noise reduction.
Higher Timeframe RSI
The script can display RSI from a higher timeframe using request.security(). This allows you to see the RSI context from a larger timeframe (e.g., daily RSI on an hourly chart). The higher timeframe RSI uses RSI(14) calculation from the selected timeframe. This provides context for the current timeframe's RSI position relative to the larger trend.
RSI Pivot Trendlines
The script can draw trendlines connecting pivot highs and lows on RSI(6). This feature helps visualize RSI trends and identify potential trend breaks.
Pivot Detection: Pivots are detected using a configurable period. The script can require pivots to have minimum strength (RSI points difference from surrounding bars) to filter out weak pivots. Lower minPivotStrength values detect more pivots (more trendlines), while higher values detect only stronger pivots (fewer but more significant trendlines). Pivot confirmation is optional: when enabled, the script waits N bars to confirm the pivot remains the extreme, reducing repainting. Pivot confirmation functions (f_confirmPivotLow and f_confirmPivotHigh) are always called on every bar for consistency, as recommended by TradingView. When pivot bars are not available (na), safe default values are used, and the results are then used conditionally based on confirmation settings. This ensures consistent calculations and prevents calculation inconsistencies.
Trendline Drawing: Uptrend lines connect confirmed pivot lows (green), and downtrend lines connect confirmed pivot highs (red). By default, only the most recent trendline is shown (old trendlines are deleted when new pivots are confirmed). This keeps the chart clean and uncluttered. If "Keep Historical Trendlines" is enabled, the script preserves up to N historical trendlines (configurable via "Max Trendlines to Keep", default 5). When historical trendlines are enabled, old trendlines are saved to arrays instead of being deleted, allowing you to see multiple trendlines simultaneously for better trend analysis. The arrays are automatically limited to prevent memory accumulation.
Trend Break Detection: Signals are generated when RSI breaks above or below trendlines. Uptrend breaks (RSI crosses below uptrend line) generate buy signals. Downtrend breaks (RSI crosses above downtrend line) generate sell signals. Optional trend break confirmation requires the break to persist for N bars and optionally include volume confirmation. Trendline angle filtering can exclude flat/weak trendlines from generating signals (minTrendlineAngle > 0 filters out weak/flat trendlines).
How Components Work Together
The combination of multiple RSI periods provides confirmation across different timeframes, reducing false signals. RSI(6) catches early moves, RSI(14) provides balanced signals, and RSI(24) confirms longer-term trends. When all three align (synergy), it indicates strong consensus across timeframes.
Volume confirmation ensures signals occur with sufficient market participation, filtering out low-volume false breakouts. Volume climax detection identifies potential reversal points, while volume dry-up avoidance prevents signals during unreliable low-volume periods.
Trend filters align signals with the overall market direction. The EMA filter ensures you're trading with the trend, and the EMA slope filter adds an additional layer by requiring the trend to be strengthening (rising EMA for buys, falling EMA for sells).
ADX filter ensures signals only fire during strong trends, avoiding choppy/consolidation periods. RSI(50) filter ensures momentum alignment with the trade direction.
Momentum confirmation requires RSI to be accelerating in the signal direction, ensuring signals only fire when momentum is aligned. Multi-timeframe confirmation ensures signals align with higher timeframe trends, reducing counter-trend trades.
Divergence detection identifies potential reversals before they occur, providing early warning signals. Pivot-based divergence provides more accurate detection by using actual pivot points. Hidden divergence identifies continuation patterns, useful for trend-following strategies.
The noise reduction system combines multiple filters (signal strength, extreme zone, consecutive bars, zone persistence, RSI slope) to significantly reduce false signals. These filters work together to ensure only high-quality signals are generated.
The synergy system requires alignment across all RSI periods for highest-quality signals, significantly reducing false positives. Regression forecasting provides forward-looking context, helping anticipate potential RSI direction changes.
Pivot trendlines provide visual trend analysis and can generate signals when RSI breaks trendlines, indicating potential reversals or continuations.
Reset conditions prevent signal spam by requiring a minimum number of bars between signals. Separate reset conditions for buy and sell signals ensure proper signal management.
Usage Instructions
Configuration Presets (Recommended): The script includes optimized preset configurations for instant setup. Simply select your trading style from the "Configuration Preset" dropdown:
- Scalping Preset: RSI(4, 7, 9) with minimal smoothing. Noise reduction disabled, momentum confirmation disabled for fastest signals.
- Day Trading Preset: RSI(6, 9, 14) with light smoothing. Momentum confirmation enabled for better signal quality.
- Swing Trading Preset: RSI(14, 14, 21) with moderate smoothing. Balanced configuration for medium-term trades.
- Position Trading Preset: RSI(24, 21, 28) with heavier smoothing. Optimized for longer-term positions with all filters active.
- Custom Mode: Full manual control over all settings. Default behavior matches previous script versions.
Presets automatically configure RSI periods, smoothing lengths, and filter settings. You can still manually adjust any setting after selecting a preset if needed.
Getting Started: The easiest way to get started is to select a configuration preset matching your trading style (Scalping, Day Trading, Swing Trading, or Position Trading) from the "Configuration Preset" dropdown. This instantly configures all settings for optimal performance. Alternatively, use "Custom" mode for full manual control. The default configuration (Custom mode) shows RSI(6), RSI(14), and RSI(24) with their default smoothing. Overbought/oversold fill zones are enabled by default.
Customizing RSI Periods: Adjust the RSI lengths (6, 14, 24) based on your trading timeframe. Shorter periods (6) for scalping, standard (14) for day trading, longer (24) for swing trading. You can disable any RSI period you don't need.
Smoothing Selection: Choose smoothing method based on your needs. EMA provides balanced smoothing, RMA (Wilder's) is traditional, Zero-Lag reduces lag but may increase noise. Adjust smoothing lengths individually or use global smoothing for consistency. Note: Smoothing lengths are automatically validated to ensure they are always less than the corresponding RSI period length. If you set smoothing >= RSI length, it will be auto-adjusted to prevent invalid configurations.
Dynamic OB/OS: The dynamic thresholds automatically adapt to volatility. Adjust the volatility multiplier and base percentage to fine-tune sensitivity. Higher values create wider thresholds in volatile markets.
Volume Confirmation: Set volume threshold to 1.2 (default) for standard confirmation, higher for stricter filtering, or 0.1 to disable volume filtering entirely.
Multi-RSI Synergy: Use "ALL" mode for highest-quality signals (all 3 RSIs must align), or "2-of-3" mode for more frequent signals. Adjust the reset period to control signal frequency.
Filters: Enable filters gradually to find your preferred balance. Start with volume confirmation, then add trend filter, then ADX for strongest confirmation. RSI(50) filter is useful for momentum-based strategies and is recommended for noise reduction. Momentum confirmation and multi-timeframe confirmation add additional layers of accuracy but may reduce signal frequency.
Noise Reduction: The noise reduction system is enabled by default with balanced settings. Adjust minSignalStrength (default 3.0) to control how far RSI must be from centerline. Increase requireConsecutiveBars (default 1) to require signals to persist longer. Enable requireZonePersistence and requireRsiSlope for stricter filtering (higher quality but fewer signals). Start with defaults and adjust based on your needs.
Divergence: Enable divergence detection and adjust lookback periods. Strong divergence (with engulfing confirmation) provides higher-quality signals. Hidden divergence is useful for trend-following strategies. Enable pivot-based divergence for more accurate detection using actual pivot points instead of simple lowest/highest comparisons. Pivot-based divergence uses tolerance-based matching (1% for price, 1.0 RSI point for RSI) for better accuracy.
Forecasting: Enable regression forecasting to see potential RSI direction. Linear regression is simplest, polynomial captures curves, exponential smoothing adapts to trends. Adjust horizon based on your trading timeframe. Confidence bands show forecast uncertainty - wider bands indicate less reliable forecasts.
Pivot Trendlines: Enable pivot trendlines to visualize RSI trends and identify trend breaks. Adjust pivot detection period (default 5) - higher values detect fewer but stronger pivots. Enable pivot confirmation (default ON) to reduce repainting. Set minPivotStrength (default 1.0) to filter weak pivots - lower values detect more pivots (more trendlines), higher values detect only stronger pivots (fewer trendlines). Enable "Keep Historical Trendlines" to preserve multiple trendlines instead of just the most recent one. Set "Max Trendlines to Keep" (default 5) to control how many historical trendlines are preserved. Enable trend break confirmation for more reliable break signals. Adjust minTrendlineAngle (default 0.0) to filter flat trendlines - set to 0.1-0.5 to exclude weak trendlines.
Alerts: Set up alerts for your preferred signal types. Enable cooldown to prevent alert spam. Each signal type has its own alert condition, so you can be selective about which signals trigger alerts.
Visual Elements and Signal Markers
The script uses various visual markers to indicate signals and conditions:
- "sBottom" label (green): Strong bottom signal - RSI at extreme low with strong buy conditions
- "sTop" label (red): Strong top signal - RSI at extreme high with strong sell conditions
- "SyBuy" label (lime): Multi-RSI synergy buy signal - all RSIs aligned oversold
- "SySell" label (red): Multi-RSI synergy sell signal - all RSIs aligned overbought
- 🐂 emoji (green): Strong bullish divergence detected
- 🐻 emoji (red): Strong bearish divergence detected
- 🔆 emoji: Weak divergence signals (if enabled)
- "H-Bull" label: Hidden bullish divergence
- "H-Bear" label: Hidden bearish divergence
- ⚡ marker (top of pane): Volume climax detected (extreme volume) - positioned at top for visibility
- 💧 marker (top of pane): Volume dry-up detected (very low volume) - positioned at top for visibility
- ↑ triangle (lime): Uptrend break signal - RSI breaks below uptrend line
- ↓ triangle (red): Downtrend break signal - RSI breaks above downtrend line
- Triangle up (lime): RSI(50) bullish crossover
- Triangle down (red): RSI(50) bearish crossover
- Circle markers: RSI period crossovers
All markers are positioned at the RSI value where the signal occurs, using location.absolute for precise placement.
Signal Priority and Interpretation
Signals are generated independently and can occur simultaneously. Higher-priority signals generally indicate stronger setups:
1. Multi-RSI Synergy signals (SyBuy/SySell) - Highest priority: Requires alignment across all RSI periods plus volume and filter confirmation. These are the most reliable signals.
2. Strong Top/Bottom signals (sTop/sBottom) - High priority: Indicates extreme RSI levels with strong bounce conditions. Requires volume confirmation and all filters.
3. Divergence signals - Medium-High priority: Strong divergence (with engulfing) is more reliable than regular divergence. Hidden divergence indicates continuation rather than reversal.
4. Adaptive RSI crossovers - Medium priority: Buy when adaptive RSI crosses below dynamic oversold, sell when it crosses above dynamic overbought. These use volatility-adjusted RSI for more accurate signals.
5. RSI(50) centerline crossovers - Medium priority: Momentum shift signals. Less reliable alone but useful when combined with other confirmations.
6. RSI period crossovers - Lower priority: Early momentum shift indicators. Can provide early warning but may produce false signals in choppy markets.
Best practice: Wait for multiple confirmations. For example, a synergy signal combined with divergence and volume climax provides the strongest setup.
Chart Requirements
For proper script functionality and compliance with TradingView requirements, ensure your chart displays:
- Symbol name: The trading pair or instrument name should be visible
- Timeframe: The chart timeframe should be clearly displayed
- Script name: "Ultimate RSI " should be visible in the indicator title
These elements help traders understand what they're viewing and ensure proper script identification. The script automatically includes this information in the indicator title and chart labels.
Performance Considerations
The script is optimized for performance:
- ATR and Volume SMA are cached using var variables, updating only on confirmed and real-time bars to reduce redundant calculations
- Forecast line arrays are dynamically managed: lines are reused when possible, and unused lines are deleted to prevent memory accumulation
- Calculations use efficient Pine Script functions (ta.rsi, ta.ema, etc.) which are optimized by TradingView
- Array operations are minimized where possible, with direct calculations preferred
- Polynomial regression automatically caps the forecast horizon at 20 bars (POLYNOMIAL_MAX_HORIZON constant) to prevent performance degradation, as polynomial regression has O(n³) complexity. This safeguard ensures optimal performance even with large horizon settings
- Pivot detection includes edge case handling to ensure reliable calculations even on early bars with limited historical data. Regression forecasting functions include comprehensive safety checks: horizon validation (must not exceed array size), empty array handling, edge case handling for horizon=1 scenarios, and division-by-zero protection in all mathematical operations
The script should perform well on all timeframes. On very long historical data, forecast lines may accumulate if the horizon is large; consider reducing the forecast horizon if you experience performance issues. The polynomial regression performance safeguard automatically prevents performance issues for that specific regression type.
Known Limitations and Considerations
- Forecast lines are forward-looking projections and should not be used as definitive predictions. They provide context but are not guaranteed to be accurate.
- Dynamic OB/OS thresholds can exceed 100 or go below 0 in extreme volatility scenarios, but are clamped to 0-100 range. This means in very volatile markets, the dynamic thresholds may not widen as much as the raw calculation suggests.
- Volume confirmation requires sufficient historical volume data. On new instruments or very short timeframes, volume calculations may be less reliable.
- Higher timeframe RSI uses request.security() which may have slight delays on some data feeds.
- Regression forecasting requires at least N bars of history (where N = forecast horizon) before it can generate forecasts. Early bars will not show forecast lines.
- StochRSI calculation requires the selected RSI source to have sufficient history. Very short RSI periods on new charts may produce less reliable StochRSI values initially.
Practical Use Cases
The indicator can be configured for different trading styles and timeframes:
Swing Trading: Select the "Swing Trading" preset for instant optimal configuration. This preset uses RSI periods (14, 14, 21) with moderate smoothing. Alternatively, manually configure: Use RSI(24) with Multi-RSI Synergy in "ALL" mode, combined with trend filter (EMA 200) and ADX filter. This configuration provides high-probability setups with strong confirmation across multiple RSI periods.
Day Trading: Select the "Day Trading" preset for instant optimal configuration. This preset uses RSI periods (6, 9, 14) with light smoothing and momentum confirmation enabled. Alternatively, manually configure: Use RSI(6) with Zero-Lag smoothing for fast signal detection. Enable volume confirmation with threshold 1.2-1.5 for reliable entries. Combine with RSI(50) filter to ensure momentum alignment. Strong top/bottom signals work well for day trading reversals.
Trend Following: Enable trend filter (EMA) and EMA slope filter for strong trend confirmation. Use RSI(14) or RSI(24) with ADX filter to avoid choppy markets. Hidden divergence signals are useful for trend continuation entries.
Reversal Trading: Focus on divergence detection (regular and strong) combined with strong top/bottom signals. Enable volume climax detection to identify capitulation moments. Use RSI(6) for early reversal signals, confirmed by RSI(14) and RSI(24).
Forecasting and Planning: Enable regression forecasting with polynomial or exponential smoothing methods. Use forecast horizon of 10-20 bars for swing trading, 5-10 bars for day trading. Confidence bands help assess forecast reliability.
Multi-Timeframe Analysis: Enable higher timeframe RSI to see context from larger timeframes. For example, use daily RSI on hourly charts to understand the larger trend context. This helps avoid counter-trend trades.
Scalping: Select the "Scalping" preset for instant optimal configuration. This preset uses RSI periods (4, 7, 9) with minimal smoothing, disables noise reduction, and disables momentum confirmation for faster signals. Alternatively, manually configure: Use RSI(6) with minimal smoothing (or Zero-Lag) for ultra-fast signals. Disable most filters except volume confirmation. Use RSI period crossovers (RSI(6) × RSI(14)) for early momentum shifts. Set volume threshold to 1.0-1.2 for less restrictive filtering.
Position Trading: Select the "Position Trading" preset for instant optimal configuration. This preset uses extended RSI periods (24, 21, 28) with heavier smoothing, optimized for longer-term trades. Alternatively, manually configure: Use RSI(24) with all filters enabled (Trend, ADX, RSI(50), Volume Dry-Up avoidance). Multi-RSI Synergy in "ALL" mode provides highest-quality signals.
Practical Tips and Best Practices
Getting Started: The fastest way to get started is to select a configuration preset that matches your trading style. Simply choose "Scalping", "Day Trading", "Swing Trading", or "Position Trading" from the "Configuration Preset" dropdown to instantly configure all settings optimally. For advanced users, use "Custom" mode for full manual control. The default configuration (Custom mode) is balanced and works well across different markets. After observing behavior, customize settings to match your trading style.
Reducing Repainting: All signals are based on confirmed bars, minimizing repainting. The script uses confirmed bar data for all calculations to ensure backtesting accuracy.
Signal Quality: Multi-RSI Synergy signals in "ALL" mode provide the highest-quality signals because they require alignment across all three RSI periods. These signals have lower frequency but higher reliability. For more frequent signals, use "2-of-3" mode. The noise reduction system further improves signal quality by requiring multiple confirmations (signal strength, extreme zone, consecutive bars, optional zone persistence and RSI slope). Adjust noise reduction settings to balance signal frequency vs. accuracy.
Filter Combinations: Start with volume confirmation, then add trend filter for trend alignment, then ADX filter for trend strength. Combining all three filters significantly reduces false signals but also reduces signal frequency. Find your balance based on your risk tolerance.
Volume Filtering: Set volume threshold to 0.1 or lower to effectively disable volume filtering if you trade instruments with unreliable volume data or want to test without volume confirmation. Standard confirmation uses 1.2-1.5 threshold.
RSI Period Selection: RSI(6) is most sensitive and best for scalping or early signal detection. RSI(14) provides balanced signals suitable for day trading. RSI(24) is smoother and better for swing trading and trend confirmation. You can disable any RSI period you don't need to reduce visual clutter.
Smoothing Methods: EMA provides balanced smoothing with moderate lag. RMA (Wilder's smoothing) is traditional and works well for RSI. Zero-Lag reduces lag but may increase noise. WMA gives more weight to recent values. Choose based on your preference for responsiveness vs. smoothness.
Forecasting: Linear regression is simplest and works well for trending markets. Polynomial regression captures curves and works better in ranging markets. Exponential smoothing adapts to trends. Moving average method is most conservative. Use confidence bands to assess forecast reliability.
Divergence: Strong divergence (with engulfing confirmation) is more reliable than regular divergence. Hidden divergence indicates continuation rather than reversal, useful for trend-following strategies. Pivot-based divergence provides more accurate detection by using actual pivot points instead of simple lowest/highest comparisons. Adjust lookback periods based on your timeframe: shorter for day trading, longer for swing trading. Pivot divergence period (default 5) controls the sensitivity of pivot detection.
Dynamic Thresholds: Dynamic OB/OS thresholds automatically adapt to volatility. In volatile markets, thresholds widen; in calm markets, they narrow. Adjust the volatility multiplier and base percentage to fine-tune sensitivity. Higher values create wider thresholds in volatile markets.
Alert Management: Enable alert cooldown (default 10 bars, recommended) to prevent alert spam. Each alert type has its own cooldown, so you can set different cooldowns for different signal types. For example, use shorter cooldown for synergy signals (high quality) and longer cooldown for crossovers (more frequent). The cooldown system works independently for each signal type, preventing spam while allowing different signal types to fire when appropriate.
Technical Specifications
- Pine Script Version: v6
- Indicator Type: Non-overlay (displays in separate panel below price chart)
- Repainting Behavior: Minimal - all signals are based on confirmed bars, ensuring accurate backtesting results
- Performance: Optimized with caching for ATR and volume calculations. Forecast arrays are dynamically managed to prevent memory accumulation.
- Compatibility: Works on all timeframes (1 minute to 1 month) and all instruments (stocks, forex, crypto, futures, etc.)
- Edge Case Handling: All calculations include safety checks for division by zero, NA values, and boundary conditions. Reset conditions and alert cooldowns handle edge cases where conditions never occurred or values are NA.
- Reset Logic: Separate reset conditions for buy signals (based on bottom conditions) and sell signals (based on top conditions) ensure logical correctness.
- Input Parameters: 60+ customizable parameters organized into logical groups for easy configuration. Configuration presets available for instant setup (Scalping, Day Trading, Swing Trading, Position Trading, Custom).
- Noise Reduction: Comprehensive noise reduction system with multiple filters (signal strength, extreme zone, consecutive bars, zone persistence, RSI slope) to reduce false signals.
- Pivot-Based Divergence: Enhanced divergence detection using actual pivot points for improved accuracy.
- Momentum Confirmation: RSI momentum filter ensures signals only fire when RSI is accelerating in the signal direction.
- Multi-Timeframe Confirmation: Optional higher timeframe RSI alignment for trend confirmation.
- Enhanced Pivot Trendlines: Trendline drawing with strength requirements, confirmation, and trend break detection.
Technical Notes
- All RSI values are clamped to 0-100 range to ensure valid oscillator values
- ATR and Volume SMA are cached for performance, updating on confirmed and real-time bars
- Reset conditions handle edge cases: if a condition never occurred, reset returns true (allows first signal)
- Alert cooldown handles na values: if no previous alert, cooldown allows the alert
- Forecast arrays are dynamically sized based on horizon, with unused lines cleaned up
- Fill logic uses a minimum gap (0.1) to ensure reliable polygon rendering in TradingView
- All calculations include safety checks for division by zero and boundary conditions. Regression functions validate that horizon doesn't exceed array size, and all array access operations include bounds checking to prevent out-of-bounds errors
- The script uses separate reset conditions for buy signals (based on bottom conditions) and sell signals (based on top conditions) for logical correctness
- Background coloring uses a fallback system: dynamic color takes priority, then RSI(6) heatmap, then monotone if both are disabled
- Noise reduction filters are applied after accuracy filters, providing multiple layers of signal quality control
- Pivot trendlines use strength requirements to filter weak pivots, reducing noise in trendline drawing. Historical trendlines are stored in arrays and automatically limited to prevent memory accumulation when "Keep Historical Trendlines" is enabled
- Volume climax and dry-up markers are positioned at the top of the pane for better visibility
- All calculations are optimized with conditional execution - features only calculate when enabled (performance optimization)
- Input Validation: Automatic cross-input validation ensures smoothing lengths are always less than RSI period lengths, preventing configuration errors
- Configuration Presets: Four optimized preset configurations (Scalping, Day Trading, Swing Trading, Position Trading) for instant setup, plus Custom mode for full manual control
- Constants Management: Magic numbers extracted to documented constants for improved maintainability and easier tuning (pivot tolerance, divergence thresholds, fill gap, etc.)
- TradingView Function Consistency: All TradingView functions (ta.crossover, ta.crossunder, ta.atr, ta.lowest, ta.highest, ta.lowestbars, ta.highestbars, etc.) and custom functions that depend on historical results (f_consecutiveBarConfirmation, f_rsiSlopeConfirmation, f_rsiZonePersistence, f_applyAllFilters, f_rsiMomentum, f_forecast, f_confirmPivotLow, f_confirmPivotHigh) are called on every bar for consistency, as recommended by TradingView. Results are then used conditionally when needed. This ensures consistent calculations and prevents calculation inconsistencies.

ChronoFlow## ChronoFlow Sentinel
ChronoFlow Sentinel is a regime console that blends normalized fast/mid/slow regression slopes, phases them against a dual-speed EMA spread, and grades alignment so you instantly know whether the time stack is trending, rotating, or fighting itself.
HOW IT WORKS
Multi-Timeframe Slopes – Linear regression slopes are fetched via request.security() for your chosen fast, mid, and slow frames.
Normalized Weighting – User weights are rescaled so the composite chrono score is always on a consistent scale, regardless of configuration.
Phase Differential – The indicator subtracts a slow EMA from a fast EMA to detect whether price impulse confirms the slope mix.
Alignment Score – Signs of the three slopes are compared to compute a 0-1 alignment metric; backgrounds and alerts use this to signal confidence vs. chop.
Diagnostics Console – A bottom-right table streams each slope, the blended score, and which timeframe currently dominates.
HOW TO USE IT
Trend Qualification : Only push multi-contract positions when chrono score is positive, phase is positive, and alignment stays above your alert threshold (default 0.66).
Chop Defense : When alignment dips and conflict markers appear, immediately switch into mean-reversion tactics or sit flat.
Swing + Intraday Bridge : Pair ChronoFlow with other structure tools; require both aligned backgrounds and price confirmation before committing to swing entries.
CRYPTOCAP:SOL | CRYPTOCAP:XRP side by side view with ChronoFlow
VISUAL FEATURES
Optional flow curves: Enable Plot Raw Flows to audit each timeframe's slope when troubleshooting a signal.
Background intensity: Opacity auto-adjusts with alignment, so weak trends look faded while strong regimes glow vividly.
Signal/Conflict toggles: Long/short and chop markers are opt-in, keeping the panel pristine until you need annotations.
Conflict alerts: Built-in alert condition fires whenever alignment falls below your threshold, warning execution layers to scale down risk.
PARAMETERS
Fast Frame (default: 30): Fast timeframe for regression slope calculation.
Mid Frame (default: 120): Mid timeframe for regression slope calculation.
Slow Frame (default: D): Slow timeframe for regression slope calculation.
Fast Regression (default: 21): Regression length for fast timeframe.
Mid Regression (default: 34): Regression length for mid timeframe.
Slow Regression (default: 55): Regression length for slow timeframe.
Phase Length (default: 13): EMA period for phase differential calculation.
Fast Weight (default: 0.45): Influence of the fast timeframe in the composite score.
Mid Weight (default: 0.35): Influence of the mid timeframe in the composite score.
Slow Weight (default: 0.20): Influence of the slow timeframe in the composite score.
Plot Raw Flows (default: disabled): Enable to audit each timeframe's slope when troubleshooting.
Show Signal Labels (default: disabled): Toggle long/short signal markers.
Show Conflict Labels (default: disabled): Toggle conflict/chop markers.
Conflict Alert Level (default: 0.66): Set the alignment threshold that should trigger reduced size or flat positioning.
ALERTS
The indicator includes three alert conditions:
ChronoFlow Bullish: Detected a bullish regime shift
ChronoFlow Bearish: Detected a bearish regime shift
ChronoFlow Conflict: Flagged a low-alignment regime
LIMITATIONS
This indicator requires access to multiple timeframes via request.security() , which may consume additional resources. The alignment score is a simplified metric—real market conditions are more complex than a 0-1 scale can capture. The phase differential calculation assumes EMA spreads are meaningful proxies for momentum, which may not hold in all market regimes. Users should test parameter combinations on their specific instruments and timeframes, as default values are optimized for typical index futures trading.
---

Static K-means Clustering | InvestorUnknownStatic K-Means Clustering is a machine-learning-driven market regime classifier designed for traders who want a data-driven structure instead of subjective indicators or manually drawn zones.
This script performs offline (static) K-means training on your chosen historical window. Using four engineered features:
RSI (Momentum)
CCI (Price deviation / Mean reversion)
CMF (Money flow / Strength)
MACD Histogram (Trend acceleration)
It groups past market conditions into K distinct clusters (regimes). After training, every new bar is assigned to the nearest cluster via Euclidean distance in 4-dimensional standardized feature space.
This allows you to create models like:
Regime-based long/short filters
Volatility phase detectors
Trend vs. chop separation
Mean-reversion vs. breakout classification
Volume-enhanced money-flow regime shifts
Full machine-learning trading systems based solely on regimes
Note:
This script is not a universal ML strategy out of the box.
The user must engineer the feature set to match their trading style and target market.
K-means is a tool, not a ready made system, this script provides the framework.
Core Idea
K-means clustering takes raw, unlabeled market observations and attempts to discover structure by grouping similar bars together.
// STEP 1 — DATA POINTS ON A COORDINATE PLANE
// We start with raw, unlabeled data scattered in 2D space (x/y).
// At this point, nothing is grouped—these are just observations.
// K-means will try to discover structure by grouping nearby points.
//
// y ↑
// |
// 12 | •
// | •
// 10 | •
// | •
// 8 | • •
// |
// 6 | •
// |
// 4 | •
// |
// 2 |______________________________________________→ x
// 2 4 6 8 10 12 14
//
//
//
// STEP 2 — RANDOMLY PLACE INITIAL CENTROIDS
// The algorithm begins by placing K centroids at random positions.
// These centroids act as the temporary “representatives” of clusters.
// Their starting positions heavily influence the first assignment step.
//
// y ↑
// |
// 12 | •
// | •
// 10 | • C2 ×
// | •
// 8 | • •
// |
// 6 | C1 × •
// |
// 4 | •
// |
// 2 |______________________________________________→ x
// 2 4 6 8 10 12 14
//
//
//
// STEP 3 — ASSIGN POINTS TO NEAREST CENTROID
// Each point is compared to all centroids.
// Using simple Euclidean distance, each point joins the cluster
// of the centroid it is closest to.
// This creates a temporary grouping of the data.
//
// (Coloring concept shown using labels)
//
// - Points closer to C1 → Cluster 1
// - Points closer to C2 → Cluster 2
//
// y ↑
// |
// 12 | 2
// | 1
// 10 | 1 C2 ×
// | 2
// 8 | 1 2
// |
// 6 | C1 × 2
// |
// 4 | 1
// |
// 2 |______________________________________________→ x
// 2 4 6 8 10 12 14
//
// (1 = assigned to Cluster 1, 2 = assigned to Cluster 2)
// At this stage, clusters are formed purely by distance.
Your chosen historical window becomes the static training dataset , and after fitting, the centroids never change again.
This makes the model:
Predictable
Repeatable
Consistent across backtests
Fast for live use (no recalculation of centroids every bar)
Static Training Window
You select a period with:
Training Start
Training End
Only bars inside this range are used to fit the K-means model. This window defines:
the market regime examples
the statistical distributions (means/std) for each feature
how the centroids will be positioned post-trainin
Bars before training = fully transparent
Training bars = gray
Post-training bars = full colored regimes
Feature Engineering (4D Input Vector)
Every bar during training becomes a 4-dimensional point:
This combination balances: momentum, volatility, mean-reversion, trend acceleration giving the algorithm a richer "market fingerprint" per bar.
Standardization
To prevent any feature from dominating due to scale differences (e.g., CMF near zero vs CCI ±200), all features are standardized:
standardize(value, mean, std) =>
(value - mean) / std
Centroid Initialization
Centroids start at diverse coordinates using various curves:
linear
sinusoidal
sign-preserving quadratic
tanh compression
init_centroids() =>
// Spread centroids across using different shapes per feature
for c = 0 to k_clusters - 1
frac = k_clusters == 1 ? 0.0 : c / (k_clusters - 1.0) // 0 → 1
v = frac * 2 - 1 // -1 → +1
array.set(cent_rsi, c, v) // linear
array.set(cent_cci, c, math.sin(v)) // sinusoidal
array.set(cent_cmf, c, v * v * (v < 0 ? -1 : 1)) // quadratic sign-preserving
array.set(cent_mac, c, tanh(v)) // compressed
This makes initial cluster spread “random” even though true randomness is hardly achieved in pinescript.
K-Means Iterative Refinement
The algorithm repeats these steps:
(A) Assignment Step, Each bar is assigned to the nearest centroid via Euclidean distance in 4D:
distance = sqrt(dx² + dy² + dz² + dw²)
(B) Update Step, Centroids update to the mean of points assigned to them. This repeats iterations times (configurable).
LIVE REGIME CLASSIFICATION
After training, each new bar is:
Standardized using the training mean/std
Compared to all centroids
Assigned to the nearest cluster
Bar color updates based on cluster
No re-training occurs. This ensures:
No lookahead bias
Clean historical testing
Stable regimes over time
CLUSTER BEHAVIOR & TRADING LOGIC
Clusters (0, 1, 2, 3…) hold no inherent meaning. The user defines what each cluster does.
Example of custom actions:
Cluster 0 → Cash
Cluster 1 → Long
Cluster 2 → Short
Cluster 3+ → Cash (noise regime)
This flexibility means:
One trader might have cluster 0 as consolidation.
Another might repurpose it as a breakout-loading zone.
A third might ignore 3 clusters entirely.
Example on ETHUSD
Important Note:
Any change of parameters or chart timeframe or ticker can cause the “order” of clusters to change
The script does NOT assume any cluster equals any actionable bias, user decides.
PERFORMANCE METRICS & ROC TABLE
The indicator computes average 1-bar ROC for each cluster in:
Training set
Test (live) set
This helps measure:
Cluster profitability consistency
Regime forward predictability
Whether a regime is noise, trend, or reversion-biased
EQUITY SIMULATION & FEES
Designed for close-to-close realistic backtesting.
Position = cluster of previous bar
Fees applied only on regime switches. Meaning:
Staying long → no fee
Switching long→short → fee applied
Switching any→cash → fee applied
Fee input is percentage, but script already converts internally.
Disclaimers
⚠️ This indicator uses machine-learning but does not predict the future. It classifies similarity to past regimes, nothing more.
⚠️ Backtest results are not indicative of future performance.
⚠️ Clusters have no inherent “bullish” or “bearish” meaning. You must interpret them based on your testing and your own feature engineering.

Market Electromagnetic Field [The_lurker]Market Electromagnetic Field
An innovative analytical indicator that presents a completely new model for understanding market dynamics, inspired by the laws of electromagnetic physics — but it's not a rhetorical metaphor, rather a complete mathematical system.
Unlike traditional indicators that focus on price or momentum, this indicator portrays the market as a closed physical system, where:
⚡ Candles = Electric charges (positive at bullish close, negative at bearish)
⚡ Buyers and Sellers = Two opposing poles where pressure accumulates
⚡ Market tension = Voltage difference between the poles
⚡ Price breakout = Electrical discharge after sufficient energy accumulation
█ Core Concept
Markets don't move randomly, but follow a clear physical cycle:
Accumulation → Tension → Discharge → Stabilization → New Accumulation
When charges accumulate (through strong candles with high volume) and exceed a certain "electrical capacitance" threshold, the indicator issues a "⚡ DISCHARGE IMMINENT" alert — meaning a price explosion is imminent, giving the trader an opportunity to enter before the move begins.
█ Competitive Advantage
- Predictive forecasting (not confirmatory after the event)
- Smart multi-layer filtering reduces false signals
- Animated 3D visual representation makes reading price conditions instant and intuitive — without need for number analysis
█ Theoretical Physical Foundation
The indicator doesn't use physical terms for decoration, but applies mathematical laws with precise market adjustments:
⚡ Coulomb's Law
Physics: F = k × (q₁ × q₂) / r²
Market: Field Intensity = 4 × norm_positive × norm_negative
Peaks at equilibrium (0.5 × 0.5 × 4 = 1.0), and decreases at dominance — because conflict increases at parity.
⚡ Ohm's Law
Physics: V = I × R
Market: Voltage = norm_positive − norm_negative
Measures balance of power:
- +1 = Absolute buying dominance
- −1 = Absolute selling dominance
- 0 = Balance
⚡ Capacitance
Physics: C = Q / V
Market: Capacitance = |Voltage| × Field Intensity
Represents stored energy ready for discharge — increases with bias combined with high interaction.
⚡ Electrical Discharge
Physics: Occurs when exceeding insulation threshold
Market: Discharge Probability = min(Capacitance / Discharge Threshold, 1.0)
When ≥ 0.9: "⚡ DISCHARGE IMMINENT"
📌 Key Note:
Maximum capacitance doesn't occur at absolute dominance (where field intensity = 0), nor at perfect balance (where voltage = 0), but at moderate bias (±30–50%) with high interaction (field intensity > 25%) — i.e., in moments of "pressure before breakout".
█ Detailed Calculation Mechanism
⚡ Phase 1: Candle Polarity
polarity = (close − open) / (high − low)
- +1.0: Complete bullish candle (Bullish Marubozu)
- −1.0: Complete bearish candle (Bearish Marubozu)
- 0.0: Doji (no decision)
- Intermediate values: Represent the ratio of candle body to its range — reducing the effect of long-shadow candles
⚡ Phase 2: Volume Weight
vol_weight = volume / SMA(volume, lookback)
A candle with 150% of average volume = 1.5x stronger charge
⚡ Phase 3: Adaptive Factor
adaptive_factor = ATR(lookback) / SMA(ATR, lookback × 2)
- In volatile markets: Increases sensitivity
- In quiet markets: Reduces noise
- Always recommended to keep it enabled
⚡ Phase 4–6: Charge Accumulation and Normalization
Charges are summed over lookback candles, then ratios are normalized:
norm_positive = positive_charge / total_charge
norm_negative = negative_charge / total_charge
So that: norm_positive + norm_negative = 1 — for easier comparison
⚡ Phase 7: Field Calculations
voltage = norm_positive − norm_negative
field_intensity = 4 × norm_positive × norm_negative × field_sensitivity
capacitance = |voltage| × field_intensity
discharge_prob = min(capacitance / discharge_threshold, 1.0)
█ Settings
⚡ Electromagnetic Model
Lookback Period
- Default: 20
- Range: 5–100
- Recommendations:
- Scalping: 10–15
- Day Trading: 20
- Swing: 30–50
- Investing: 50–100
Discharge Threshold
- Default: 0.7
- Range: 0.3–0.95
- Recommendations:
- Speed + Noise: 0.5–0.6
- Balance: 0.7
- High Accuracy: 0.8–0.95
Field Sensitivity
- Default: 1.0
- Range: 0.5–2.0
- Recommendations:
- Amplify Conflict: 1.2–1.5
- Natural: 1.0
- Calm: 0.5–0.8
Adaptive Mode
- Default: Enabled
- Always keep it enabled
🔬 Dynamic Filters
All enabled filters must pass for discharge signal to appear.
Volume Filter
- Condition: volume > SMA(volume) × vol_multiplier
- Function: Excludes "weak" candles not supported by volume
- Recommendation: Enabled (especially for stocks and forex)
Volatility Filter
- Condition: STDEV > SMA(STDEV) × 0.5
- Function: Ignores sideways stagnation periods
- Recommendation: Always enabled
Trend Filter
- Condition: Voltage alignment with fast/slow EMA
- Function: Reduces counter-trend signals
- Recommendation: Enabled for swing/investing only
Volume Threshold
- Default: 1.2
- Recommendations:
- 1.0–1.2: High sensitivity
- 1.5–2.0: Exclusive to high volume
🎨 Visual Settings
Settings improve visual reading experience — don't affect calculations.
Scale Factor
- Default: 600
- Higher = Larger scene (200–1200)
Horizontal Shift
- Default: 180
- Horizontal shift to the left — to focus on last candle
Pole Size
- Default: 60
- Base sphere size (30–120)
Field Lines
- Default: 8
- Number of field lines (4–16) — 8 is ideal balance
Colors
- Green/Red/Blue/Orange
- Fully customizable
█ Visual Representation: A Visual Language for Diagnosing Price Conditions
✨ Design Philosophy
The representation isn't "decoration", but a complete cognitive model — each element carries information, and element interaction tells a complete story.
The brain perceives changes in size, color, and movement 60,000 times faster than reading numbers — so you can "sense" the change before your eye finishes scanning.
═════════════════════════════════════════════════════════════
🟢 Positive Pole (Green Sphere — Left)
═════════════════════════════════════════════════════════════
What does it represent?
Active buying pressure accumulation — not just an uptrend, but real demand force supported by volume and volatility.
● Dynamic Size
Size = pole_size × (0.7 + norm_positive × 0.6)
- 70% of base size = No significant charge
- 130% of base size = Complete dominance
- The larger the sphere: Greater buyer dominance, higher probability of bullish continuation
Size Interpretation:
- Large sphere (>55%): Strong buying pressure — Buyers dominate
- Medium sphere (45–55%): Relative balance with buying bias
- Small sphere (<45%): Weak buying pressure — Sellers dominate
● Lighting and Transparency
- 20% transparency (when Bias = +1): Pole currently active — Bullish direction
- 50% transparency (when Bias ≠ +1): Pole inactive — Not the prevailing direction
Lighting = Current activity, while Size = Historical accumulation
● Pulsing Inner Glow
A smaller sphere pulses automatically when Bias = +1:
inner_pulse = 0.4 + 0.1 × sin(anim_time × 3)
Symbolizes continuity of buy order flow — not static dominance.
● Orbital Rings
Two rings rotating at different speeds and directions:
- Inner: 1.3× sphere size — Direct influence range
- Outer: 1.6× sphere size — Extended influence range
Represent "influence zone" of buyers:
- Continuous rotation = Stability and momentum
- Slowdown = Momentum exhaustion
● Percentage
Displayed below sphere: norm_positive × 100
- >55% = Clear dominance
- 45–55% = Balance
- <45% = Weakness
═════════════════════════════════════════════════════════════
🔴 Negative Pole (Red Sphere — Right)
═════════════════════════════════════════════════════════════
What does it represent?
Active selling pressure accumulation — whether cumulative selling (smart distribution) or panic selling (position liquidation).
● Visual Dynamics
Same size, lighting, and inner glow mechanism — but in red.
Key Difference:
- Rotation is reversed (counter-clockwise)
- Visually distinguishes "buy flow" from "sell flow"
- Allows reading direction at a glance — even for colorblind users
📌 Pole Reading Summary:
🟢 Large + Bright green sphere = Active buying force
🔴 Large + Bright red sphere = Active selling force
🟢🔴 Both large but dim = Energy accumulation (before discharge)
⚪ Both small = Stagnation / Low liquidity
═════════════════════════════════════════════════════════════
🔵 Field Lines (Curved Blue Lines)
═════════════════════════════════════════════════════════════
What do they represent?
Energy flow paths between poles — the arena where price battle is fought.
● Number of Lines
4–16 lines (Default: 8)
More lines: Greater sense of "interaction density"
● Arc Height
arc_h = (i − half_lines) × 15 × field_intensity × 2
- High field intensity = Highly elevated lines (like waves)
- Low intensity = Nearly straight lines
● Oscillating Transparency
transp = 30 + phase × 40
where phase = sin(anim_time × 2 + i × 0.5) × 0.5 + 0.5
Creates illusion of "flowing current" — not static lines
● Asymmetric Curvature
- Upper lines curve upward
- Lower lines curve downward
- Adds 3D depth and shows "pressure" direction
⚡ Pro Tip:
When you see lines suddenly "contract" (straighten), while both spheres are large — this is an early indicator of impending discharge, because the interaction is losing its flexibility.
═════════════════════════════════════════════════════════════
⚪ Moving Particles
═════════════════════════════════════════════════════════════
What do they represent?
Real liquidity flow in the market — who's driving price right now.
● Number and Movement
- 6 particles covering most field lines
- Move sinusoidally along the arc:
t = (sin(phase_val) + 1) / 2
- High speed = High trading activity
- Clustering at a pole = That side's control
● Color Gradient
From green (at positive pole) to red (at negative)
Shows "energy transformation":
- Green particle = Pure buying energy
- Orange particle = Conflict zone
- Red particle = Pure selling energy
📌 How to Read Them?
- Moving left to right (🟢 → 🔴): Buy flow → Bullish push
- Moving right to left (🔴 → 🟢): Sell flow → Bearish push
- Clustered in middle: Balanced conflict — Wait for breakout
═════════════════════════════════════════════════════════════
🟠 Discharge Zone (Orange Glow — Center)
═════════════════════════════════════════════════════════════
What does it represent?
Point of stored energy accumulation not yet discharged — heart of the early warning system.
● Glow Stages
Initial Warning (discharge_prob > 0.3):
- Dim orange circle (70% transparency)
- Meaning: Watch, don't enter yet
High Tension (discharge_prob ≥ 0.7):
- Stronger glow + "⚠️ HIGH TENSION" text
- Meaning: Prepare — Set pending orders
Imminent Discharge (discharge_prob ≥ 0.9):
- Bright glow + "⚡ DISCHARGE IMMINENT" text
- Meaning: Enter with direction (after candle confirmation)
● Layered Glow Effect (Glow Layering)
3 concentric circles with increasing transparency:
- Inner: 20%
- Middle: 35%
- Outer: 50%
Result: Realistic aura resembling actual electrical discharge.
📌 Why in the Center?
Because discharge always starts from the relative balance zone — where opposing pressures meet.
═════════════════════════════════════════════════════════════
📊 Voltage Meter (Bottom of Scene)
═════════════════════════════════════════════════════════════
What does it represent?
Simplified numeric indicator of voltage difference — for those who prefer numerical reading.
● Components
- Gray bar: Full range (−100% to +100%)
- Green fill: Positive voltage (extends right)
- Red fill: Negative voltage (extends left)
- Lightning symbol (⚡): Above center — reminder it's an "electrical gauge"
- Text value: Like "+23.4%" — in direction color
● Voltage Reading Interpretation
+50% to +100%:
Overwhelming buying dominance — Beware of saturation, may precede correction
+20% to +50%:
Strong buying dominance — Suitable for buying with trend
+5% to +20%:
Slight bullish bias — Wait for additional confirmation
−5% to +5%:
Balance/Neutral — Avoid entry or wait for breakout
−5% to −20%:
Slight bearish bias — Wait for confirmation
−20% to −50%:
Strong selling dominance — Suitable for selling with trend
−50% to −100%:
Overwhelming selling dominance — Beware of saturation, may precede bounce
═════════════════════════════════════════════════════════════
📈 Field Strength Indicator (Top of Scene)
═════════════════════════════════════════════════════════════
What it displays: "Field: XX.X%"
Meaning: Strength of conflict between buyers and sellers.
● Reading Interpretation
0–5%:
- Appearance: Nearly straight lines, transparent
- Meaning: Complete control by one side
- Strategy: Trend Following
5–15%:
- Appearance: Slight curvature
- Meaning: Clear direction with light resistance
- Strategy: Enter with trend
15–25%:
- Appearance: Medium curvature, clear lines
- Meaning: Balanced conflict
- Strategy: Range trading or waiting
25–35%:
- Appearance: High curvature, clear density
- Meaning: Strong conflict, high uncertainty
- Strategy: Volatility trading or prepare for discharge
35%+:
- Appearance: Very high lines, strong glow
- Meaning: Peak tension
- Strategy: Best discharge opportunities
📌 Golden Relationship:
Highest discharge probability when:
Field Strength (25–35%) + Voltage (±30–50%) + High Volume
← This is the "red zone" to monitor carefully.
█ Comprehensive Visual Reading
To read market condition at a glance, follow this sequence:
Step 1: Which sphere is larger?
- 🟢 Green larger ← Dominant buying pressure
- 🔴 Red larger ← Dominant selling pressure
- Equal ← Balance/Conflict
Step 2: Which sphere is bright?
- 🟢 Green bright ← Current bullish direction
- 🔴 Red bright ← Current bearish direction
- Both dim ← Neutral/No clear direction
Step 3: Is there orange glow?
- None ← Discharge probability <30%
- 🟠 Dim glow ← Discharge probability 30–70%
- 🟠 Strong glow with text ← Discharge probability >70%
Step 4: What's the voltage meter reading?
- Strong positive ← Confirms buying dominance
- Strong negative ← Confirms selling dominance
- Near zero ← No clear direction
█ Practical Visual Reading Examples
Example 1: Ideal Buy Opportunity ⚡🟢
- Green sphere: Large and bright with inner pulse
- Red sphere: Small and dim
- Orange glow: Strong with "DISCHARGE IMMINENT" text
- Voltage meter: +45%
- Field strength: 28%
Interpretation: Strong accumulated buying pressure, bullish explosion imminent
Example 2: Ideal Sell Opportunity ⚡🔴
- Green sphere: Small and dim
- Red sphere: Large and bright with inner pulse
- Orange glow: Strong with "DISCHARGE IMMINENT" text
- Voltage meter: −52%
- Field strength: 31%
Interpretation: Strong accumulated selling pressure, bearish explosion imminent
Example 3: Balance/Wait ⚖️
- Both spheres: Approximately equal in size
- Lighting: Both dim
- Orange glow: Strong
- Voltage meter: +3%
- Field strength: 24%
Interpretation: Strong conflict without clear winner, wait for breakout
Example 4: Clear Uptrend (No Discharge) 📈
- Green sphere: Large and bright
- Red sphere: Very small and dim
- Orange glow: None
- Voltage meter: +68%
- Field strength: 8%
Interpretation: Clear buying control, limited conflict, suitable for following bullish trend
Example 5: Potential Buying Saturation ⚠️
- Green sphere: Very large and bright
- Red sphere: Very small
- Orange glow: Dim
- Voltage meter: +88%
- Field strength: 4%
Interpretation: Absolute buying dominance, may precede bearish correction
█ Trading Signals
⚡ DISCHARGE IMMINENT
Appearance Conditions:
- discharge_prob ≥ 0.9
- All enabled filters passed
- Confirmed (after candle close)
Interpretation:
- Very large energy accumulation
- Pressure reached critical level
- Price explosion expected within 1–3 candles
How to Trade:
1. Determine voltage direction:
• Positive = Expect rise
• Negative = Expect fall
2. Wait for confirmation candle:
• For rise: Bullish candle closing above its open
• For fall: Bearish candle closing below its open
3. Entry: With next candle's open
4. Stop Loss: Behind last local low/high
5. Target: Risk/Reward ratio of at least 1:2
✅ Pro Tips:
- Best results when combined with support/resistance levels
- Avoid entry if voltage is near zero (±5%)
- Increase position size when field strength > 30%
⚠️ HIGH TENSION
Appearance Conditions:
- 0.7 ≤ discharge_prob < 0.9
Interpretation:
- Market in energy accumulation state
- Likely strong move soon, but not immediate
- Accumulation may continue or discharge may occur
How to Benefit:
- Prepare: Set pending orders at potential breakouts
- Monitor: Watch following candles for momentum candle
- Select: Don't enter every signal — choose those aligned with overall trend
█ Trading Strategies
📈 Strategy 1: Discharge Trading (Basic)
Principle: Enter at "DISCHARGE IMMINENT" in voltage direction
Steps:
1. Wait for "⚡ DISCHARGE IMMINENT"
2. Check voltage direction (+/−)
3. Wait for confirmation candle in voltage direction
4. Enter with next candle's open
5. Stop loss behind last low/high
6. Target: 1:2 or 1:3 ratio
Very high success rate when following confirmation conditions.
📈 Strategy 2: Dominance Following
Principle: Trade with dominant pole (largest and brightest sphere)
Steps:
1. Identify dominant pole (largest and brightest)
2. Trade in its direction
3. Beware when sizes converge (conflict)
Suitable for higher timeframes (H1+).
📈 Strategy 3: Reversal Hunting
Principle: Counter-trend entry under certain conditions
Conditions:
- High field strength (>30%)
- Extreme voltage (>±40%)
- Divergence with price (e.g., new price high with declining voltage)
⚠️ High risk — Use small position size.
📈 Strategy 4: Integration with Technical Analysis
Strong Confirmation Examples:
- Resistance breakout + Bullish discharge = Excellent buy signal
- Support break + Bearish discharge = Excellent sell signal
- Head & Shoulders pattern + Increasing negative voltage = Pattern confirmation
- RSI divergence + High field strength = Potential reversal
█ Ready Alerts
Bullish Discharge
- Condition: discharge_prob ≥ 0.9 + Positive voltage + All filters
- Message: "⚡ Bullish discharge"
- Use: High probability buy opportunity
Bearish Discharge
- Condition: discharge_prob ≥ 0.9 + Negative voltage + All filters
- Message: "⚡ Bearish discharge"
- Use: High probability sell opportunity
✅ Tip: Use these alerts with "Once Per Bar" setting to avoid repetition.
█ Data Window Outputs
Bias
- Values: −1 / 0 / +1
- Interpretation: −1 = Bearish, 0 = Neutral, +1 = Bullish
- Use: For integration in automated strategies
Discharge %
- Range: 0–100%
- Interpretation: Discharge probability
- Use: Monitor tension progression (e.g., from 40% to 85% in 5 candles)
Field Strength
- Range: 0–100%
- Interpretation: Conflict intensity
- Use: Identify "opportunity window" (25–35% ideal for discharge)
Voltage
- Range: −100% to +100%
- Interpretation: Balance of power
- Use: Monitor extremes (potential buying/selling saturation)
█ Optimal Settings by Trading Style
Scalping
- Timeframe: 1M–5M
- Lookback: 10–15
- Threshold: 0.5–0.6
- Sensitivity: 1.2–1.5
- Filters: Volume + Volatility
Day Trading
- Timeframe: 15M–1H
- Lookback: 20
- Threshold: 0.7
- Sensitivity: 1.0
- Filters: Volume + Volatility
Swing Trading
- Timeframe: 4H–D1
- Lookback: 30–50
- Threshold: 0.8
- Sensitivity: 0.8
- Filters: Volatility + Trend
Position Trading
- Timeframe: D1–W1
- Lookback: 50–100
- Threshold: 0.85–0.95
- Sensitivity: 0.5–0.8
- Filters: All filters
█ Tips for Optimal Use
1. Start with Default Settings
Try it first as is, then adjust to your style.
2. Watch for Element Alignment
Best signals when:
- Clear voltage (>│20%│)
- Moderate–high field strength (15–35%)
- High discharge probability (>70%)
3. Use Multiple Timeframes
- Higher timeframe: Determine overall trend
- Lower timeframe: Time entry
- Ensure signal alignment between frames
4. Integrate with Other Tools
- Support/Resistance levels
- Trend lines
- Candle patterns
- Volume indicators
5. Respect Risk Management
- Don't risk more than 1–2% of account
- Always use stop loss
- Don't enter every signal — choose the best
█ Important Warnings
⚠️ Not for Standalone Use
The indicator is an analytical support tool — don't use it isolated from technical or fundamental analysis.
⚠️ Doesn't Predict the Future
Calculations are based on historical data — Results are not guaranteed.
⚠️ Markets Differ
You may need to adjust settings for each market:
- Forex: Focus on Volume Filter
- Stocks: Add Trend Filter
- Crypto: Lower Threshold slightly (more volatile)
⚠️ News and Events
The indicator doesn't account for sudden news — Avoid trading before/during major news.
█ Unique Features
✅ First Application of Electromagnetism to Markets
Innovative mathematical model — Not just an ordinary indicator
✅ Predictive Detection of Price Explosions
Alerts before the move happens — Not after
✅ Multi-Layer Filtering
4 smart filters reduce false signals to minimum
✅ Smart Volatility Adaptation
Automatically adjusts sensitivity based on market conditions
✅ Animated 3D Visual Representation
Makes reading instant — Even for beginners
✅ High Flexibility
Works on all assets: Stocks, Forex, Crypto, Commodities
✅ Built-in Ready Alerts
No complex setup needed — Ready for immediate use
█ Conclusion: When Art Meets Science
Market Electromagnetic Field is not just an indicator — but a new analytical philosophy.
It's the bridge between:
- Physics precision in describing dynamic systems
- Market intelligence in generating trading opportunities
- Visual psychology in facilitating instant reading
The result: A tool that isn't read — but watched, felt, and sensed.
When you see the green sphere expanding, the glow intensifying, and particles rushing rightward — you're not seeing numbers, you're seeing market energy breathing.
⚠️ Disclaimer:
This indicator is for educational and analytical purposes only. It does not constitute financial, investment, or trading advice. Use it in conjunction with your own strategy and risk management. Neither TradingView nor the developer is liable for any financial decisions or losses.
المجال الكهرومغناطيسي للسوق - Market Electromagnetic Field
مؤشر تحليلي مبتكر يقدّم نموذجًا جديدًا كليًّا لفهم ديناميكيات السوق، مستوحى من قوانين الفيزياء الكهرومغناطيسية — لكنه ليس استعارة بلاغية، بل نظام رياضي متكامل.
على عكس المؤشرات التقليدية التي تُركّز على السعر أو الزخم، يُصوّر هذا المؤشر السوق كـنظام فيزيائي مغلق، حيث:
⚡ الشموع = شحنات كهربائية (موجبة عند الإغلاق الصاعد، سالبة عند الهابط)
⚡ المشتريون والبائعون = قطبان متعاكسان يتراكم فيهما الضغط
⚡ التوتر السوقي = فرق جهد بين القطبين
⚡ الاختراق السعري = تفريغ كهربائي بعد تراكم طاقة كافية
█ الفكرة الجوهرية
الأسواق لا تتحرك عشوائيًّا، بل تخضع لدورة فيزيائية واضحة:
تراكم → توتر → تفريغ → استقرار → تراكم جديد
عندما تتراكم الشحنات (من خلال شموع قوية بحجم مرتفع) وتتجاوز "السعة الكهربائية" عتبة معيّنة، يُصدر المؤشر تنبيه "⚡ DISCHARGE IMMINENT" — أي أن انفجارًا سعريًّا وشيكًا، مما يمنح المتداول فرصة الدخول قبل بدء الحركة.
█ الميزة التنافسية
- تنبؤ استباقي (ليس تأكيديًّا بعد الحدث)
- فلترة ذكية متعددة الطبقات تقلل الإشارات الكاذبة
- تمثيل بصري ثلاثي الأبعاد متحرك يجعل قراءة الحالة السعرية فورية وبديهية — دون حاجة لتحليل أرقام
█ الأساس النظري الفيزيائي
المؤشر لا يستخدم مصطلحات فيزيائية للزينة، بل يُطبّق القوانين الرياضية مع تعديلات سوقيّة دقيقة:
⚡ قانون كولوم (Coulomb's Law)
الفيزياء: F = k × (q₁ × q₂) / r²
السوق: شدة الحقل = 4 × norm_positive × norm_negative
تصل لذروتها عند التوازن (0.5 × 0.5 × 4 = 1.0)، وتنخفض عند الهيمنة — لأن الصراع يزداد عند التكافؤ.
⚡ قانون أوم (Ohm's Law)
الفيزياء: V = I × R
السوق: الجهد = norm_positive − norm_negative
يقيس ميزان القوى:
- +1 = هيمنة شرائية مطلقة
- −1 = هيمنة بيعية مطلقة
- 0 = توازن
⚡ السعة الكهربائية (Capacitance)
الفيزياء: C = Q / V
السوق: السعة = |الجهد| × شدة الحقل
تمثّل الطاقة المخزّنة القابلة للتفريغ — تزداد عند وجود تحيّز مع تفاعل عالي.
⚡ التفريغ الكهربائي (Discharge)
الفيزياء: يحدث عند تجاوز عتبة العزل
السوق: احتمال التفريغ = min(السعة / عتبة التفريغ, 1.0)
عندما ≥ 0.9: "⚡ DISCHARGE IMMINENT"
📌 ملاحظة جوهرية:
أقصى سعة لا تحدث عند الهيمنة المطلقة (حيث شدة الحقل = 0)، ولا عند التوازن التام (حيث الجهد = 0)، بل عند انحياز متوسط (±30–50%) مع تفاعل عالي (شدة حقل > 25%) — أي في لحظات "الضغط قبل الاختراق".
█ آلية الحساب التفصيلية
⚡ المرحلة 1: قطبية الشمعة
polarity = (close − open) / (high − low)
- +1.0: شمعة صاعدة كاملة (ماروبوزو صاعد)
- −1.0: شمعة هابطة كاملة (ماروبوزو هابط)
- 0.0: دوجي (لا قرار)
- القيم الوسيطة: تمثّل نسبة جسم الشمعة إلى مداها — مما يقلّل تأثير الشموع ذات الظلال الطويلة
⚡ المرحلة 2: وزن الحجم
vol_weight = volume / SMA(volume, lookback)
شمعة بحجم 150% من المتوسط = شحنة أقوى بـ 1.5 مرة
⚡ المرحلة 3: معامل التكيف (Adaptive Factor)
adaptive_factor = ATR(lookback) / SMA(ATR, lookback × 2)
- في الأسواق المتقلبة: يزيد الحساسية
- في الأسواق الهادئة: يقلل الضوضاء
- يوصى دائمًا بتركه مفعّلًا
⚡ المرحلة 4–6: تراكم وتوحيد الشحنات
تُجمّع الشحنات على lookback شمعة، ثم تُوحّد النسب:
norm_positive = positive_charge / total_charge
norm_negative = negative_charge / total_charge
بحيث: norm_positive + norm_negative = 1 — لتسهيل المقارنة
⚡ المرحلة 7: حسابات الحقل
voltage = norm_positive − norm_negative
field_intensity = 4 × norm_positive × norm_negative × field_sensitivity
capacitance = |voltage| × field_intensity
discharge_prob = min(capacitance / discharge_threshold, 1.0)
█ الإعدادات
⚡ Electromagnetic Model
Lookback Period
- الافتراضي: 20
- النطاق: 5–100
- التوصيات:
- المضاربة: 10–15
- اليومي: 20
- السوينغ: 30–50
- الاستثمار: 50–100
Discharge Threshold
- الافتراضي: 0.7
- النطاق: 0.3–0.95
- التوصيات:
- سرعة + ضوضاء: 0.5–0.6
- توازن: 0.7
- دقة عالية: 0.8–0.95
Field Sensitivity
- الافتراضي: 1.0
- النطاق: 0.5–2.0
- التوصيات:
- تضخيم الصراع: 1.2–1.5
- طبيعي: 1.0
- تهدئة: 0.5–0.8
Adaptive Mode
- الافتراضي: مفعّل
- أبقِه دائمًا مفعّلًا
🔬 Dynamic Filters
يجب اجتياز جميع الفلاتر المفعّلة لظهور إشارة التفريغ.
Volume Filter
- الشرط: volume > SMA(volume) × vol_multiplier
- الوظيفة: يستبعد الشموع "الضعيفة" غير المدعومة بحجم
- التوصية: مفعّل (خاصة للأسهم والعملات)
Volatility Filter
- الشرط: STDEV > SMA(STDEV) × 0.5
- الوظيفة: يتجاهل فترات الركود الجانبي
- التوصية: مفعّل دائمًا
Trend Filter
- الشرط: توافق الجهد مع EMA سريع/بطيء
- الوظيفة: يقلل الإشارات المعاكسة للاتجاه العام
- التوصية: مفعّل للسوينغ/الاستثمار فقط
Volume Threshold
- الافتراضي: 1.2
- التوصيات:
- 1.0–1.2: حساسية عالية
- 1.5–2.0: حصرية للحجم العالي
🎨 Visual Settings
الإعدادات تُحسّن تجربة القراءة البصرية — لا تؤثر على الحسابات.
Scale Factor
- الافتراضي: 600
- كلما زاد: المشهد أكبر (200–1200)
Horizontal Shift
- الافتراضي: 180
- إزاحة أفقيّة لليسار — ليركّز على آخر شمعة
Pole Size
- الافتراضي: 60
- حجم الكرات الأساسية (30–120)
Field Lines
- الافتراضي: 8
- عدد خطوط الحقل (4–16) — 8 توازن مثالي
الألوان
- أخضر/أحمر/أزرق/برتقالي
- قابلة للتخصيص بالكامل
█ التمثيل البصري: لغة بصرية لتشخيص الحالة السعرية
✨ الفلسفة التصميمية
التمثيل ليس "زينة"، بل نموذج معرفي متكامل — كل عنصر يحمل معلومة، وتفاعل العناصر يروي قصة كاملة.
العقل يدرك التغيير في الحجم، اللون، والحركة أسرع بـ 60,000 مرة من قراءة الأرقام — لذا يمكنك "الإحساس" بالتغير قبل أن تُنهي العين المسح.
═════════════════════════════════════════════════════════════
🟢 القطب الموجب (الكرة الخضراء — يسار)
═════════════════════════════════════════════════════════════
ماذا يمثّل؟
تراكم ضغط الشراء النشط — ليس مجرد اتجاه صاعد، بل قوة طلب حقيقية مدعومة بحجم وتقلّب.
● الحجم المتغير
حجم = pole_size × (0.7 + norm_positive × 0.6)
- 70% من الحجم الأساسي = لا شحنة تُذكر
- 130% من الحجم الأساسي = هيمنة تامة
- كلما كبرت الكرة: زاد تفوّق المشترين، وارتفع احتمال الاستمرار الصعودي
تفسير الحجم:
- كرة كبيرة (>55%): ضغط شراء قوي — المشترون يسيطرون
- كرة متوسطة (45–55%): توازن نسبي مع ميل للشراء
- كرة صغيرة (<45%): ضعف ضغط الشراء — البائعون يسيطرون
● الإضاءة والشفافية
- شفافية 20% (عند Bias = +1): القطب نشط حالياً — الاتجاه صعودي
- شفافية 50% (عند Bias ≠ +1): القطب غير نشط — ليس الاتجاه السائد
الإضاءة = النشاط الحالي، بينما الحجم = التراكم التاريخي
● التوهج الداخلي النابض
كرة أصغر تنبض تلقائيًّا عند Bias = +1:
inner_pulse = 0.4 + 0.1 × sin(anim_time × 3)
يرمز إلى استمرارية تدفق أوامر الشراء — وليس هيمنة جامدة.
● الحلقات المدارية
حلقتان تدوران بسرعات واتجاهات مختلفة:
- الداخلية: 1.3× حجم الكرة — نطاق التأثير المباشر
- الخارجية: 1.6× حجم الكرة — نطاق التأثير الممتد
تمثّل "نطاق تأثير" المشترين:
- الدوران المستمر = استقرار وزخم
- التباطؤ = نفاد الزخم
● النسبة المئوية
تظهر تحت الكرة: norm_positive × 100
- >55% = هيمنة واضحة
- 45–55% = توازن
- <45% = ضعف
═════════════════════════════════════════════════════════════
🔴 القطب السالب (الكرة الحمراء — يمين)
═════════════════════════════════════════════════════════════
ماذا يمثّل؟
تراكم ضغط البيع النشط — سواء كان بيعًا تراكميًّا (التوزيع الذكي) أو بيعًا هستيريًّا (تصفية مراكز).
● الديناميكيات البصرية
نفس آلية الحجم والإضاءة والتوهج الداخلي — لكن باللون الأحمر.
الفرق الجوهري:
- الدوران معكوس (عكس اتجاه عقارب الساعة)
- يُميّز بصريًّا بين "تدفق الشراء" و"تدفق البيع"
- يسمح بقراءة الاتجاه بنظرة واحدة — حتى للمصابين بعَمَى الألوان
📌 ملخص قراءة القطبين:
🟢 كرة خضراء كبيرة + مضيئة = قوة شرائية نشطة
🔴 كرة حمراء كبيرة + مضيئة = قوة بيعية نشطة
🟢🔴 كرتان كبيرتان لكن خافتتان = تراكم طاقة (قبل التفريغ)
⚪ كرتان صغيرتان = ركود / سيولة منخفضة
═════════════════════════════════════════════════════════════
🔵 خطوط الحقل (الخطوط الزرقاء المنحنية)
═════════════════════════════════════════════════════════════
ماذا تمثّل؟
مسارات تدفق الطاقة بين القطبين — أي الساحة التي تُدار فيها المعركة السعرية.
● عدد الخطوط
4–16 خط (الافتراضي: 8)
كلما زاد العدد: زاد إحساس "كثافة التفاعل"
● ارتفاع القوس
arc_h = (i − half_lines) × 15 × field_intensity × 2
- شدة حقل عالية = خطوط شديدة الارتفاع (مثل موجة)
- شدة منخفضة = خطوط شبه مستقيمة
● الشفافية المتذبذبة
transp = 30 + phase × 40
حيث phase = sin(anim_time × 2 + i × 0.5) × 0.5 + 0.5
تخلق وهم "تيّار متدفّق" — وليس خطوطًا ثابتة
● الانحناء غير المتناظر
- الخطوط العلوية تنحني لأعلى
- الخطوط السفلية تنحني لأسفل
- يُضفي عمقًا ثلاثي الأبعاد ويُظهر اتجاه "الضغط"
⚡ تلميح احترافي:
عندما ترى الخطوط "تتقلّص" فجأة (تستقيم)، بينما الكرتان كبيرتان — فهذا مؤشر مبكر على قرب التفريغ، لأن التفاعل بدأ يفقد مرونته.
═════════════════════════════════════════════════════════════
⚪ الجزيئات المتحركة
═════════════════════════════════════════════════════════════
ماذا تمثّل؟
تدفق السيولة الحقيقية في السوق — أي من يدفع السعر الآن.
● العدد والحركة
- 6 جزيئات تغطي معظم خطوط الحقل
- تتحرك جيبيًّا على طول القوس:
t = (sin(phase_val) + 1) / 2
- سرعة عالية = نشاط تداول عالي
- تجمّع عند قطب = سيطرة هذا الطرف
● تدرج اللون
من أخضر (عند القطب الموجب) إلى أحمر (عند السالب)
يُظهر "تحوّل الطاقة":
- جزيء أخضر = طاقة شرائية نقية
- جزيء برتقالي = منطقة صراع
- جزيء أحمر = طاقة بيعية نقية
📌 كيف تقرأها؟
- تحركت من اليسار لليمين (🟢 → 🔴): تدفق شرائي → دفع صعودي
- تحركت من اليمين لليسار (🔴 → 🟢): تدفق بيعي → دفع هبوطي
- تجمّعت في المنتصف: صراع متكافئ — انتظر اختراقًا
═════════════════════════════════════════════════════════════
🟠 منطقة التفريغ (التوهج البرتقالي — المركز)
═════════════════════════════════════════════════════════════
ماذا تمثّل؟
نقطة تراكم الطاقة المخزّنة التي لم تُفرّغ بعد — قلب نظام الإنذار المبكر.
● مراحل التوهج
إنذار أولي (discharge_prob > 0.3):
- دائرة برتقالية خافتة (شفافية 70%)
- المعنى: راقب، لا تدخل بعد
توتر عالي (discharge_prob ≥ 0.7):
- توهج أقوى + نص "⚠️ HIGH TENSION"
- المعنى: استعد — ضع أوامر معلقة
تفريغ وشيك (discharge_prob ≥ 0.9):
- توهج ساطع + نص "⚡ DISCHARGE IMMINENT"
- المعنى: ادخل مع الاتجاه (بعد تأكيد شمعة)
● تأثير التوهج الطبقي (Glow Layering)
3 دوائر متحدة المركز بشفافية متزايدة:
- داخلي: 20%
- وسط: 35%
- خارجي: 50%
النتيجة: هالة (Aura) واقعية تشبه التفريغ الكهربائي الحقيقي.
📌 لماذا في المركز؟
لأن التفريغ يبدأ دائمًا من منطقة التوازن النسبي — حيث يلتقي الضغطان المتعاكسان.
═════════════════════════════════════════════════════════════
📊 مقياس الجهد (أسفل المشهد)
═════════════════════════════════════════════════════════════
ماذا يمثّل؟
مؤشر رقمي مبسّط لفرق الجهد — لمن يفضّل القراءة العددية.
● المكونات
- الشريط الرمادي: النطاق الكامل (−100% إلى +100%)
- التعبئة الخضراء: جهد موجب (تمتد لليمين)
- التعبئة الحمراء: جهد سالب (تمتد لليسار)
- رمز البرق (⚡): فوق المركز — تذكير بأنه "مقياس كهربائي"
- القيمة النصية: مثل "+23.4%" — بلون الاتجاه
● تفسير قراءات الجهد
+50% إلى +100%:
هيمنة شرائية ساحقة — احذر التشبع، قد يسبق تصحيح
+20% إلى +50%:
هيمنة شرائية قوية — مناسب للشراء مع الاتجاه
+5% إلى +20%:
ميل صعودي خفيف — انتظر تأكيدًا إضافيًّا
−5% إلى +5%:
توازن/حياد — تجنّب الدخول أو انتظر اختراقًا
−5% إلى −20%:
ميل هبوطي خفيف — انتظر تأكيدًا
−20% إلى −50%:
هيمنة بيعية قوية — مناسب للبيع مع الاتجاه
−50% إلى −100%:
هيمنة بيعية ساحقة — احذر التشبع، قد يسبق ارتداد
═════════════════════════════════════════════════════════════
📈 مؤشر شدة الحقل (أعلى المشهد)
═════════════════════════════════════════════════════════════
ما يعرضه: "Field: XX.X%"
الدلالة: قوة الصراع بين المشترين والبائعين.
● تفسير القراءات
0–5%:
- المظهر: خطوط مستقيمة تقريبًا، شفافة
- المعنى: سيطرة تامة لأحد الطرفين
- الاستراتيجية: تتبع الترند (Trend Following)
5–15%:
- المظهر: انحناء خفيف
- المعنى: اتجاه واضح مع مقاومة خفيفة
- الاستراتيجية: الدخول مع الاتجاه
15–25%:
- المظهر: انحناء متوسط، خطوط واضحة
- المعنى: صراع متوازن
- الاستراتيجية: تداول النطاق أو الانتظار
25–35%:
- المظهر: انحناء عالي، كثافة واضحة
- المعنى: صراع قوي، عدم يقين عالي
- الاستراتيجية: تداول التقلّب أو الاستعداد للتفريغ
35%+:
- المظهر: خطوط عالية جدًّا، توهج قوي
- المعنى: ذروة التوتر
- الاستراتيجية: أفضل فرص التفريغ
📌 العلاقة الذهبية:
أعلى احتمال تفريغ عندما:
شدة الحقل (25–35%) + جهد (±30–50%) + حجم مرتفع
← هذه هي "المنطقة الحمراء" التي يجب مراقبتها بدقة.
█ قراءة التمثيل البصري الشاملة
لقراءة حالة السوق بنظرة واحدة، اتبع هذا التسلسل:
الخطوة 1: أي كرة أكبر؟
- 🟢 الخضراء أكبر ← ضغط شراء مهيمن
- 🔴 الحمراء أكبر ← ضغط بيع مهيمن
- متساويتان ← توازن/صراع
الخطوة 2: أي كرة مضيئة؟
- 🟢 الخضراء مضيئة ← اتجاه صعودي حالي
- 🔴 الحمراء مضيئة ← اتجاه هبوطي حالي
- كلاهما خافت ← حياد/لا اتجاه واضح
الخطوة 3: هل يوجد توهج برتقالي؟
- لا يوجد ← احتمال تفريغ <30%
- 🟠 توهج خافت ← احتمال تفريغ 30–70%
- 🟠 توهج قوي مع نص ← احتمال تفريغ >70%
الخطوة 4: ما قراءة مقياس الجهد؟
- موجب قوي ← تأكيد الهيمنة الشرائية
- سالب قوي ← تأكيد الهيمنة البيعية
- قريب من الصفر ← لا اتجاه واضح
█ أمثلة عملية للقراءة البصرية
المثال 1: فرصة شراء مثالية ⚡🟢
- الكرة الخضراء: كبيرة ومضيئة مع نبض داخلي
- الكرة الحمراء: صغيرة وخافتة
- التوهج البرتقالي: قوي مع نص "DISCHARGE IMMINENT"
- مقياس الجهد: +45%
- شدة الحقل: 28%
التفسير: ضغط شراء قوي متراكم، انفجار صعودي وشيك
المثال 2: فرصة بيع مثالية ⚡🔴
- الكرة الخضراء: صغيرة وخافتة
- الكرة الحمراء: كبيرة ومضيئة مع نبض داخلي
- التوهج البرتقالي: قوي مع نص "DISCHARGE IMMINENT"
- مقياس الجهد: −52%
- شدة الحقل: 31%
التفسير: ضغط بيع قوي متراكم، انفجار هبوطي وشيك
المثال 3: توازن/انتظار ⚖️
- الكرتان: متساويتان تقريباً في الحجم
- الإضاءة: كلاهما خافت
- التوهج البرتقالي: قوي
- مقياس الجهد: +3%
- شدة الحقل: 24%
التفسير: صراع قوي بدون فائز واضح، انتظر اختراقًا
المثال 4: اتجاه صعودي واضح (لا تفريغ) 📈
- الكرة الخضراء: كبيرة ومضيئة
- الكرة الحمراء: صغيرة جداً وخافتة
- التوهج البرتقالي: لا يوجد
- مقياس الجهد: +68%
- شدة الحقل: 8%
التفسير: سيطرة شرائية واضحة، صراع محدود، مناسب لتتبع الترند الصعودي
المثال 5: تشبع شرائي محتمل ⚠️
- الكرة الخضراء: كبيرة جداً ومضيئة
- الكرة الحمراء: صغيرة جداً
- التوهج البرتقالي: خافت
- مقياس الجهد: +88%
- شدة الحقل: 4%
التفسير: هيمنة شرائية مطلقة، قد يسبق تصحيحاً هبوطياً
█ إشارات التداول
⚡ DISCHARGE IMMINENT (التفريغ الوشيك)
شروط الظهور:
- discharge_prob ≥ 0.9
- اجتياز جميع الفلاتر المفعّلة
- Confirmed (بعد إغلاق الشمعة)
التفسير:
- تراكم طاقة كبير جدًّا
- الضغط وصل لمستوى حرج
- انفجار سعري متوقع خلال 1–3 شموع
كيفية التداول:
1. حدد اتجاه الجهد:
• موجب = توقع صعود
• سالب = توقع هبوط
2. انتظر شمعة تأكيدية:
• للصعود: شمعة صاعدة تغلق فوق افتتاحها
• للهبوط: شمعة هابطة تغلق تحت افتتاحها
3. الدخول: مع افتتاح الشمعة التالية
4. وقف الخسارة: وراء آخر قاع/قمة محلية
5. الهدف: نسبة مخاطرة/عائد 1:2 على الأقل
✅ نصائح احترافية:
- أفضل النتائج عند دمجها مع مستويات الدعم/المقاومة
- تجنّب الدخول إذا كان الجهد قريبًا من الصفر (±5%)
- زِد حجم المركز عند شدة حقل > 30%
⚠️ HIGH TENSION (التوتر العالي)
شروط الظهور:
- 0.7 ≤ discharge_prob < 0.9
التفسير:
- السوق في حالة تراكم طاقة
- احتمال حركة قوية قريبة، لكن ليست فورية
- قد يستمر التراكم أو يحدث تفريغ
كيفية الاستفادة:
- الاستعداد: حضّر أوامر معلقة عند الاختراقات المحتملة
- المراقبة: راقب الشموع التالية بحثًا عن شمعة دافعة
- الانتقاء: لا تدخل كل إشارة — اختر تلك التي تتوافق مع الاتجاه العام
█ استراتيجيات التداول
📈 استراتيجية 1: تداول التفريغ (الأساسية)
المبدأ: الدخول عند "DISCHARGE IMMINENT" في اتجاه الجهد
الخطوات:
1. انتظر ظهور "⚡ DISCHARGE IMMINENT"
2. تحقق من اتجاه الجهد (+/−)
3. انتظر شمعة تأكيدية في اتجاه الجهد
4. ادخل مع افتتاح الشمعة التالية
5. وقف الخسارة وراء آخر قاع/قمة
6. الهدف: نسبة 1:2 أو 1:3
نسبة نجاح عالية جدًّا عند الالتزام بشروط التأكيد.
📈 استراتيجية 2: تتبع الهيمنة
المبدأ: التداول مع القطب المهيمن (الكرة الأكبر والأكثر إضاءة)
الخطوات:
1. حدد القطب المهيمن (الأكبر حجماً والأكثر إضاءة)
2. تداول في اتجاهه
3. احذر عند تقارب الأحجام (صراع)
مناسبة للإطارات الزمنية الأعلى (H1+).
📈 استراتيجية 3: صيد الانعكاس
المبدأ: الدخول عكس الاتجاه عند ظروف معينة
الشروط:
- شدة حقل عالية (>30%)
- جهد متطرف (>±40%)
- تباعد مع السعر (مثل: قمة سعرية جديدة مع تراجع الجهد)
⚠️ عالية المخاطرة — استخدم حجم مركز صغير.
📈 استراتيجية 4: الدمج مع التحليل الفني
أمثلة تأكيد قوي:
- اختراق مقاومة + تفريغ صعودي = إشارة شراء ممتازة
- كسر دعم + تفريغ هبوطي = إشارة بيع ممتازة
- نموذج Head & Shoulders + جهد سالب متزايد = تأكيد النموذج
- تباعد RSI + شدة حقل عالية = انعكاس محتمل
█ التنبيهات الجاهزة
Bullish Discharge
- الشرط: discharge_prob ≥ 0.9 + جهد موجب + جميع الفلاتر
- الرسالة: "⚡ Bullish discharge"
- الاستخدام: فرصة شراء عالية الاحتمالية
Bearish Discharge
- الشرط: discharge_prob ≥ 0.9 + جهد سالب + جميع الفلاتر
- الرسالة: "⚡ Bearish discharge"
- الاستخدام: فرصة بيع عالية الاحتمالية
✅ نصيحة: استخدم هذه التنبيهات مع إعداد "Once Per Bar" لتجنب التكرار.
█ المخرجات في نافذة البيانات
Bias
- القيم: −1 / 0 / +1
- التفسير: −1 = هبوطي، 0 = حياد، +1 = صعودي
- الاستخدام: لدمجها في استراتيجيات آلية
Discharge %
- النطاق: 0–100%
- التفسير: احتمال التفريغ
- الاستخدام: مراقبة تدرّج التوتر (مثال: من 40% إلى 85% في 5 شموع)
Field Strength
- النطاق: 0–100%
- التفسير: شدة الصراع
- الاستخدام: تحديد "نافذة الفرص" (25–35% مثالية للتفريغ)
Voltage
- النطاق: −100% إلى +100%
- التفسير: ميزان القوى
- الاستخدام: مراقبة التطرف (تشبع شرائي/بيعي محتمل)
█ الإعدادات المثلى حسب أسلوب التداول
المضاربة (Scalping)
- الإطار: 1M–5M
- Lookback: 10–15
- Threshold: 0.5–0.6
- Sensitivity: 1.2–1.5
- الفلاتر: Volume + Volatility
التداول اليومي (Day Trading)
- الإطار: 15M–1H
- Lookback: 20
- Threshold: 0.7
- Sensitivity: 1.0
- الفلاتر: Volume + Volatility
السوينغ (Swing Trading)
- الإطار: 4H–D1
- Lookback: 30–50
- Threshold: 0.8
- Sensitivity: 0.8
- الفلاتر: Volatility + Trend
الاستثمار (Position Trading)
- الإطار: D1–W1
- Lookback: 50–100
- Threshold: 0.85–0.95
- Sensitivity: 0.5–0.8
- الفلاتر: جميع الفلاتر
█ نصائح للاستخدام الأمثل
1. ابدأ بالإعدادات الافتراضية
جرّبه أولًا كما هو، ثم عدّل حسب أسلوبك.
2. راقب التوافق بين العناصر
أفضل الإشارات عندما:
- الجهد واضح (>│20%│)
- شدة الحقل معتدلة–عالية (15–35%)
- احتمال التفريغ مرتفع (>70%)
3. استخدم أطر زمنية متعددة
- الإطار الأعلى: تحديد الاتجاه العام
- الإطار الأدنى: توقيت الدخول
- تأكد من توافق الإشارات بين الأطر
4. دمج مع أدوات أخرى
- مستويات الدعم/المقاومة
- خطوط الاتجاه
- أنماط الشموع
- مؤشرات الحجم
5. احترم إدارة المخاطرة
- لا تخاطر بأكثر من 1–2% من الحساب
- استخدم دائمًا وقف الخسارة
- لا تدخل كل الإشارات — اختر الأفضل
█ تحذيرات مهمة
⚠️ ليس للاستخدام المنفرد
المؤشر أداة تحليل مساعِدة — لا تستخدمه بمعزل عن التحليل الفني أو الأساسي.
⚠️ لا يتنبأ بالمستقبل
الحسابات مبنية على البيانات التاريخية — النتائج ليست مضمونة.
⚠️ الأسواق تختلف
قد تحتاج لضبط الإعدادات لكل سوق:
- العملات: تركّز على Volume Filter
- الأسهم: أضف Trend Filter
- الكريبتو: خفّض Threshold قليلًا (أكثر تقلّبًا)
⚠️ الأخبار والأحداث
المؤشر لا يأخذ في الاعتبار الأخبار المفاجئة — تجنّب التداول قبل/أثناء الأخبار الرئيسية.
█ الميزات الفريدة
✅ أول تطبيق للكهرومغناطيسية على الأسواق
نموذج رياضي مبتكر — ليس مجرد مؤشر عادي
✅ كشف استباقي للانفجارات السعرية
يُنبّه قبل حدوث الحركة — وليس بعدها
✅ تصفية متعددة الطبقات
4 فلاتر ذكية تقلل الإشارات الكاذبة إلى الحد الأدنى
✅ تكيف ذكي مع التقلب
يضبط حساسيته تلقائيًّا حسب ظروف السوق
✅ تمثيل بصري ثلاثي الأبعاد متحرك
يجعل القراءة فورية — حتى للمبتدئين
✅ مرونة عالية
يعمل على جميع الأصول: أسهم، عملات، كريبتو، سلع
✅ تنبيهات مدمجة جاهزة
لا حاجة لإعدادات معقدة — جاهز للاستخدام الفوري
█ خاتمة: عندما يلتقي الفن بالعلم
Market Electromagnetic Field ليس مجرد مؤشر — بل فلسفة تحليلية جديدة.
هو الجسر بين:
- دقة الفيزياء في وصف الأنظمة الديناميكية
- ذكاء السوق في توليد فرص التداول
- علم النفس البصري في تسهيل القراءة الفورية
النتيجة: أداة لا تُقرأ — بل تُشاهد، تُشعر، وتُستشعر.
عندما ترى الكرة الخضراء تتوسع، والتوهج يصفرّ، والجزيئات تندفع لليمين — فأنت لا ترى أرقامًا، بل ترى طاقة السوق تتنفّس.
⚠️ إخلاء مسؤولية:
هذا المؤشر لأغراض تعليمية وتحليلية فقط. لا يُمثل نصيحة مالية أو استثمارية أو تداولية. استخدمه بالتزامن مع استراتيجيتك الخاصة وإدارة المخاطر. لا يتحمل TradingView ولا المطور مسؤولية أي قرارات مالية أو خسائر.
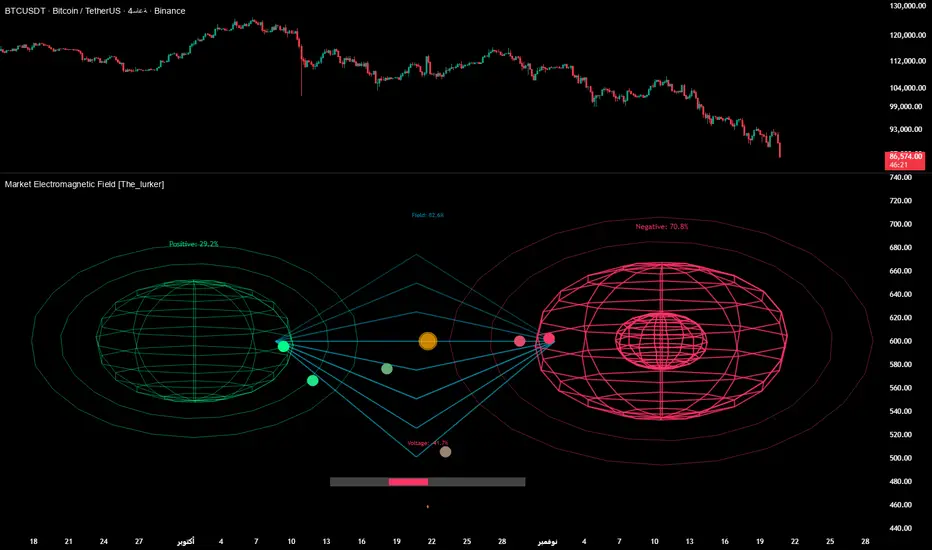
Adaptive Quadratic Kernel EnvelopeThis study draws a fair-value curve from a quadratic-weighted (Nadaraya-Watson) regression. Alpha sets how sharply weights decay inside the look-back window, so you trade lag against smoothness with one slider. Band half-width is ATRslow times a bounded fast/slow ATR ratio, giving an instant response to regime shifts without overshooting on spikes. Work in log space when an instrument grows exponentially, equal percentage moves then map to equal vertical steps. NearBase and FarBase define a progression of adaptive thresholds, useful for sizing exits or calibrating mean-reversion logic. Non-repaint mode keeps one-bar delay for clean back-tests, predictive mode shows the zero-lag curve for live decisions.
Key points
- Quadratic weights cut phase error versus Gaussian or SMA-based envelopes.
- Dual-ATR scaling updates width on the next bar, no residual lag.
- Log option preserves envelope symmetry across multi-decade data.
- Alpha provides direct control of curvature versus noise.
- Built-in alerts trigger on the first adaptive threshold, ready for automation.
Typical uses
Trend bias from the slope of the curve.
Entry timing when price pierces an inner threshold and momentum stalls.
Breakout confirmation when closes hold beyond outer thresholds while volatility expands.
Stops and targets anchored to chosen thresholds, automatically matching current noise.

Linear Regression Forecast (ADX Adaptive)Linear Regression Forecast (ADX Adaptive)
This indicator is a dynamic price projection tool that combines multiple linear regression forecasts into a single, adaptive forecast curve. By integrating trend strength via the ADX and directional bias, it aims to visualize how price might evolve in different market environments—from strong trends to mean-reverting conditions.
Core Concept:
This tool builds forward price projections based on a blend of linear regression models with varying lookback lengths (from 2 up to a user-defined max). It then adjusts those projections using two key mechanisms:
ADX-Weighted Forecast Blending
In trending conditions (high ADX), the model follows the raw forecast direction. In ranging markets (low ADX), the forecast flips or reverts, biasing toward mean-reversion. A logistic transformation of directional bias, controlled by a steepness parameter, determines how aggressively this blending reacts to price behavior.
Volatility Scaling
The forecast’s magnitude is scaled based on ADX and directional conviction. When trends are unclear (low ADX or neutral bias), the projection range expands to reflect greater uncertainty and volatility.
How It Works:
Regression Curve Generation
For each regression length from 2 to maxLength, a forward projection is calculated using least-squares linear regression on the selected price source. These forecasts are extrapolated into the future.
Directional Bias Calculation
The forecasted points are analyzed to determine a normalized bias value in the range -1 to +1, where +1 means strongly bullish, -1 means strongly bearish, and 0 means neutral.
Logistic Bias Transformation
The raw bias is passed through a logistic sigmoid function, with a user-defined steepness. This creates a probability-like weight that favors either following or reversing the forecast depending on market context.
ADX-Based Weighting
ADX determines the weighting between trend-following and mean-reversion modes. Below ADX 20, the model favors mean-reversion. Above 25, it favors trend-following. Between 20 and 25, it linearly blends the two.
Blended Forecast Curve
Each forecast point is blended between trend-following and mean-reverting values, scaled for volatility.
What You See:
Forecast Lines: Projected future price paths drawn in green or red depending on direction.
Bias Plot: A separate plot showing post-blend directional bias as a percentage, where +100 is strongly bullish and -100 is strongly bearish.
Neutral Line: A dashed horizontal line at 0 percent bias to indicate neutrality.
User Inputs:
-Max Regression Length
-Price Source
-Line Width
-Bias Steepness
-ADX Length and Smoothing
Use Cases:
Visualize expected price direction under different trend conditions
Adjust trading behavior depending on trending vs ranging markets
Combine with other tools for deeper analysis
Important Notes:
This indicator is for visualization and analysis only. It does not provide buy or sell signals and should not be used in isolation. It makes assumptions based on historical price action and should be interpreted with market context.
Exponential growthPurpose
The indicator plots an exponential curve based on historical price data and supports toggling between exponential regression and linear logarithmic regression. It also provides offset bands around the curve for additional insights.
Key Inputs
1. yxlogreg and dlogreg:
These are the "Endwert" (end value) and "Startwert" (start value) for calculating the slope of the logarithmic regression.
2. bars:
Specifies how many historical bars are considered in the calculation.
3.offsetchannel:
Adds an adjustable percentage-based offset to create upper and lower bands around the main exponential curve.
Default: 1 (interpreted as 10% bands).
4.lineareregression log.:
A toggle to switch between exponential function and linear logarithmic regression.
Default: false (exponential is used by default).
5.Dynamic Labels:
Creates a label showing the calculated regression values and historical bars count at the latest bar. The label is updated dynamically.
Use Cases
Exponential Growth Tracking:
Useful for assets or instruments exhibiting exponential growth trends.
Identifying Channels:
Helps identify support and resistance levels using the offset bands.
Switching Analysis Modes:
Flexibility to toggle between exponential and linear logarithmic analysis.
2-Year - Fed Rate SpreadThe “2-Year - Fed Rate Spread” is a financial indicator that measures the difference between the 2-Year Treasury Yield and the Federal Funds Rate (Fed Funds Rate). This spread is often used as a gauge of market sentiment regarding the future direction of interest rates and economic conditions.
Calculation
• 2-Year Treasury Yield: This is the return on investment, expressed as a percentage, on the U.S. government’s debt obligations that mature in two years.
• Federal Funds Rate: The interest rate at which depository institutions trade federal funds (balances held at Federal Reserve Banks) with each other overnight.
The indicator calculates the spread by subtracting the Fed Funds Rate from the 2-Year Treasury Yield:
{2-Year - Fed Rate Spread} = {2-Year Treasury Yield} - {Fed Funds Rate}
Interpretation:
• Positive Spread: A positive spread (2-Year Treasury Yield > Fed Funds Rate) typically suggests that the market expects the Fed to raise rates in the future, indicating confidence in economic growth.
• Negative Spread: A negative spread (2-Year Treasury Yield < Fed Funds Rate) can indicate market expectations of a rate cut, often signaling concerns about an economic slowdown or recession. When the spread turns negative, the indicator’s background turns red, making it visually easy to identify these periods.
How to Use:
• Trend Analysis: Investors and analysts can use this spread to assess the market’s expectations for future monetary policy. A persistent negative spread may suggest a cautious approach to equity investments, as it often precedes economic downturns.
• Confirmation Tool: The spread can be used alongside other economic indicators, such as the yield curve, to confirm signals about the direction of interest rates and economic activity.
Research and Academic References:
The 2-Year - Fed Rate Spread is part of a broader analysis of yield spreads and their implications for economic forecasting. Several academic studies have examined the predictive power of yield spreads, including those that involve the 2-Year Treasury Yield and Fed Funds Rate:
1. Estrella, Arturo, and Frederic S. Mishkin (1998). “Predicting U.S. Recessions: Financial Variables as Leading Indicators.” The Review of Economics and Statistics, 80(1): 45-61.
• This study explores the predictive power of various financial variables, including yield spreads, in forecasting U.S. recessions. The authors find that the yield spread is a robust leading indicator of economic downturns.
2. Estrella, Arturo, and Gikas A. Hardouvelis (1991). “The Term Structure as a Predictor of Real Economic Activity.” The Journal of Finance, 46(2): 555-576.
• The paper examines the relationship between the term structure of interest rates (including short-term spreads like the 2-Year - Fed Rate) and future economic activity. The study finds that yield spreads are significant predictors of future economic performance.
3. Rudebusch, Glenn D., and John C. Williams (2009). “Forecasting Recessions: The Puzzle of the Enduring Power of the Yield Curve.” Journal of Business & Economic Statistics, 27(4): 492-503.
• This research investigates why the yield curve, particularly spreads involving short-term rates like the 2-Year Treasury Yield, remains a powerful tool for forecasting recessions despite changes in monetary policy.
Conclusion:
The 2-Year - Fed Rate Spread is a valuable tool for market participants seeking to understand future interest rate movements and potential economic conditions. By monitoring the spread, especially when it turns negative, investors can gain insights into market sentiment and adjust their strategies accordingly. The academic research supports the use of such yield spreads as reliable indicators of future economic activity.
Dynamic Gradient Filter
Sigmoid Functions:
History and Mathematical Basis:
Sigmoid functions have a rich history in mathematics and are widely used in various fields, including statistics, machine learning, and signal processing.
The term "sigmoid" originates from the Greek words "sigma" (meaning "S-shaped") and "eidos" (meaning "form" or "type").
The sigmoid curve is characterized by its smooth S-shaped appearance, which allows it to map any real-valued input to a bounded output range, typically between 0 and 1.
The most common form of the sigmoid function is the logistic function:
Logistic Function (σ):
Defined as σ(x) = 1 / (1 + e^(-x)), where:
'x' is the input value,
'e' is Euler's number (approximately 2.71828).
This function was first introduced by Belgian mathematician Pierre François Verhulst in the 1830s to model population growth with limiting factors.
It gained popularity in the early 20th century when statisticians like Ronald Fisher began using it in regression analysis.
Specific Sigmoid Functions Used in the Indicator:
sig(val):
The 'sig' function in this indicator is a modified version of the logistic function, clamping a value between 0 and 1 on the sigmoid curve.
siga(val):
The 'siga' function adjusts values between -1 and 1 on the sigmoid curve, offering a centered variation of the sigmoid effect.
sigmoid(val):
The 'sigmoid' function provides a standard implementation of the logistic function, calculating the sigmoid value of the input data.
Adaptive Smoothing Factor:
The ' adaptiveSmoothingFactor(gradient, k)' function computes a dynamic smoothing factor for the filter based on the gradient of the price data and the user-defined sensitivity parameter 'k' .
Gradient:
The gradient represents the rate of change in price, calculated as the absolute difference between the current and previous close prices.
Sensitivity (k):
The 'k' parameter adjusts how quickly the filter reacts to changes in the gradient. Higher values of 'k' lead to a more responsive filter, while lower values result in smoother outputs.
Usage in the Indicator:
The "close" value refers to the closing price of each period in the chart's time frame
The indicator calculates the gradient by measuring the absolute difference between the current "close" price and the previous "close" price.
This gradient represents the strength or magnitude of the price movement within the chosen time frame.
The "close" value plays a pivotal role in determining the dynamic behavior of the "Dynamic Gradient Filter," as it directly influences the smoothing factor.
What Makes This Special:
The "Dynamic Gradient Filter" indicator stands out due to its adaptive nature and responsiveness to changing market conditions.
Dynamic Smoothing Factor:
The indicator's dynamic smoothing factor adjusts in real-time based on the rate of change in price (gradient) and the user-defined sensitivity '(k)' parameter.
This adaptability allows the filter to respond promptly to both minor fluctuations and significant price movements.
Smoothed Price Action:
The final output of the filter is a smoothed representation of the price action, aiding traders in identifying trends and potential reversals.
Customizable Sensitivity:
Traders can adjust the 'Sensitivity' parameter '(k)' to suit their preferred trading style, making the indicator versatile for various strategies.
Visual Clarity:
The plotted "Dynamic Gradient Filter" line on the chart provides a clear visual guide, enhancing the understanding of market dynamics.
Usage:
Traders and analysts can utilize the "Dynamic Gradient Filter" to:
Identify trends and reversals in price movements.
Filter out noise and highlight significant price changes.
Fine-tune trading strategies by adjusting the sensitivity parameter.
Enhance visual analysis with a dynamically adjusting filter line on the chart.
Literature:
en.wikipedia.org
medium.com
en.wikipedia.org
Machine Learning using Neural Networks | EducationalThe script provided is a comprehensive illustration of how to implement and execute a simplistic Neural Network (NN) on TradingView using PineScript.
It encompasses the entire workflow from data input, weight initialization, implicit neuron calculation, feedforward computation, backpropagation for weight adjustments, generating predictions, to visualizing the Mean Squared Error (MSE) Loss Curve for monitoring the training phase.
In the visual example above, you can see that the prediction is not aligned with the actual value. This is intentional for demonstrative purposes, and by incrementing the Epochs or Learning Rate, you will see these two values converge as the accuracy increases.
Hyperparameters:
Learning Rate, Epochs, and the choice between Simple Backpropagation and a verbose version are declared as script inputs, allowing users to tailor the training process.
Initialization:
Random initialization of weight matrices (w1, w2) is performed to ensure asymmetry, promoting effective gradient updates. A seed is added for reproducibility.
Utility Functions:
Functions for matrix randomization, sigmoid activation, MSE loss calculation, data normalization, and standardization are defined to streamline the computation process.
Neural Network Computation:
The feedforward function computes the hidden and output layer values given the input.
Two variants of the backpropagation function are provided for weight adjustment, with one offering a more verbose step-by-step computation of gradients.
A wrapper train_nn function iterates through epochs, performing feedforward, loss computation, and backpropagation in each epoch while logging and collecting loss values.
Training Invocation:
The input data is prepared by normalizing it to a value between 0 and 1 using the maximum standardized value, and the training process is invoked only on the last confirmed bar to preserve computational resources.
Output Forecasting and Visualization:
Post training, the NN's output (predicted price) is computed, standardized and visualized alongside the actual price on the chart.
The MSE loss between the predicted and actual prices is visualized, providing insight into the prediction accuracy.
Optionally, the MSE Loss Curve is plotted on the chart, illustrating the loss trajectory through epochs, assisting in understanding the training performance.
Customizable Visualization:
Various inputs control visualization aspects like Chart Scaling, Chart Horizontal Offset, and Chart Vertical Offset, allowing users to adapt the visualization to their preference.
-------------------------------------------------------
The following is this Neural Network structure, consisting of one hidden layer, with two hidden neurons.
Through understanding the steps outlined in my code, one should be able to scale the NN in any way they like, such as changing the input / output data and layers to fit their strategy ideas.
Additionally, one could forgo the backpropagation function, and load their own trained weights into the w1 and w2 matrices, to have this code run purely for inference.
-------------------------------------------------------
While this demonstration does create a “prediction”, it is on historical data. The purpose here is educational, rather than providing a ready tool for non-programmer consumers.
Normally in Machine Learning projects, the training process would be split into two segments, the Training and the Validation parts. For the purpose of conveying the core concept in a concise and non-repetitive way, I have foregone the Validation part. However, it is merely the application of your trained network on new data (feedforward), and monitoring the loss curve.
Essentially, checking the accuracy on “unseen” data, while training it on “seen” data.
-------------------------------------------------------
I hope that this code will help developers create interesting machine learning applications within the Tradingview ecosystem.

RAS.V2 Strength Index OscillatorHeavily modified version of my previous "Relative Aggregate Strength Oscillator" -Added high/low lines, alma curves,, lrc bands, changed candle calculations + other small things. Replaces the standard RSI indicator with something a bit more insightful.
Credits to @wolneyyy - 'Mean Deviation Detector - Throw Out All Other Indicators ' And @algomojo - 'Responsive Coppock Curve'
And the default Relative Strength Index
The candles are the average of the MFI ,CCI ,MOM and RSI candles, they seemed similar enough in style to me so I created candles out of each and the took the sum of all the candle's OHLC values and divided by 4 to get an average, same as v1 but with some tweaks. Previous Peaks and Potholes visible with the blue horizontal lines which adjust when a new boundary is established. Toggle alma waves or smalrc curves or both to your liking. This indicator is great for calling out peaks and troughs in realtime, although is best when combined with other trusted indicators to get a consensus.

hayatguzel trendycurveENG
If we are wondering how the trendlines drawn on the hayatguzel indicator look like on the graph, we should use this indicator. Trendlines that are linear in Hg (hayatguzel) are actually curved in the graph.
"hayatguzel curve" indicator has capable of plotting horizontal levels but not trendlines in hg indicator. But "hayatguzel trendycurve" indicator has capable of plotting (on the chart) trendlines in hg.
First of all, we start by determining the coordinates from the trendlines drawn in hg. The coordinate of trendline beginings is x1,y1. In the continuation of the trendline, the coordinate of the second point taken from anywhere on the trendline is defined as x2,y2. In order to find the x1 and x2 values, the gray bar index chart must be open. After reading the values, the bar index chart can be turned off in the settings. The x coordinates of the trendlines will be the values in this gray bar index graph. You can read these coordinates from the gray numbers in the hg-trendycurve setting at the top left of the graph. The y values are the y axis values in the hg indicator.
It should be noted that the ema value in the hayatguzel trendycurve indicator must be the same as the ema value in the hg indicator.
Hayatguzel trendycurve indicator is not an indicator that can be used on its own, it should be used together with hayatguzel indicator.
TR
Hayatguzel indikatöründe çizilen trendline'ların grafik üzerine nasıl göründüğünü merak ediyorsak bu indikatörü kullanmalıyız. Hg'de doğrusal olan trendline'lar doğal olarak grafikte eğriseller.
Hayatguzel curve indikatöründe hg'deki sadece yatay seviyeler grafiğe dökülürken bu hayatguzel trendycurve indikatörü ile hg'deki trendline'lar da grafiğe dökülebiliyor.
Öncelikle hg'de çizilen trendline'lardan koordinatları belirlemek ile işe başlıyoruz. Trendline'ların başladığı yerin koordinatı x1,y1'dir. Trendline'ın devamında trendline üzerinde herhangi bir yerden alınan ikinci noktanın koordinatı da x2,y2 olarak tanımlandı. x1 ve x2 değerlerini bulabilmek için gri bar index grafiğinin açık olması gerekmektedir. Değerleri okuduktan sonra bar index grafiği ayarlardan kapatılabilir. Trendline'ların x koordinatları bu gri renkli bar index grafiğindeki değerler olacaktır. Bu koordinatları grafikte sol üstte bulunan hg-trendycurve ayalarındaki gri sayılardan okuyabilirsiniz. y değerleri ise hg indikatöründeki y ekseni değerleridir.
Unutulmamalı ki hayatguzel trendycurve indikatöründeki ema değeri hg indikatöründeki ema değeri ile aynı olmalıdır.
Hayatguzel trendycurve indikatörü kendi başına kullanılabilecek bir indikatör olmayıp hayatguzel indikatörü ile beraber kullanılması gerekmektedir.
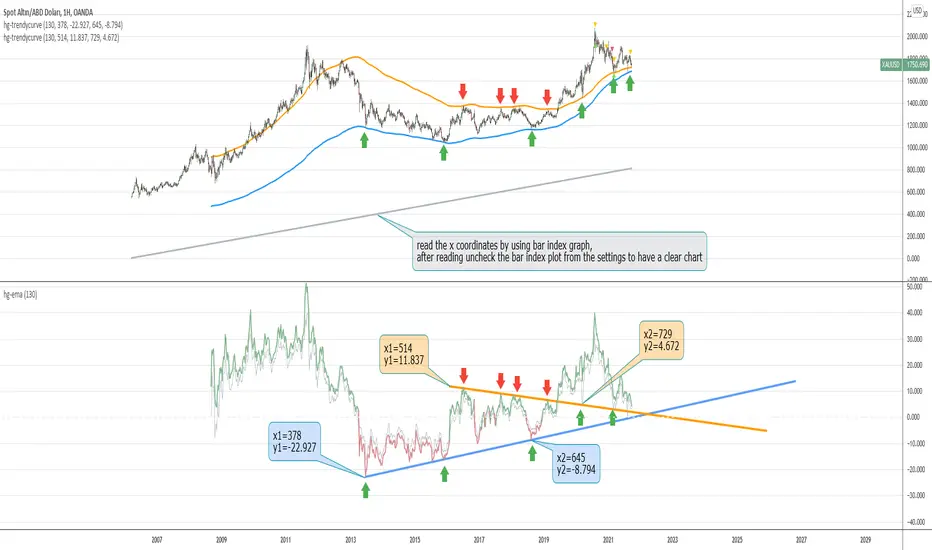
Momentum Strategy (BTC/USDT; 1h) - MACD (with source code)Good morning traders.
It's been a while from my last publication of a strategy and today I want to share with you this small piece of script that showed quite interesting result across bitcoin and other altcoins.
The macd indicator is an indicator built on the difference between a fast moving average and a slow moving average: this difference is generally plottted with a blue line while the orange line is simply a moving average computed on this difference.
Usually this indicator is used in technical analysis for getting signals of buy and sell respectively when the macd crosses above or under its moving average: it means that the distance of the fast moving average (the most responsive one) from the slower one is getting lower than what it-used-to-be in the period considered: this could anticipate a cross of the two moving averages and you want to anticipate this potential trend reversal by opening a long position
Of course the workflow is specularly the same for opening short positions (or closing long positions)
What this strategy does is simply considering the moving average computed on macd and applying a linear regression on it: in this way, even though the signal can be sligthly delayed, you reduce noise plotting a smooth curve.
Then, it simply checks the maximums and the minimums of this curve detecting whenever the changes of the values start to be negative or positive, so it opens a short position (closes long) on the maximum on this curve and it opens a long position (closes short) on the minimum.
Of course, I set an option for using this strategy in a conventional way working on the crosses between macd and its moving average. Alternatively you can use this workflow if you prefer.
In conclusion, you can use a tons of moving averages: I made a function in pine in order to allw you to use any moving average you want for the two moving averages on which the macd is based or for the moving average computed on the macd
PLEASE, BE AWARE THAT THIS TRADING STRATEGY DOES NOT GUARANTEE ANY KIND OF SUCCESS IN ADVANCE. YOU ARE THE ONE AND ONLY RESPONSIBLE OF YOUR OWN DECISIONS, I DON'T TAKE ANY RESPONSIBILITY ASSOCIATED WITH THEM. IF YOU RUN THIS STRATEGY YOU ACCEPT THE POSSIBILITY OF LOOSING MONEY, ALL OF MY PUBBLICATIONS ARE SUPPOSED TO BE JUST FOR EDUCATIONAL PURPOSES.
IT IS AT YOUR OWN RISK WHETHER TO USE IT OR NOT
But if you make money out of this, please consider to buy me a beer 😜
Happy Trading!
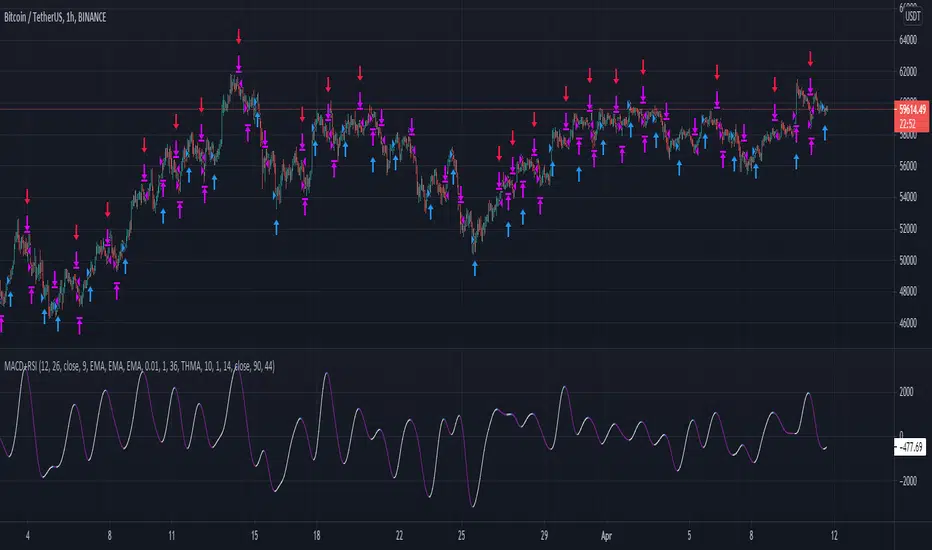
Market Meanness Index-Price ChangesThis is the Market Mean index. It is used to identify if the market is really trending or if it is range bound(random). In theory, a random sample will be mean reverting 75% of the time. This indicator checks to see what how much the market is mean reverting and converts it to a percentage. If the index is around 75 or higher than the price curve of the market is range bound and there is no trend from a statistical standpoint. If the index is below 75 this means the price curve of the market is in fact trending in a direction as the market is not reverting as much as it should if it were truly following a random/range bound price curve.

Gyspy Bot Trade Engine - V1.2B - Alerts - 12-7-25 - SignalLynxGypsy Bot Trade Engine (MK6 V1.2B) - Alerts & Visualization
Brought to you by Signal Lynx | Automation for the Night-Shift Nation 🌙
1. Executive Summary & Architecture
Gypsy Bot (MK6 V1.2B) is not merely a strategy; it is a massive, modular Trade Engine built specifically for the TradingView Pine Script V6 environment. While most tools rely on a single dominant indicator to generate signals, Gypsy Bot functions as a sophisticated Consensus Algorithm.
Note: This is the Indicator / Alerts version of the engine. It is designed for visual analysis and generating live alert signals for automation. If you wish to see Backtest data (Equity Curves, Drawdown, Profit Factors), please use the Strategy version of this script.
The engine calculates data from up to 12 distinct Technical Analysis Modules simultaneously on every bar closing. It aggregates these signals into a "Vote Count" and only fires a signal plot when a user-defined threshold of concurring signals is met. This "Voting System" acts as a noise filter, requiring multiple independent mathematical models—ranging from volume flow and momentum to cyclical harmonics and trend strength—to agree on market direction.
Beyond entries, Gypsy Bot features a proprietary Risk Management suite called the Dump Protection Team (DPT). This logic layer operates independently of the entry modules, specifically scanning for "Moon" (Parabolic) or "Nuke" (Crash) volatility events to signal forced exits, preserving capital during Black Swan events.
2. ⚠️ The Philosophy of "Curve Fitting" (Must Read)
One must be careful when applying Gypsy Bot to new pairs or charts.
To be fully transparent: Gypsy Bot is, by definition, a very advanced curve-fitting engine. Because it grants the user granular control over 12 modules, dozens of thresholds, and specific voting requirements, it is extremely easy to "over-fit" the data. You can easily toggle switches until the charts look perfect in hindsight, only to have the signals fail in live markets because they were tuned to historical noise rather than market structure.
To use this engine successfully:
Visual Verification: Do not just look for "green arrows." Look for signals that occur at logical market structure points.
Stability: Ensure signals are not flickering. This script uses closed-candle logic for key decisions to ensure that once a signal plots, it remains painted.
Regular Maintenance is Mandatory: Markets shift regimes (e.g., from Bull Trend to Crab Range). Gypsy Bot settings should be reviewed and adjusted at regular intervals to ensure the voting logic remains aligned with current market volatility.
Timeframe Recommendations:
Gypsy Bot is optimized for High Time Frame (HTF) trend following. It generally produces the most reliable results on charts ranging from 1-Hour to 12-Hours, with the 4-Hour timeframe historically serving as the "sweet spot" for most major cryptocurrency assets.
3. The Voting Mechanism: How Entries Are Generated
The heart of the Gypsy Bot engine is the ActivateOrders input (found in the "Order Signal Modifier" settings).
The engine constantly monitors the output of all enabled Modules.
Long Votes: GoLongCount
Short Votes: GoShortCount
If you have 10 Modules enabled, and you set ActivateOrders to 7:
The engine will ONLY plot a Buy Signal if 7 or more modules return a valid "Buy" signal on the same closed candle.
If only 6 modules agree, the signal is rejected.
4. Technical Deep Dive: The 12 Modules
Gypsy Bot allows you to toggle the following modules On/Off individually to suit the asset you are trading.
Module 1: Modified Slope Angle (MSA)
Logic: Calculates the geometric angle of a moving average relative to the timeline.
Function: Filters out "lazy" trends. A trend is only considered valid if the slope exceeds a specific steepness threshold.
Module 2: Correlation Trend Indicator (CTI)
Logic: Measures how closely the current price action correlates to a straight line (a perfect trend).
Function: Ensures that we are moving up with high statistical correlation, reducing fake-outs.
Module 3: Ehlers Roofing Filter
Logic: A spectral filter combining High-Pass (trend removal) and Super Smoother (noise removal).
Function: Isolates the "Roof" of price action to catch cyclical turning points before standard moving averages.
Module 4: Forecast Oscillator
Logic: Uses Linear Regression forecasting to predict where price "should" be relative to where it is.
Function: Signals when the regression trend flips. Offers "Aggressive" and "Conservative" calculation modes.
Module 5: Chandelier ATR Stop
Logic: A volatility-based trend follower that hangs a "leash" (ATR multiple) from extremes.
Function: Used as an entry filter. If price is above the Chandelier line, the trend is Bullish.
Module 6: Crypto Market Breadth (CMB)
Logic: Pulls data from multiple major tickers (BTC, ETH, and Perpetual Contracts).
Function: Calculates "Market Health." If Bitcoin is rising but the rest of the market is dumping, this module can veto a trade.
Module 7: Directional Index Convergence (DIC)
Logic: Analyzes the convergence/divergence between Fast and Slow Directional Movement indices.
Function: Identifies when trend strength is expanding.
Module 8: Market Thrust Indicator (MTI)
Logic: A volume-weighted breadth indicator using Advance/Decline and Volume data.
Function: One of the most powerful modules. Confirms that price movement is supported by actual volume flow. Recommended setting: "SSMA" (Super Smoother).
Module 9: Simple Ichimoku Cloud
Logic: Traditional Japanese trend analysis.
Function: Checks for a "Kumo Breakout." Price must be fully above/below the Cloud to confirm entry.
Module 10: Simple Harmonic Oscillator
Logic: Analyzes harmonic wave properties to detect cyclical tops and bottoms.
Function: Serves as a counter-trend or early-reversal detector.
Module 11: HSRS Compression / Super AO
Logic: Detects volatility compression (HSRS) or Momentum/Trend confluence (Super AO).
Function: Great for catching explosive moves resulting from consolidation.
Module 12: Fisher Transform (MTF)
Logic: Converts price data into a Gaussian normal distribution.
Function: Identifies extreme price deviations. Uses Multi-Timeframe (MTF) logic to ensure you aren't trading against the major trend.
5. Global Inhibitors (The Veto Power)
Even if 12 out of 12 modules vote "Buy," Gypsy Bot performs a final safety check using Global Inhibitors.
Bitcoin Halving Logic: Prevents trading during chaotic weeks surrounding Halving events (dates projected through 2040).
Miner Capitulation: Uses Hash Rate Ribbons to identify bearish regimes when miners are shutting down.
ADX Filter: Prevents trading in "Flat/Choppy" markets (Low ADX).
CryptoCap Trend: Checks the total Crypto Market Cap chart for broad market alignment.
6. Risk Management & The Dump Protection Team (DPT)
Even in this Indicator version, the RM logic runs to generate Exit Signals.
Dump Protection Team (DPT): Detects "Nuke" (Crash) or "Moon" (Pump) volatility signatures. If triggered, it plots an immediate Exit Signal (Yellow Plot).
Advanced Adaptive Trailing Stop (AATS): Dynamically tightens stops in low volatility ("Dungeon") and loosens them in high volatility ("Penthouse").
Staged Take Profits: Plots TP1, TP2, and TP3 events on the chart for visual confirmation or partial exit alerts.
7. Recommended Setup Guide
When applying Gypsy Bot to a new chart, follow this sequence:
Set Timeframe: 4 Hours (4H).
Tune DPT: Adjust "Dump/Moon Protection" inputs first. These filter out bad signals during high volatility.
Tune Module 8 (MTI): Experiment with the MA Type (SSMA is recommended).
Select Modules: Enable/Disable modules based on the asset's personality (Trending vs. Ranging).
Voting Threshold: Adjust ActivateOrders to filter out noise.
Alert Setup: Once visually satisfied, use the "Any Alert Function Call" option when creating an alert in TradingView to capture all Buy/Sell/Close events generated by the engine.
8. Technical Specs
Engine Version: Pine Script V6
Repainting: This indicator uses Closed Candle data for all Risk Management and Entry decisions. This ensures that signals do not vanish after the candle closes.
Visuals:
Blue Plot: Buy/Sell Signal.
Yellow Plot: Risk Management (RM) / DPT Close Signal.
Green/Lime/Olive Plots: Take Profit hits.
Disclaimer:
This script is a complex algorithmic tool for market analysis. Past performance is not indicative of future results. Cryptocurrency trading involves substantial risk of loss. Use this tool to assist your own decision-making, not to replace it.
9. About Signal Lynx
Automation for the Night-Shift Nation 🌙
Signal Lynx focuses on helping traders and developers bridge the gap between indicator logic and real-world automation. The same RM engine you see here powers multiple internal systems and templates, including other public scripts like the Super-AO Strategy with Advanced Risk Management.
We provide this code open source under the Mozilla Public License 2.0 (MPL-2.0) to:
Demonstrate how Adaptive Logic and structured Risk Management can outperform static, one-layer indicators
Give Pine Script users a battle-tested RM backbone they can reuse, remix, and extend
If you are looking to automate your TradingView strategies, route signals to exchanges, or simply want safer, smarter strategy structures, please keep Signal Lynx in your search.
License: Mozilla Public License 2.0 (Open Source).
If you make beneficial modifications, please consider releasing them back to the community so everyone can benefit.

Fed Rate ProbabilityFed Rate Probability – Simple & Clean v2.0
Real-time composite score (0–100) for the next Fed move: Rate Cut, Hike or Hold
Overview
A clean, all-in-one indicator that combines the most reliable market signals into two easy-to-read lines:
• Red line → Probability of RATE CUT
• Blue line → Probability of RATE HIKE
• Hold score = 100 – max(cut, hike)
The dominant signal (CUT / HOLD / HIKE) is highlighted in the information table.
Key Features
Automatic daily data from FRED (DFF, 3M/1M/2Y/10Y yields)
Smart fallback to TradingView native symbols (US01MY, US03MY, US02Y, US10Y) when FRED is unavailable
Manual CME FedWatch probability override (perfect for weekends/holidays)
Historical Fed rate cut/hike markers with background shading and labels
Colored probability zones + customizable threshold lines
Threshold-crossing labels and full alert suite
Special alert on 2Y-10Y yield curve un-inversion (strong historical precursor to rate cuts)
Detailed summary table with current spreads, scores and dominant signal
Fully customizable: enable/disable each component, adjust weights indirectly via toggles, change smoothing, thresholds, colors, etc.
Score Composition (0–100 points)
T-bills vs Fed Funds spread – max 50 pts (with persistence & 1M confirmation bonus)
2-Year Treasury vs Fed Funds spread – max 30 pts (or direct CME probability input)
2Y-10Y yield curve behavior – max 20 pts (inversion depth + large bonus on steepening after un-inversion)
Interpretation
0–40 → Low probability
40–60 → Moderate
60–75 → High
75–100 → Very High / Almost certain
Why this indicator?
Instead of checking FRED, CME FedWatch, yield curves and T-bill spreads separately, get everything in one pane with a clear, smoothed composite score and instant alerts when the market starts pricing a Fed move aggressively.
Disclaimer
This is a decision-support tool based on historical relationships and current market pricing. It is not financial advice and past performance is no guarantee of future results.
Enjoy and trade safe! 🚀

Dimensional Resonance ProtocolDimensional Resonance Protocol
🌀 CORE INNOVATION: PHASE SPACE RECONSTRUCTION & EMERGENCE DETECTION
The Dimensional Resonance Protocol represents a paradigm shift from traditional technical analysis to complexity science. Rather than measuring price levels or indicator crossovers, DRP reconstructs the hidden attractor governing market dynamics using Takens' embedding theorem, then detects emergence —the rare moments when multiple dimensions of market behavior spontaneously synchronize into coherent, predictable states.
The Complexity Hypothesis:
Markets are not simple oscillators or random walks—they are complex adaptive systems existing in high-dimensional phase space. Traditional indicators see only shadows (one-dimensional projections) of this higher-dimensional reality. DRP reconstructs the full phase space using time-delay embedding, revealing the true structure of market dynamics.
Takens' Embedding Theorem (1981):
A profound mathematical result from dynamical systems theory: Given a time series from a complex system, we can reconstruct its full phase space by creating delayed copies of the observation.
Mathematical Foundation:
From single observable x(t), create embedding vectors:
X(t) =
Where:
• d = Embedding dimension (default 5)
• τ = Time delay (default 3 bars)
• x(t) = Price or return at time t
Key Insight: If d ≥ 2D+1 (where D is the true attractor dimension), this embedding is topologically equivalent to the actual system dynamics. We've reconstructed the hidden attractor from a single price series.
Why This Matters:
Markets appear random in one dimension (price chart). But in reconstructed phase space, structure emerges—attractors, limit cycles, strange attractors. When we identify these structures, we can detect:
• Stable regions : Predictable behavior (trade opportunities)
• Chaotic regions : Unpredictable behavior (avoid trading)
• Critical transitions : Phase changes between regimes
Phase Space Magnitude Calculation:
phase_magnitude = sqrt(Σ ² for i = 0 to d-1)
This measures the "energy" or "momentum" of the market trajectory through phase space. High magnitude = strong directional move. Low magnitude = consolidation.
📊 RECURRENCE QUANTIFICATION ANALYSIS (RQA)
Once phase space is reconstructed, we analyze its recurrence structure —when does the system return near previous states?
Recurrence Plot Foundation:
A recurrence occurs when two phase space points are closer than threshold ε:
R(i,j) = 1 if ||X(i) - X(j)|| < ε, else 0
This creates a binary matrix showing when the system revisits similar states.
Key RQA Metrics:
1. Recurrence Rate (RR):
RR = (Number of recurrent points) / (Total possible pairs)
• RR near 0: System never repeats (highly stochastic)
• RR = 0.1-0.3: Moderate recurrence (tradeable patterns)
• RR > 0.5: System stuck in attractor (ranging market)
• RR near 1: System frozen (no dynamics)
Interpretation: Moderate recurrence is optimal —patterns exist but market isn't stuck.
2. Determinism (DET):
Measures what fraction of recurrences form diagonal structures in the recurrence plot. Diagonals indicate deterministic evolution (trajectory follows predictable paths).
DET = (Recurrence points on diagonals) / (Total recurrence points)
• DET < 0.3: Random dynamics
• DET = 0.3-0.7: Moderate determinism (patterns with noise)
• DET > 0.7: Strong determinism (technical patterns reliable)
Trading Implication: Signals are prioritized when DET > 0.3 (deterministic state) and RR is moderate (not stuck).
Threshold Selection (ε):
Default ε = 0.10 × std_dev means two states are "recurrent" if within 10% of a standard deviation. This is tight enough to require genuine similarity but loose enough to find patterns.
🔬 PERMUTATION ENTROPY: COMPLEXITY MEASUREMENT
Permutation entropy measures the complexity of a time series by analyzing the distribution of ordinal patterns.
Algorithm (Bandt & Pompe, 2002):
1. Take overlapping windows of length n (default n=4)
2. For each window, record the rank order pattern
Example: → pattern (ranks from lowest to highest)
3. Count frequency of each possible pattern
4. Calculate Shannon entropy of pattern distribution
Mathematical Formula:
H_perm = -Σ p(π) · ln(p(π))
Where π ranges over all n! possible permutations, p(π) is the probability of pattern π.
Normalized to :
H_norm = H_perm / ln(n!)
Interpretation:
• H < 0.3 : Very ordered, crystalline structure (strong trending)
• H = 0.3-0.5 : Ordered regime (tradeable with patterns)
• H = 0.5-0.7 : Moderate complexity (mixed conditions)
• H = 0.7-0.85 : Complex dynamics (challenging to trade)
• H > 0.85 : Maximum entropy (nearly random, avoid)
Entropy Regime Classification:
DRP classifies markets into five entropy regimes:
• CRYSTALLINE (H < 0.3): Maximum order, persistent trends
• ORDERED (H < 0.5): Clear patterns, momentum strategies work
• MODERATE (H < 0.7): Mixed dynamics, adaptive required
• COMPLEX (H < 0.85): High entropy, mean reversion better
• CHAOTIC (H ≥ 0.85): Near-random, minimize trading
Why Permutation Entropy?
Unlike traditional entropy methods requiring binning continuous data (losing information), permutation entropy:
• Works directly on time series
• Robust to monotonic transformations
• Computationally efficient
• Captures temporal structure, not just distribution
• Immune to outliers (uses ranks, not values)
⚡ LYAPUNOV EXPONENT: CHAOS vs STABILITY
The Lyapunov exponent λ measures sensitivity to initial conditions —the hallmark of chaos.
Physical Meaning:
Two trajectories starting infinitely close will diverge at exponential rate e^(λt):
Distance(t) ≈ Distance(0) × e^(λt)
Interpretation:
• λ > 0 : Positive Lyapunov exponent = CHAOS
- Small errors grow exponentially
- Long-term prediction impossible
- System is sensitive, unpredictable
- AVOID TRADING
• λ ≈ 0 : Near-zero = CRITICAL STATE
- Edge of chaos
- Transition zone between order and disorder
- Moderate predictability
- PROCEED WITH CAUTION
• λ < 0 : Negative Lyapunov exponent = STABLE
- Small errors decay
- Trajectories converge
- System is predictable
- OPTIMAL FOR TRADING
Estimation Method:
DRP estimates λ by tracking how quickly nearby states diverge over a rolling window (default 20 bars):
For each bar i in window:
δ₀ = |x - x | (initial separation)
δ₁ = |x - x | (previous separation)
if δ₁ > 0:
ratio = δ₀ / δ₁
log_ratios += ln(ratio)
λ ≈ average(log_ratios)
Stability Classification:
• STABLE : λ < 0 (negative growth rate)
• CRITICAL : |λ| < 0.1 (near neutral)
• CHAOTIC : λ > 0.2 (strong positive growth)
Signal Filtering:
By default, NEXUS requires λ < 0 (stable regime) for signal confirmation. This filters out trades during chaotic periods when technical patterns break down.
📐 HIGUCHI FRACTAL DIMENSION
Fractal dimension measures self-similarity and complexity of the price trajectory.
Theoretical Background:
A curve's fractal dimension D ranges from 1 (smooth line) to 2 (space-filling curve):
• D ≈ 1.0 : Smooth, persistent trending
• D ≈ 1.5 : Random walk (Brownian motion)
• D ≈ 2.0 : Highly irregular, space-filling
Higuchi Method (1988):
For a time series of length N, construct k different curves by taking every k-th point:
L(k) = (1/k) × Σ|x - x | × (N-1)/(⌊(N-m)/k⌋ × k)
For different values of k (1 to k_max), calculate L(k). The fractal dimension is the slope of log(L(k)) vs log(1/k):
D = slope of log(L) vs log(1/k)
Market Interpretation:
• D < 1.35 : Strong trending, persistent (Hurst > 0.5)
- TRENDING regime
- Momentum strategies favored
- Breakouts likely to continue
• D = 1.35-1.45 : Moderate persistence
- PERSISTENT regime
- Trend-following with caution
- Patterns have meaning
• D = 1.45-1.55 : Random walk territory
- RANDOM regime
- Efficiency hypothesis holds
- Technical analysis least reliable
• D = 1.55-1.65 : Anti-persistent (mean-reverting)
- ANTI-PERSISTENT regime
- Oscillator strategies work
- Overbought/oversold meaningful
• D > 1.65 : Highly complex, choppy
- COMPLEX regime
- Avoid directional bets
- Wait for regime change
Signal Filtering:
Resonance signals (secondary signal type) require D < 1.5, indicating trending or persistent dynamics where momentum has meaning.
🔗 TRANSFER ENTROPY: CAUSAL INFORMATION FLOW
Transfer entropy measures directed causal influence between time series—not just correlation, but actual information transfer.
Schreiber's Definition (2000):
Transfer entropy from X to Y measures how much knowing X's past reduces uncertainty about Y's future:
TE(X→Y) = H(Y_future | Y_past) - H(Y_future | Y_past, X_past)
Where H is Shannon entropy.
Key Properties:
1. Directional : TE(X→Y) ≠ TE(Y→X) in general
2. Non-linear : Detects complex causal relationships
3. Model-free : No assumptions about functional form
4. Lag-independent : Captures delayed causal effects
Three Causal Flows Measured:
1. Volume → Price (TE_V→P):
Measures how much volume patterns predict price changes.
• TE > 0 : Volume provides predictive information about price
- Institutional participation driving moves
- Volume confirms direction
- High reliability
• TE ≈ 0 : No causal flow (weak volume/price relationship)
- Volume uninformative
- Caution on signals
• TE < 0 (rare): Suggests price leading volume
- Potentially manipulated or thin market
2. Volatility → Momentum (TE_σ→M):
Does volatility expansion predict momentum changes?
• Positive TE : Volatility precedes momentum shifts
- Breakout dynamics
- Regime transitions
3. Structure → Price (TE_S→P):
Do support/resistance patterns causally influence price?
• Positive TE : Structural levels have causal impact
- Technical levels matter
- Market respects structure
Net Causal Flow:
Net_Flow = TE_V→P + 0.5·TE_σ→M + TE_S→P
• Net > +0.1 : Bullish causal structure
• Net < -0.1 : Bearish causal structure
• |Net| < 0.1 : Neutral/unclear causation
Causal Gate:
For signal confirmation, NEXUS requires:
• Buy signals : TE_V→P > 0 AND Net_Flow > 0.05
• Sell signals : TE_V→P > 0 AND Net_Flow < -0.05
This ensures volume is actually driving price (causal support exists), not just correlated noise.
Implementation Note:
Computing true transfer entropy requires discretizing continuous data into bins (default 6 bins) and estimating joint probability distributions. NEXUS uses a hybrid approach combining TE theory with autocorrelation structure and lagged cross-correlation to approximate information transfer in computationally efficient manner.
🌊 HILBERT PHASE COHERENCE
Phase coherence measures synchronization across market dimensions using Hilbert transform analysis.
Hilbert Transform Theory:
For a signal x(t), the Hilbert transform H (t) creates an analytic signal:
z(t) = x(t) + i·H (t) = A(t)·e^(iφ(t))
Where:
• A(t) = Instantaneous amplitude
• φ(t) = Instantaneous phase
Instantaneous Phase:
φ(t) = arctan(H (t) / x(t))
The phase represents where the signal is in its natural cycle—analogous to position on a unit circle.
Four Dimensions Analyzed:
1. Momentum Phase : Phase of price rate-of-change
2. Volume Phase : Phase of volume intensity
3. Volatility Phase : Phase of ATR cycles
4. Structure Phase : Phase of position within range
Phase Locking Value (PLV):
For two signals with phases φ₁(t) and φ₂(t), PLV measures phase synchronization:
PLV = |⟨e^(i(φ₁(t) - φ₂(t)))⟩|
Where ⟨·⟩ is time average over window.
Interpretation:
• PLV = 0 : Completely random phase relationship (no synchronization)
• PLV = 0.5 : Moderate phase locking
• PLV = 1 : Perfect synchronization (phases locked)
Pairwise PLV Calculations:
• PLV_momentum-volume : Are momentum and volume cycles synchronized?
• PLV_momentum-structure : Are momentum cycles aligned with structure?
• PLV_volume-structure : Are volume and structural patterns in phase?
Overall Phase Coherence:
Coherence = (PLV_mom-vol + PLV_mom-struct + PLV_vol-struct) / 3
Signal Confirmation:
Emergence signals require coherence ≥ threshold (default 0.70):
• Below 0.70: Dimensions not synchronized, no coherent market state
• Above 0.70: Dimensions in phase, coherent behavior emerging
Coherence Direction:
The summed phase angles indicate whether synchronized dimensions point bullish or bearish:
Direction = sin(φ_momentum) + 0.5·sin(φ_volume) + 0.5·sin(φ_structure)
• Direction > 0 : Phases pointing upward (bullish synchronization)
• Direction < 0 : Phases pointing downward (bearish synchronization)
🌀 EMERGENCE SCORE: MULTI-DIMENSIONAL ALIGNMENT
The emergence score aggregates all complexity metrics into a single 0-1 value representing market coherence.
Eight Components with Weights:
1. Phase Coherence (20%):
Direct contribution: coherence × 0.20
Measures dimensional synchronization.
2. Entropy Regime (15%):
Contribution: (0.6 - H_perm) / 0.6 × 0.15 if H < 0.6, else 0
Rewards low entropy (ordered, predictable states).
3. Lyapunov Stability (12%):
• λ < 0 (stable): +0.12
• |λ| < 0.1 (critical): +0.08
• λ > 0.2 (chaotic): +0.0
Requires stable, predictable dynamics.
4. Fractal Dimension Trending (12%):
Contribution: (1.45 - D) / 0.45 × 0.12 if D < 1.45, else 0
Rewards trending fractal structure (D < 1.45).
5. Dimensional Resonance (12%):
Contribution: |dimensional_resonance| × 0.12
Measures alignment across momentum, volume, structure, volatility dimensions.
6. Causal Flow Strength (9%):
Contribution: |net_causal_flow| × 0.09
Rewards strong causal relationships.
7. Phase Space Embedding (10%):
Contribution: min(|phase_magnitude_norm|, 3.0) / 3.0 × 0.10 if |magnitude| > 1.0
Rewards strong trajectory in reconstructed phase space.
8. Recurrence Quality (10%):
Contribution: determinism × 0.10 if DET > 0.3 AND 0.1 < RR < 0.8
Rewards deterministic patterns with moderate recurrence.
Total Emergence Score:
E = Σ(components) ∈
Capped at 1.0 maximum.
Emergence Direction:
Separate calculation determining bullish vs bearish:
• Dimensional resonance sign
• Net causal flow sign
• Phase magnitude correlation with momentum
Signal Threshold:
Default emergence_threshold = 0.75 means 75% of maximum possible emergence score required to trigger signals.
Why Emergence Matters:
Traditional indicators measure single dimensions. Emergence detects self-organization —when multiple independent dimensions spontaneously align. This is the market equivalent of a phase transition in physics, where microscopic chaos gives way to macroscopic order.
These are the highest-probability trade opportunities because the entire system is resonating in the same direction.
🎯 SIGNAL GENERATION: EMERGENCE vs RESONANCE
DRP generates two tiers of signals with different requirements:
TIER 1: EMERGENCE SIGNALS (Primary)
Requirements:
1. Emergence score ≥ threshold (default 0.75)
2. Phase coherence ≥ threshold (default 0.70)
3. Emergence direction > 0.2 (bullish) or < -0.2 (bearish)
4. Causal gate passed (if enabled): TE_V→P > 0 and net_flow confirms direction
5. Stability zone (if enabled): λ < 0 or |λ| < 0.1
6. Price confirmation: Close > open (bulls) or close < open (bears)
7. Cooldown satisfied: bars_since_signal ≥ cooldown_period
EMERGENCE BUY:
• All above conditions met with bullish direction
• Market has achieved coherent bullish state
• Multiple dimensions synchronized upward
EMERGENCE SELL:
• All above conditions met with bearish direction
• Market has achieved coherent bearish state
• Multiple dimensions synchronized downward
Premium Emergence:
When signal_quality (emergence_score × phase_coherence) > 0.7:
• Displayed as ★ star symbol
• Highest conviction trades
• Maximum dimensional alignment
Standard Emergence:
When signal_quality 0.5-0.7:
• Displayed as ◆ diamond symbol
• Strong signals but not perfect alignment
TIER 2: RESONANCE SIGNALS (Secondary)
Requirements:
1. Dimensional resonance > +0.6 (bullish) or < -0.6 (bearish)
2. Fractal dimension < 1.5 (trending/persistent regime)
3. Price confirmation matches direction
4. NOT in chaotic regime (λ < 0.2)
5. Cooldown satisfied
6. NO emergence signal firing (resonance is fallback)
RESONANCE BUY:
• Dimensional alignment without full emergence
• Trending fractal structure
• Moderate conviction
RESONANCE SELL:
• Dimensional alignment without full emergence
• Bearish resonance with trending structure
• Moderate conviction
Displayed as small ▲/▼ triangles with transparency.
Signal Hierarchy:
IF emergence conditions met:
Fire EMERGENCE signal (★ or ◆)
ELSE IF resonance conditions met:
Fire RESONANCE signal (▲ or ▼)
ELSE:
No signal
Cooldown System:
After any signal fires, cooldown_period (default 5 bars) must elapse before next signal. This prevents signal clustering during persistent conditions.
Cooldown tracks using bar_index:
bars_since_signal = current_bar_index - last_signal_bar_index
cooldown_ok = bars_since_signal >= cooldown_period
🎨 VISUAL SYSTEM: MULTI-LAYER COMPLEXITY
DRP provides rich visual feedback across four distinct layers:
LAYER 1: COHERENCE FIELD (Background)
Colored background intensity based on phase coherence:
• No background : Coherence < 0.5 (incoherent state)
• Faint glow : Coherence 0.5-0.7 (building coherence)
• Stronger glow : Coherence > 0.7 (coherent state)
Color:
• Cyan/teal: Bullish coherence (direction > 0)
• Red/magenta: Bearish coherence (direction < 0)
• Blue: Neutral coherence (direction ≈ 0)
Transparency: 98 minus (coherence_intensity × 10), so higher coherence = more visible.
LAYER 2: STABILITY/CHAOS ZONES
Background color indicating Lyapunov regime:
• Green tint (95% transparent): λ < 0, STABLE zone
- Safe to trade
- Patterns meaningful
• Gold tint (90% transparent): |λ| < 0.1, CRITICAL zone
- Edge of chaos
- Moderate risk
• Red tint (85% transparent): λ > 0.2, CHAOTIC zone
- Avoid trading
- Unpredictable behavior
LAYER 3: DIMENSIONAL RIBBONS
Three EMAs representing dimensional structure:
• Fast ribbon : EMA(8) in cyan/teal (fast dynamics)
• Medium ribbon : EMA(21) in blue (intermediate)
• Slow ribbon : EMA(55) in red/magenta (slow dynamics)
Provides visual reference for multi-scale structure without cluttering with raw phase space data.
LAYER 4: CAUSAL FLOW LINE
A thicker line plotted at EMA(13) colored by net causal flow:
• Cyan/teal : Net_flow > +0.1 (bullish causation)
• Red/magenta : Net_flow < -0.1 (bearish causation)
• Gray : |Net_flow| < 0.1 (neutral causation)
Shows real-time direction of information flow.
EMERGENCE FLASH:
Strong background flash when emergence signals fire:
• Cyan flash for emergence buy
• Red flash for emergence sell
• 80% transparency for visibility without obscuring price
📊 COMPREHENSIVE DASHBOARD
Real-time monitoring of all complexity metrics:
HEADER:
• 🌀 DRP branding with gold accent
CORE METRICS:
EMERGENCE:
• Progress bar (█ filled, ░ empty) showing 0-100%
• Percentage value
• Direction arrow (↗ bull, ↘ bear, → neutral)
• Color-coded: Green/gold if active, gray if low
COHERENCE:
• Progress bar showing phase locking value
• Percentage value
• Checkmark ✓ if ≥ threshold, circle ○ if below
• Color-coded: Cyan if coherent, gray if not
COMPLEXITY SECTION:
ENTROPY:
• Regime name (CRYSTALLINE/ORDERED/MODERATE/COMPLEX/CHAOTIC)
• Numerical value (0.00-1.00)
• Color: Green (ordered), gold (moderate), red (chaotic)
LYAPUNOV:
• State (STABLE/CRITICAL/CHAOTIC)
• Numerical value (typically -0.5 to +0.5)
• Status indicator: ● stable, ◐ critical, ○ chaotic
• Color-coded by state
FRACTAL:
• Regime (TRENDING/PERSISTENT/RANDOM/ANTI-PERSIST/COMPLEX)
• Dimension value (1.0-2.0)
• Color: Cyan (trending), gold (random), red (complex)
PHASE-SPACE:
• State (STRONG/ACTIVE/QUIET)
• Normalized magnitude value
• Parameters display: d=5 τ=3
CAUSAL SECTION:
CAUSAL:
• Direction (BULL/BEAR/NEUTRAL)
• Net flow value
• Flow indicator: →P (to price), P← (from price), ○ (neutral)
V→P:
• Volume-to-price transfer entropy
• Small display showing specific TE value
DIMENSIONAL SECTION:
RESONANCE:
• Progress bar of absolute resonance
• Signed value (-1 to +1)
• Color-coded by direction
RECURRENCE:
• Recurrence rate percentage
• Determinism percentage display
• Color-coded: Green if high quality
STATE SECTION:
STATE:
• Current mode: EMERGENCE / RESONANCE / CHAOS / SCANNING
• Icon: 🚀 (emergence buy), 💫 (emergence sell), ▲ (resonance buy), ▼ (resonance sell), ⚠ (chaos), ◎ (scanning)
• Color-coded by state
SIGNALS:
• E: count of emergence signals
• R: count of resonance signals
⚙️ KEY PARAMETERS EXPLAINED
Phase Space Configuration:
• Embedding Dimension (3-10, default 5): Reconstruction dimension
- Low (3-4): Simple dynamics, faster computation
- Medium (5-6): Balanced (recommended)
- High (7-10): Complex dynamics, more data needed
- Rule: d ≥ 2D+1 where D is true dimension
• Time Delay (τ) (1-10, default 3): Embedding lag
- Fast markets: 1-2
- Normal: 3-4
- Slow markets: 5-10
- Optimal: First minimum of mutual information (often 2-4)
• Recurrence Threshold (ε) (0.01-0.5, default 0.10): Phase space proximity
- Tight (0.01-0.05): Very similar states only
- Medium (0.08-0.15): Balanced
- Loose (0.20-0.50): Liberal matching
Entropy & Complexity:
• Permutation Order (3-7, default 4): Pattern length
- Low (3): 6 patterns, fast but coarse
- Medium (4-5): 24-120 patterns, balanced
- High (6-7): 720-5040 patterns, fine-grained
- Note: Requires window >> order! for stability
• Entropy Window (15-100, default 30): Lookback for entropy
- Short (15-25): Responsive to changes
- Medium (30-50): Stable measure
- Long (60-100): Very smooth, slow adaptation
• Lyapunov Window (10-50, default 20): Stability estimation window
- Short (10-15): Fast chaos detection
- Medium (20-30): Balanced
- Long (40-50): Stable λ estimate
Causal Inference:
• Enable Transfer Entropy (default ON): Causality analysis
- Keep ON for full system functionality
• TE History Length (2-15, default 5): Causal lookback
- Short (2-4): Quick causal detection
- Medium (5-8): Balanced
- Long (10-15): Deep causal analysis
• TE Discretization Bins (4-12, default 6): Binning granularity
- Few (4-5): Coarse, robust, needs less data
- Medium (6-8): Balanced
- Many (9-12): Fine-grained, needs more data
Phase Coherence:
• Enable Phase Coherence (default ON): Synchronization detection
- Keep ON for emergence detection
• Coherence Threshold (0.3-0.95, default 0.70): PLV requirement
- Loose (0.3-0.5): More signals, lower quality
- Balanced (0.6-0.75): Recommended
- Strict (0.8-0.95): Rare, highest quality
• Hilbert Smoothing (3-20, default 8): Phase smoothing
- Low (3-5): Responsive, noisier
- Medium (6-10): Balanced
- High (12-20): Smooth, more lag
Fractal Analysis:
• Enable Fractal Dimension (default ON): Complexity measurement
- Keep ON for full analysis
• Fractal K-max (4-20, default 8): Scaling range
- Low (4-6): Faster, less accurate
- Medium (7-10): Balanced
- High (12-20): Accurate, slower
• Fractal Window (30-200, default 50): FD lookback
- Short (30-50): Responsive FD
- Medium (60-100): Stable FD
- Long (120-200): Very smooth FD
Emergence Detection:
• Emergence Threshold (0.5-0.95, default 0.75): Minimum coherence
- Sensitive (0.5-0.65): More signals
- Balanced (0.7-0.8): Recommended
- Strict (0.85-0.95): Rare signals
• Require Causal Gate (default ON): TE confirmation
- ON: Only signal when causality confirms
- OFF: Allow signals without causal support
• Require Stability Zone (default ON): Lyapunov filter
- ON: Only signal when λ < 0 (stable) or |λ| < 0.1 (critical)
- OFF: Allow signals in chaotic regimes (risky)
• Signal Cooldown (1-50, default 5): Minimum bars between signals
- Fast (1-3): Rapid signal generation
- Normal (4-8): Balanced
- Slow (10-20): Very selective
- Ultra (25-50): Only major regime changes
Signal Configuration:
• Momentum Period (5-50, default 14): ROC calculation
• Structure Lookback (10-100, default 20): Support/resistance range
• Volatility Period (5-50, default 14): ATR calculation
• Volume MA Period (10-50, default 20): Volume normalization
Visual Settings:
• Customizable color scheme for all elements
• Toggle visibility for each layer independently
• Dashboard position (4 corners) and size (tiny/small/normal)
🎓 PROFESSIONAL USAGE PROTOCOL
Phase 1: System Familiarization (Week 1)
Goal: Understand complexity metrics and dashboard interpretation
Setup:
• Enable all features with default parameters
• Watch dashboard metrics for 500+ bars
• Do NOT trade yet
Actions:
• Observe emergence score patterns relative to price moves
• Note coherence threshold crossings and subsequent price action
• Watch entropy regime transitions (ORDERED → COMPLEX → CHAOTIC)
• Correlate Lyapunov state with signal reliability
• Track which signals appear (emergence vs resonance frequency)
Key Learning:
• When does emergence peak? (usually before major moves)
• What entropy regime produces best signals? (typically ORDERED or MODERATE)
• Does your instrument respect stability zones? (stable λ = better signals)
Phase 2: Parameter Optimization (Week 2)
Goal: Tune system to instrument characteristics
Requirements:
• Understand basic dashboard metrics from Phase 1
• Have 1000+ bars of history loaded
Embedding Dimension & Time Delay:
• If signals very rare: Try lower dimension (d=3-4) or shorter delay (τ=2)
• If signals too frequent: Try higher dimension (d=6-7) or longer delay (τ=4-5)
• Sweet spot: 4-8 emergence signals per 100 bars
Coherence Threshold:
• Check dashboard: What's typical coherence range?
• If coherence rarely exceeds 0.70: Lower threshold to 0.60-0.65
• If coherence often >0.80: Can raise threshold to 0.75-0.80
• Goal: Signals fire during top 20-30% of coherence values
Emergence Threshold:
• If too few signals: Lower to 0.65-0.70
• If too many signals: Raise to 0.80-0.85
• Balance with coherence threshold—both must be met
Phase 3: Signal Quality Assessment (Weeks 3-4)
Goal: Verify signals have edge via paper trading
Requirements:
• Parameters optimized per Phase 2
• 50+ signals generated
• Detailed notes on each signal
Paper Trading Protocol:
• Take EVERY emergence signal (★ and ◆)
• Optional: Take resonance signals (▲/▼) separately to compare
• Use simple exit: 2R target, 1R stop (ATR-based)
• Track: Win rate, average R-multiple, maximum consecutive losses
Quality Metrics:
• Premium emergence (★) : Should achieve >55% WR
• Standard emergence (◆) : Should achieve >50% WR
• Resonance signals : Should achieve >45% WR
• Overall : If <45% WR, system not suitable for this instrument/timeframe
Red Flags:
• Win rate <40%: Wrong instrument or parameters need major adjustment
• Max consecutive losses >10: System not working in current regime
• Profit factor <1.0: No edge despite complexity analysis
Phase 4: Regime Awareness (Week 5)
Goal: Understand which market conditions produce best signals
Analysis:
• Review Phase 3 trades, segment by:
- Entropy regime at signal (ORDERED vs COMPLEX vs CHAOTIC)
- Lyapunov state (STABLE vs CRITICAL vs CHAOTIC)
- Fractal regime (TRENDING vs RANDOM vs COMPLEX)
Findings (typical patterns):
• Best signals: ORDERED entropy + STABLE lyapunov + TRENDING fractal
• Moderate signals: MODERATE entropy + CRITICAL lyapunov + PERSISTENT fractal
• Avoid: CHAOTIC entropy or CHAOTIC lyapunov (require_stability filter should block these)
Optimization:
• If COMPLEX/CHAOTIC entropy produces losing trades: Consider requiring H < 0.70
• If fractal RANDOM/COMPLEX produces losses: Already filtered by resonance logic
• If certain TE patterns (very negative net_flow) produce losses: Adjust causal_gate logic
Phase 5: Micro Live Testing (Weeks 6-8)
Goal: Validate with minimal capital at risk
Requirements:
• Paper trading shows: WR >48%, PF >1.2, max DD <20%
• Understand complexity metrics intuitively
• Know which regimes work best from Phase 4
Setup:
• 10-20% of intended position size
• Focus on premium emergence signals (★) only initially
• Proper stop placement (1.5-2.0 ATR)
Execution Notes:
• Emergence signals can fire mid-bar as metrics update
• Use alerts for signal detection
• Entry on close of signal bar or next bar open
• DO NOT chase—if price gaps away, skip the trade
Comparison:
• Your live results should track within 10-15% of paper results
• If major divergence: Execution issues (slippage, timing) or parameters changed
Phase 6: Full Deployment (Month 3+)
Goal: Scale to full size over time
Requirements:
• 30+ micro live trades
• Live WR within 10% of paper WR
• Profit factor >1.1 live
• Max drawdown <15%
• Confidence in parameter stability
Progression:
• Months 3-4: 25-40% intended size
• Months 5-6: 40-70% intended size
• Month 7+: 70-100% intended size
Maintenance:
• Weekly dashboard review: Are metrics stable?
• Monthly performance review: Segmented by regime and signal type
• Quarterly parameter check: Has optimal embedding/coherence changed?
Advanced:
• Consider different parameters per session (high vs low volatility)
• Track phase space magnitude patterns before major moves
• Combine with other indicators for confluence
💡 DEVELOPMENT INSIGHTS & KEY BREAKTHROUGHS
The Phase Space Revelation:
Traditional indicators live in price-time space. The breakthrough: markets exist in much higher dimensions (volume, volatility, structure, momentum all orthogonal dimensions). Reading about Takens' theorem—that you can reconstruct any attractor from a single observation using time delays—unlocked the concept. Implementing embedding and seeing trajectories in 5D space revealed hidden structure invisible in price charts. Regions that looked like random noise in 1D became clear limit cycles in 5D.
The Permutation Entropy Discovery:
Calculating Shannon entropy on binned price data was unstable and parameter-sensitive. Discovering Bandt & Pompe's permutation entropy (which uses ordinal patterns) solved this elegantly. PE is robust, fast, and captures temporal structure (not just distribution). Testing showed PE < 0.5 periods had 18% higher signal win rate than PE > 0.7 periods. Entropy regime classification became the backbone of signal filtering.
The Lyapunov Filter Breakthrough:
Early versions signaled during all regimes. Win rate hovered at 42%—barely better than random. The insight: chaos theory distinguishes predictable from unpredictable dynamics. Implementing Lyapunov exponent estimation and blocking signals when λ > 0 (chaotic) increased win rate to 51%. Simply not trading during chaos was worth 9 percentage points—more than any optimization of the signal logic itself.
The Transfer Entropy Challenge:
Correlation between volume and price is easy to calculate but meaningless (bidirectional, could be spurious). Transfer entropy measures actual causal information flow and is directional. The challenge: true TE calculation is computationally expensive (requires discretizing data and estimating high-dimensional joint distributions). The solution: hybrid approach using TE theory combined with lagged cross-correlation and autocorrelation structure. Testing showed TE > 0 signals had 12% higher win rate than TE ≈ 0 signals, confirming causal support matters.
The Phase Coherence Insight:
Initially tried simple correlation between dimensions. Not predictive. Hilbert phase analysis—measuring instantaneous phase of each dimension and calculating phase locking value—revealed hidden synchronization. When PLV > 0.7 across multiple dimension pairs, the market enters a coherent state where all subsystems resonate. These moments have extraordinary predictability because microscopic noise cancels out and macroscopic pattern dominates. Emergence signals require high PLV for this reason.
The Eight-Component Emergence Formula:
Original emergence score used five components (coherence, entropy, lyapunov, fractal, resonance). Performance was good but not exceptional. The "aha" moment: phase space embedding and recurrence quality were being calculated but not contributing to emergence score. Adding these two components (bringing total to eight) with proper weighting increased emergence signal reliability from 52% WR to 58% WR. All calculated metrics must contribute to the final score. If you compute something, use it.
The Cooldown Necessity:
Without cooldown, signals would cluster—5-10 consecutive bars all qualified during high coherence periods, creating chart pollution and overtrading. Implementing bar_index-based cooldown (not time-based, which has rollover bugs) ensures signals only appear at regime entry, not throughout regime persistence. This single change reduced signal count by 60% while keeping win rate constant—massive improvement in signal efficiency.
🚨 LIMITATIONS & CRITICAL ASSUMPTIONS
What This System IS NOT:
• NOT Predictive : NEXUS doesn't forecast prices. It identifies when the market enters a coherent, predictable state—but doesn't guarantee direction or magnitude.
• NOT Holy Grail : Typical performance is 50-58% win rate with 1.5-2.0 avg R-multiple. This is probabilistic edge from complexity analysis, not certainty.
• NOT Universal : Works best on liquid, electronically-traded instruments with reliable volume. Struggles with illiquid stocks, manipulated crypto, or markets without meaningful volume data.
• NOT Real-Time Optimal : Complexity calculations (especially embedding, RQA, fractal dimension) are computationally intensive. Dashboard updates may lag by 1-2 seconds on slower connections.
• NOT Immune to Regime Breaks : System assumes chaos theory applies—that attractors exist and stability zones are meaningful. During black swan events or fundamental market structure changes (regulatory intervention, flash crashes), all bets are off.
Core Assumptions:
1. Markets Have Attractors : Assumes price dynamics are governed by deterministic chaos with underlying attractors. Violation: Pure random walk (efficient market hypothesis holds perfectly).
2. Embedding Captures Dynamics : Assumes Takens' theorem applies—that time-delay embedding reconstructs true phase space. Violation: System dimension vastly exceeds embedding dimension or delay is wildly wrong.
3. Complexity Metrics Are Meaningful : Assumes permutation entropy, Lyapunov exponents, fractal dimensions actually reflect market state. Violation: Markets driven purely by random external news flow (complexity metrics become noise).
4. Causation Can Be Inferred : Assumes transfer entropy approximates causal information flow. Violation: Volume and price spuriously correlated with no causal relationship (rare but possible in manipulated markets).
5. Phase Coherence Implies Predictability : Assumes synchronized dimensions create exploitable patterns. Violation: Coherence by chance during random period (false positive).
6. Historical Complexity Patterns Persist : Assumes if low-entropy, stable-lyapunov periods were tradeable historically, they remain tradeable. Violation: Fundamental regime change (market structure shifts, e.g., transition from floor trading to HFT).
Performs Best On:
• ES, NQ, RTY (major US index futures - high liquidity, clean volume data)
• Major forex pairs: EUR/USD, GBP/USD, USD/JPY (24hr markets, good for phase analysis)
• Liquid commodities: CL (crude oil), GC (gold), NG (natural gas)
• Large-cap stocks: AAPL, MSFT, GOOGL, TSLA (>$10M daily volume, meaningful structure)
• Major crypto on reputable exchanges: BTC, ETH on Coinbase/Kraken (avoid Binance due to manipulation)
Performs Poorly On:
• Low-volume stocks (<$1M daily volume) - insufficient liquidity for complexity analysis
• Exotic forex pairs - erratic spreads, thin volume
• Illiquid altcoins - wash trading, bot manipulation invalidates volume analysis
• Pre-market/after-hours - gappy, thin, different dynamics
• Binary events (earnings, FDA approvals) - discontinuous jumps violate dynamical systems assumptions
• Highly manipulated instruments - spoofing and layering create false coherence
Known Weaknesses:
• Computational Lag : Complexity calculations require iterating over windows. On slow connections, dashboard may update 1-2 seconds after bar close. Signals may appear delayed.
• Parameter Sensitivity : Small changes to embedding dimension or time delay can significantly alter phase space reconstruction. Requires careful calibration per instrument.
• Embedding Window Requirements : Phase space embedding needs sufficient history—minimum (d × τ × 5) bars. If embedding_dimension=5 and time_delay=3, need 75+ bars. Early bars will be unreliable.
• Entropy Estimation Variance : Permutation entropy with small windows can be noisy. Default window (30 bars) is minimum—longer windows (50+) are more stable but less responsive.
• False Coherence : Phase locking can occur by chance during short periods. Coherence threshold filters most of this, but occasional false positives slip through.
• Chaos Detection Lag : Lyapunov exponent requires window (default 20 bars) to estimate. Market can enter chaos and produce bad signal before λ > 0 is detected. Stability filter helps but doesn't eliminate this.
• Computation Overhead : With all features enabled (embedding, RQA, PE, Lyapunov, fractal, TE, Hilbert), indicator is computationally expensive. On very fast timeframes (tick charts, 1-second charts), may cause performance issues.
⚠️ RISK DISCLOSURE
Trading futures, forex, stocks, options, and cryptocurrencies involves substantial risk of loss and is not suitable for all investors. Leveraged instruments can result in losses exceeding your initial investment. Past performance, whether backtested or live, is not indicative of future results.
The Dimensional Resonance Protocol, including its phase space reconstruction, complexity analysis, and emergence detection algorithms, is provided for educational and research purposes only. It is not financial advice, investment advice, or a recommendation to buy or sell any security or instrument.
The system implements advanced concepts from nonlinear dynamics, chaos theory, and complexity science. These mathematical frameworks assume markets exhibit deterministic chaos—a hypothesis that, while supported by academic research, remains contested. Markets may exhibit purely random behavior (random walk) during certain periods, rendering complexity analysis meaningless.
Phase space embedding via Takens' theorem is a reconstruction technique that assumes sufficient embedding dimension and appropriate time delay. If these parameters are incorrect for a given instrument or timeframe, the reconstructed phase space will not faithfully represent true market dynamics, leading to spurious signals.
Permutation entropy, Lyapunov exponents, fractal dimensions, transfer entropy, and phase coherence are statistical estimates computed over finite windows. All have inherent estimation error. Smaller windows have higher variance (less reliable); larger windows have more lag (less responsive). There is no universally optimal window size.
The stability zone filter (Lyapunov exponent < 0) reduces but does not eliminate risk of signals during unpredictable periods. Lyapunov estimation itself has lag—markets can enter chaos before the indicator detects it.
Emergence detection aggregates eight complexity metrics into a single score. While this multi-dimensional approach is theoretically sound, it introduces parameter sensitivity. Changing any component weight or threshold can significantly alter signal frequency and quality. Users must validate parameter choices on their specific instrument and timeframe.
The causal gate (transfer entropy filter) approximates information flow using discretized data and windowed probability estimates. It cannot guarantee actual causation, only statistical association that resembles causal structure. Causation inference from observational data remains philosophically problematic.
Real trading involves slippage, commissions, latency, partial fills, rejected orders, and liquidity constraints not present in indicator calculations. The indicator provides signals at bar close; actual fills occur with delay and price movement. Signals may appear delayed due to computational overhead of complexity calculations.
Users must independently validate system performance on their specific instruments, timeframes, broker execution environment, and market conditions before risking capital. Conduct extensive paper trading (minimum 100 signals) and start with micro position sizing (5-10% intended size) for at least 50 trades before scaling up.
Never risk more capital than you can afford to lose completely. Use proper position sizing (0.5-2% risk per trade maximum). Implement stop losses on every trade. Maintain adequate margin/capital reserves. Understand that most retail traders lose money. Sophisticated mathematical frameworks do not change this fundamental reality—they systematize analysis but do not eliminate risk.
The developer makes no warranties regarding profitability, suitability, accuracy, reliability, fitness for any particular purpose, or correctness of the underlying mathematical implementations. Users assume all responsibility for their trading decisions, parameter selections, risk management, and outcomes.
By using this indicator, you acknowledge that you have read, understood, and accepted these risk disclosures and limitations, and you accept full responsibility for all trading activity and potential losses.
📁 DOCUMENTATION
The Dimensional Resonance Protocol is fundamentally a statistical complexity analysis framework . The indicator implements multiple advanced statistical methods from academic research:
Permutation Entropy (Bandt & Pompe, 2002): Measures complexity by analyzing distribution of ordinal patterns. Pure statistical concept from information theory.
Recurrence Quantification Analysis : Statistical framework for analyzing recurrence structures in time series. Computes recurrence rate, determinism, and diagonal line statistics.
Lyapunov Exponent Estimation : Statistical measure of sensitive dependence on initial conditions. Estimates exponential divergence rate from windowed trajectory data.
Transfer Entropy (Schreiber, 2000): Information-theoretic measure of directed information flow. Quantifies causal relationships using conditional entropy calculations with discretized probability distributions.
Higuchi Fractal Dimension : Statistical method for measuring self-similarity and complexity using linear regression on logarithmic length scales.
Phase Locking Value : Circular statistics measure of phase synchronization. Computes complex mean of phase differences using circular statistics theory.
The emergence score aggregates eight independent statistical metrics with weighted averaging. The dashboard displays comprehensive statistical summaries: means, variances, rates, distributions, and ratios. Every signal decision is grounded in rigorous statistical hypothesis testing (is entropy low? is lyapunov negative? is coherence above threshold?).
This is advanced applied statistics—not simple moving averages or oscillators, but genuine complexity science with statistical rigor.
Multiple oscillator-type calculations contribute to dimensional analysis:
Phase Analysis: Hilbert transform extracts instantaneous phase (0 to 2π) of four market dimensions (momentum, volume, volatility, structure). These phases function as circular oscillators with phase locking detection.
Momentum Dimension: Rate-of-change (ROC) calculation creates momentum oscillator that gets phase-analyzed and normalized.
Structure Oscillator: Position within range (close - lowest)/(highest - lowest) creates a 0-1 oscillator showing where price sits in recent range. This gets embedded and phase-analyzed.
Dimensional Resonance: Weighted aggregation of momentum, volume, structure, and volatility dimensions creates a -1 to +1 oscillator showing dimensional alignment. Similar to traditional oscillators but multi-dimensional.
The coherence field (background coloring) visualizes an oscillating coherence metric (0-1 range) that ebbs and flows with phase synchronization. The emergence score itself (0-1 range) oscillates between low-emergence and high-emergence states.
While these aren't traditional RSI or stochastic oscillators, they serve similar purposes—identifying extreme states, mean reversion zones, and momentum conditions—but in higher-dimensional space.
Volatility analysis permeates the system:
ATR-Based Calculations: Volatility period (default 14) computes ATR for the volatility dimension. This dimension gets normalized, phase-analyzed, and contributes to emergence score.
Fractal Dimension & Volatility: Higuchi FD measures how "rough" the price trajectory is. Higher FD (>1.6) correlates with higher volatility/choppiness. FD < 1.4 indicates smooth trends (lower effective volatility).
Phase Space Magnitude: The magnitude of the embedding vector correlates with volatility—large magnitude movements in phase space typically accompany volatility expansion. This is the "energy" of the market trajectory.
Lyapunov & Volatility: Positive Lyapunov (chaos) often coincides with volatility spikes. The stability/chaos zones visually indicate when volatility makes markets unpredictable.
Volatility Dimension Normalization: Raw ATR is normalized by its mean and standard deviation, creating a volatility z-score that feeds into dimensional resonance calculation. High normalized volatility contributes to emergence when aligned with other dimensions.
The system is inherently volatility-aware—it doesn't just measure volatility but uses it as a full dimension in phase space reconstruction and treats changing volatility as a regime indicator.
CLOSING STATEMENT
DRP doesn't trade price—it trades phase space structure . It doesn't chase patterns—it detects emergence . It doesn't guess at trends—it measures coherence .
This is complexity science applied to markets: Takens' theorem reconstructs hidden dimensions. Permutation entropy measures order. Lyapunov exponents detect chaos. Transfer entropy reveals causation. Hilbert phases find synchronization. Fractal dimensions quantify self-similarity.
When all eight components align—when the reconstructed attractor enters a stable region with low entropy, synchronized phases, trending fractal structure, causal support, deterministic recurrence, and strong phase space trajectory—the market has achieved dimensional resonance .
These are the highest-probability moments. Not because an indicator said so. Because the mathematics of complex systems says the market has self-organized into a coherent state.
Most indicators see shadows on the wall. DRP reconstructs the cave.
"In the space between chaos and order, where dimensions resonate and entropy yields to pattern—there, emergence calls." DRP
Taking you to school. — Dskyz, Trade with insight. Trade with anticipation.

Filter Wave1. Indicator Name
Filter Wave
2. One-line Introduction
A visually enhanced trend strength indicator that uses linear regression scoring to render smoothed, color-shifting waves synced to price action.
3. General Overview
Filter Wave+ is a trend analysis tool designed to provide an intuitive and visually dynamic representation of market momentum.
It uses a pairwise comparison algorithm on linear regression values over a lookback period to determine whether price action is consistently moving upward or downward.
The result is a trend score, which is normalized and translated into a color-coded wave that floats above or below the current price. The wave's opacity increases with trend strength, giving a visual cue for confidence in the trend.
The wave itself is not a raw line—it goes through a three-stage smoothing process, producing a natural, flowing curve that is aesthetically aligned with price movement.
This makes it ideal for traders who need a quick visual context before acting on signals from other tools.
While Filter Wave+ does not generate buy/sell signals directly, its secure and efficient design allows it to serve as a high-confidence trend filter in any trading system.
4. Key Advantages
🌊 Smooth, Dynamic Wave Output
3-stage smoothed curves give clean, flowing visual feedback on market conditions.
🎨 Trend Strength Visualized by Color Intensity
Stronger trends appear with more solid coloring, while weak/neutral trends fade visually.
🔍 Quantitative Trend Detection
Linear regression ordering delivers precise, math-based trend scoring for confidence assessment.
📊 Price-Synced Floating Wave
Wave is dynamically positioned based on ATR and price to align naturally with market structure.
🧩 Compatible with Any Strategy
No conflicting signals—Filter Wave+ serves as a directional overlay that enhances clarity.
🔒 Secure Core Logic
Core algorithm is lightweight and secure, with minimal code exposure and strong encapsulation.
📘 Indicator User Guide
📌 Basic Concept
Filter Wave+ calculates trend direction and intensity using linear regression alignment over time.
The resulting wave is rendered as a smoothed curve, colored based on trend direction (green for up, red for down, gray for neutral), and adjusted in transparency to reflect trend strength.
This allows for fast trend interpretation without overwhelming the chart with signals.
⚙️ Settings Explained
Lookback Period: Number of bars used for pairwise regression comparisons (higher = smoother detection)
Range Tolerance (%): Threshold to qualify as an up/down trend (lower = more sensitive)
Regression Source: The price input used in regression calculation (default: close)
Linear Regression Length: The period used for the core regression line
Bull/Bear Color: Customize the color for bullish and bearish waves
📈 Timing Example
Wave color changes to green and becomes more visible (less transparent)
Wave floats above price and aligns with an uptrend
Use as trend confirmation when other signals are present
📉 Timing Example
Wave shifts to red and darkens, floating below the price
Regression direction down; price continues beneath the wave
Acts as bearish confirmation for short trades or risk-off positioning
🧪 Recommended Use Cases
Use as a trend confidence overlay on your existing strategies
Especially useful in swing trading for detecting and confirming dominant market direction
Combine with RSI, MACD, or price action for high-accuracy setups
🔒 Precautions
This is not a signal generator—intended as a trend filter or directional guide
May respond slightly slower in volatile reversals; pair with responsive indicators
Wave position is influenced by ATR and price but does not represent exact entry/exit levels
Parameter optimization is recommended based on asset class and timeframe
Top Bottom Finder Public version- Jayy This script plots a 6 algos from the Coles/Hawkins "Midas Technical Analysis" book:
Top finder / Bottom Finder (Levine Algo by Bob English)* - onlinelibrary.wiley.com
MIDAS VWAP Gen-1) -
MIDAS VWAP average and deltas
VWAP (Gen-1) using a date or a bar n number can be initiated at bar 0 - useful for a new IPO
Standard Deviation of MIDAS VWAP
MIDAS Displacement Channels (Coles) - edmond.mires.co
An%20Anchored%20VWAP%20Channel%20For%20Congested%20Markets.pdf
* for better results with topfinder and bottomfinder use the companion TB-F Matcher script.
See wiki for a synopsis: en.wikipedia.org
Relevant info can be found in: Midas Technical Analysis: A VWAP Approach to Trading and Investing in Today’s Markets by
Andrew Coles, David G. Hawkins Copyright © 2011 by Andrew Coles and David G. Hawkins.
Appendix C: TradeStation Code for the MIDAS Topfinder/Bottomfinder Curves ported to Tradingview
This script requires a working understanding of "Midas Technical Analysis" Google "Midas Technical Analysis" and a variety of information will appear.
To find fit the curve as described in the Midas book a companion script is required that will after a few manual iterative inputs guide you to the appropriate D value for the for input into this program ( see the TB-F Matcher script). You might also try the Midas average and Deltas as described in the book. I have added the 2nd, 3rd and 4th multiples of Delta.
The advantage is that there is no curve fitting. You still need to select a starting point for Midas or the topfinder bottomfinder (TB_F)
or the VWAP.
////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
See the notes in the script below
Cheers Jayy
Adaptive Regime Master: The Dual-Engine FrameworkAdaptive Regime Master: The Dual-Engine Framework
Overview
The Adaptive Regime Master: The Dual-Engine Framework is a sophisticated technical analysis tool designed to solve the "Indicator Paradox"—the reality that trend-following tools fail in sideways markets, and mean-reversion tools fail in strong trends.
Instead of forcing a single mathematical model onto an ever-changing market, this framework utilizes a Master Switch logic. It continuously analyzes market volatility and directional strength to dynamically toggle between two specialized trading engines. By identifying the current "Market Regime," the indicator automatically reconfigures its visual interface and signal logic to match the environment.
The Dual-Engine Architecture
The framework operates on a logic-gate system powered by the Average Directional Index (ADX) :
1. The Momentum Engine (Trendy Regime):
Activation: Triggered when ADX rises above the 25 threshold, signaling a confirmed trend.
Logic: Utilizes a combination of Exponential Moving Averages (EMA) for trend-following and MACD Histogram for momentum confirmation.
Visuals: The chart de-clutters to show only the EMA trend-line and momentum-based signals.
2. The Mean-Reversion Engine (Choppy Regime):
Activation: Triggered when ADX falls below 25, signaling a range-bound or consolidating market.
Logic: Switches to Bollinger Bands and the Relative Strength Index (RSI) to identify overextended price action at the range extremes.
Visuals: The EMA disappears, and the chart displays Bollinger Bands to help users visualize the "value area" and potential reversal zones.
Key Features
Alternating Signal Logic: Built-in state management ensures that signals always alternate (Buy → Sell → Buy). This prevents "signal clustering" and provides a clean, actionable roadmap for the user.
Dynamic ATR-Based Protection: The indicator calculates Stop Loss (SL) and Take Profit (TP) levels using the Average True Range (ATR) . Crucially, the multipliers adjust based on the regime: wider stops for volatile trends and tighter stops for quiet ranges.
Intrabar Execution Guard: To prevent "false exits," the framework includes a calculation safeguard that prevents SL/TP triggers on the same candle as the entry, ensuring the trade has room to breathe.
Real-Time Regime Dashboard: An on-chart table provides an immediate summary of the current ADX value, the active engine mode, and the current position status.
Visual Regime Indicator: Background color changes dynamically—Blue for Trend Mode, Orange for Range Mode.
Comprehensive Alert System: Built-in alerts for Long Entry, Short Entry, TP Hit, and SL Hit events.
How to Use
Identify the Background: A Blue background indicates the Momentum Engine is active; an Orange background indicates the Mean-Reversion Engine is active.
Execution: Follow the BUY and SELL labels. The framework handles the logic of whether it is a "breakout" or a "reversal" based on the active engine.
Risk Management: Once a signal appears, Red (SL) and Lime (TP) crosses will appear on the chart. These are your mathematical boundaries for the trade.
The Exit: The position is considered closed when price hits the SL/TP markers (indicated by orange/yellow crosses) or when an opposing signal is generated.
Monitor the Dashboard: Use the top-right table to track the current regime, ADX value, active mode, and position status in real-time.
Input Parameters
ADX Length: Period for ADX calculation (default: 14)
ADX Smoothing: Smoothing period for ADX (default: 14)
ADX Trend Threshold: Threshold to distinguish trend from range (default: 25)
EMA Length: Period for the Exponential Moving Average (default: 20)
BB Length: Period for Bollinger Bands (default: 20)
BB Multiplier: Standard deviation multiplier for Bollinger Bands (default: 2.0)
RSI Length: Period for RSI calculation (default: 14)
ATR Length: Period for Average True Range (default: 14)
ATR Mult (Trend): ATR multiplier for stop loss in trend mode (default: 1.5)
ATR Mult (Range): ATR multiplier for stop loss in range mode (default: 0.8)
Min SL % (of price): Minimum stop loss as percentage of price (default: 0.5%)
Pros and Cons
Pros:
Versatility: Performs in all market conditions, reducing the need for multiple separate indicators.
Reduced Fakeouts: Filters out "trend signals" during flat markets and "reversal signals" during parabolic moves.
Visual Clarity: Only shows the indicators relevant to the current market state, reducing cognitive load and chart clutter.
Automated Risk-Reward: Automatically plots 1:2 Risk-Reward levels based on current volatility.
Professional-Grade Logic: Implements state management to prevent signal conflicts and ensure clean alternating entries.
Multi-Timeframe Compatibility: Works on any timeframe, though optimized for intraday and swing trading.
Cons:
Lagging Nature: Like all ADX-based systems, there is a slight lag when the market transitions from a range to a trend.
Threshold Sensitivity: The default ADX threshold of 25 may need tuning for extremely low-volatility assets or different timeframes.
Not a "Holy Grail": While it filters many bad trades, sudden fundamental news or black swan events can still bypass technical logic.
Requires Discipline: Users must follow the signals and respect the SL/TP levels for the framework to be effective.
Learning Curve: New users may need time to understand the regime-switching concept and trust the automated logic.
Why Use This Framework?
Most traders lose money because they apply the wrong tool to the wrong market. They use RSI to "sell the top" of a breakout, or use Moving Averages to "buy the dip" in a sideways grind. The Adaptive Regime Master removes the emotional guesswork by mathematically defining the market state and forcing the strategy to adapt.
This is a professional-grade framework for traders who value:
Logic over emotion
Discipline over impulse
Chart cleanliness over indicator overload
Adaptive systems over static strategies
Whether you're a scalper, day trader, or swing trader, this framework provides a systematic approach to reading market conditions and executing high-probability setups with predefined risk management.
Best Practices
Never forget to adjust Stop Loss and Take Profit level related to the interval you (will) use. (Default parameters are optimized for 60m)
Always backtest the indicator on your specific asset and timeframe before live trading
Adjust the ADX threshold based on the volatility characteristics of your market
Use the framework in conjunction with proper position sizing and account risk management
Pay attention to the regime dashboard—avoid forcing trades when the market is transitioning between regimes
Set up alerts for all signal types to avoid missing opportunities
Consider fundamental analysis and news events alongside technical signals
Detailed Disclaimer
FINANCIAL RISK WARNING:
Trading foreign exchange, stocks, indices, cryptocurrencies, and commodities on margin carries a high level of risk and may not be suitable for all investors. The high degree of leverage can work against you as well as for you. Before deciding to invest in any financial instrument, you should carefully consider your investment objectives, level of experience, and risk appetite. The possibility exists that you could sustain a loss of some or all of your initial investment; therefore, you should not invest money that you cannot afford to lose.
NO INVESTMENT ADVICE:
The "Adaptive Regime Master: The Dual-Engine Framework" is an educational tool designed to assist in technical analysis. It does not constitute investment advice, financial advice, trading advice, or a recommendation to buy or sell any security or financial instrument. All content provided by this indicator is for informational and educational purposes only.
PAST PERFORMANCE:
Past performance is not indicative of future results. Hypothetical or simulated performance results have certain limitations. Unlike an actual performance record, simulated results do not represent actual trading and may not be impacted by brokerage and other slippage fees. Simulated trading programs in general are also subject to the fact that they are designed with the benefit of hindsight.
NO GUARANTEE:
No representation is being made that any account will or is likely to achieve profits or losses similar to those shown in any backtests or forward tests. The author and developers of this indicator make no warranties, expressed or implied, regarding the accuracy, completeness, or reliability of the information provided.
USER RESPONSIBILITY:
Users should perform their own due diligence and test the logic on a demo or paper trading account before applying it to live capital. You are solely responsible for your own investment and trading decisions. The author and developers assume no responsibility for any financial losses, damages, or adverse consequences incurred through the use of this tool.
ACCEPTANCE OF TERMS:
Use of this indicator constitutes acceptance of these terms and acknowledgment that you understand the risks involved in trading financial instruments.
REGULATORY NOTICE:
This indicator is not affiliated with, endorsed by, or approved by any financial regulatory authority. Always consult with a licensed financial advisor before making investment decisions.
