Volume Spike Analysis [Trendoscope]The Volume Spike Analysis is designed to detect volume spikes in a trading instrument's data. Rather than relying on the traditional method of comparing volume to its moving average, this indicator employs a distinctive approach to ensure accuracy.
Methodology
Historical Volume Comparison: The indicator first assesses the current bar's volume, say 100k, and looks back historically to determine the last instance when the volume was equal to or exceeded this level.
High Volume Bar Gap Calculation: The intervals or gaps between high volume bars are recorded. These gaps help in determining how common or rare a particular volume spike is.
Spike Magnitude Determination: Here, the extent of the volume spike is gauged in relation to either the median, lowest, or average volume of the intervening bars. The reference metric (median, lowest, or average) can be chosen by the user through the "Volume Spike Reference" input parameter.
Spike Percentile Analysis: The calculated spike magnitude (as a percentage of the reference volume) is cataloged. This collection aids in understanding the relative intensity of the current volume spike when compared to previous spikes.
Threshold Comparisons: The indicator then compares the calculated "High Volume Distance Percentile" to the "Last High Volume Distance Percentile" and the "Volume Spike Percentile" to the "Volume Spike Threshold". If these values surpass the preset thresholds, the current bar is flagged as a high volume or volume spike bar.
Visual Components
Bar Highlighting : High volume or volume spike bars are accentuated with bright colors for easy identification. All other bars have increased transparency to reduce visual clutter.
Distance from the High Volume Bar: Indication of the number of bars since the last high volume occurrence and its respective percentile.
Comparative Factors: A factor representing the magnitude by which the current volume surpasses the lowest, median, and average volumes.
Lowest, Median and Average Volumes: The lowest and median volumes are indicated by tooltips on lines marking the respective bars. The average volume is depicted as a dotted horizontal line, with a triangle marker tooltip revealing its value.
This indicator offers a nuanced analysis of volume spikes, aiding traders in making more informed decisions.
Trendoscope

ABC on Recursive Zigzag [Trendoscope]There are several implementations of ABC pattern in tradingview and pine script. However, we have made this indicator to provide users additional quantifiable information along with flexibility to experiment and develop their own strategy based on the patterns.
🎲 Highlights of this indicator over other ABC implementations are:
Implementation is based on recursive multi level zigzag allows bigger as well as smaller patterns to be identified
Allows users to set their trading rules with respect to entry, target and stop ratios, experiment and build their own strategy based on the ABC pattern.
Back test summary including win ratio and risk reward will help users understand the profitability based on different settings being used.
🎲 Concept of ABC Pattern
The ABC pattern, also known as the "Corrective Wave" or "Zigzag Pattern," is a fundamental concept in Elliott Wave Theory, which is widely used in technical analysis to identify and predict price movements in financial markets.
The ABC pattern is a three-wave corrective pattern that typically occurs within the context of a larger impulse or trending wave. It consists of two smaller waves in the opposite direction (A and C) separated by a corrective wave (B). These waves are labeled alphabetically and represent price movements.
Wave A (Impulse Wave): Wave A is the first leg of the ABC pattern and is characterized by a strong price move in the opposite direction of the prevailing trend. It is often driven by a fundamental or sentiment-driven event that temporarily disrupts the trend.
Wave B (Corrective Wave): Wave B is the corrective wave that follows Wave A. It represents a partial retracement of Wave A's price movement. Wave B can take various forms, such as a simple correction or a complex correction (e.g., a triangle or a flat correction). It typically doesn't retrace the entire length of Wave A.
Wave C (Impulse Wave): Wave C is the final leg of the ABC pattern and is characterized by a strong price move in the same direction as the prevailing trend. It often surpasses the starting point of Wave A and confirms the resumption of the larger trend.
🎲 Indicator Components
Upon loading the indicator on the chart, we can observe the following components on the chart.
Pattern Drawings is the graphical representation of present patterns. Please note that it is not necessary for patterns to be there on the chart all the time. Patterns will appear on the chart when price makes the patterns.
Trade Box is the box representing trade signals of the pattern. These trade levels are generated based on the user settings.
Summary Table is the back test summary containing details of historical pattern performance including Win Ratio and Risk Reward.
🎲 Indicator Settings
Details of each user settings are provided in the tooltips. Below is the snapshot of it.
🎲 Alerts
Basic level of alerts are built in the script using alert function to highlight the following conditions:
New ABC Pattern
Updates to existing Pattern
Both conditions will alert simple text messages. There is not much customization provided as part of this indicator. We will consider providing more options in future versions based on the interest and demand shown by users.

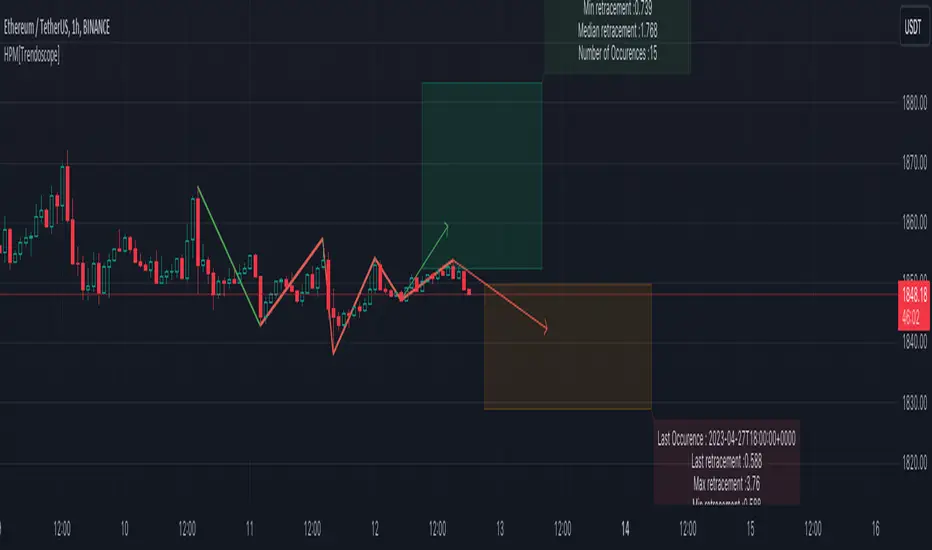
Historical Pattern Matcher [Trendoscope]Do you believe in patterns and think price movements are more likely to follow historical patterns? If yes, this is an indicator for you.
🎲 Concept
The patterns in this script are not a named or known pattern. But, it can be any pattern that happen to repeat again and again over a period of time.
The indicator collects the following information over a period of time.
Collects all possible patterns for specified number of pivots based on relation between each pivot prices. (Default 6)
Keeps track of all the possible patterns for the given pivots and number of occurrences of such patterns over a period of time.
Collects the movement of next pivot (in terms of retracement ratio) after the pattern has formed for each occurrence.
Keeps track of the last occurrence of each pattern collected
And the indicator presents on chart following information
Current Pattern drawing based on last confirmed pivot.
Current Pattern drawing based on current unconfirmed pivot in the opposite direction.
Projection range based on historical retracement ratio for both patterns
Detailed info on last occurrence and overall occurrences.
Last occurrence of both confirmed and unconfirmed pivot patterns.
Please note that, if the patterns have not been repeated over a period, then it will not be shown on the screen. Hence, it is perfectly normal to not see any projection. This can happen when the current pattern has not been repeated any time before.
🎲 Details
When you load the indicator on the chart, you may see the following patterns and projections.
You may also notice, in the pattern details, information about the last occurrence of the pattern. If you scroll on your chart to the left to the given data and time, you can observe how the past occurrence of the pattern has formed and the price movement past that point.
For example, last occurrence of pattern based on confirmed pivot happened on 02-Jun-2023 00:00 UTC time
And last occurrence of pattern based on unconfirmed pivot happened on 27-Apr-2023 22:00 UTC time
🎲 Settings
Settings are minimal, and here is the meaning of them.
Most important setting here is the number of pivots forming the pattern.
🎲 Caution
The indicator is designed to present the projection based on historical occurrences of similar price pattern. This does not necessarily mean the patterns are supposed to be bullish or bearish. But, it will certainly give users an idea of what happened when similar price action presented historically.
Note to developers This script makes use of new pine script feature - maps
PercentX Trend Follower [Trendoscope]"Trendoscope" was born from our trading journey, where we first delved into the world of trend-following methods. Over time, we discovered the captivating allure of pattern analysis and the exciting challenges it presented, drawing us into exploring new horizons. However, our dedication to trend-following methodologies remains steadfast and continues to be an integral part of our core philosophy.
Here we are, introducing another effective trend-following methodology, employing straightforward yet powerful techniques.
🎲 Concepts
Introducing the innovative PercentX Oscillator , a representation of Bollinger PercentB and Keltner Percent K. This powerful tool offers users the flexibility to customize their PercentK oscillator, including options for the type of moving average and length.
The Oscillator Range is derived dynamically, utilizing two lengths - inner and outer. The inner length initiates the calculation of the oscillator's highest and lowest range, while the outer length is used for further calculations, involving either a moving average or the opposite side of the highest/lowest range, to obtain the oscillator ranges.
Next, the Oscillator Boundaries are derived by applying another round of high/low or moving average calculations on the oscillator range values.
Breakouts occur when the close price crosses above the upper boundary or below the lower boundary, signaling potential trading opportunities.
🎲 How to trade a breakout?
To reduce false signals, we employ a simple yet effective approach. Instead of executing market trades, we use stop orders on both sides at a certain distance from the current close price.
In case of an upper side breakout, a long stop order is placed at 1XATR above the close, and a short stop order is placed at 2XATR below the close. Conversely, for a lower side breakout, a short stop order is placed at 1XATR below the close, and a long stop order is placed at 2XATR above the ATR. As a trend following method, our first inclination is to trade on the side of breakout and not to find the reversals. Hence, higher multiplier is used for the direction opposite to the breakout.
The script provides users with the option to specify ATR multipliers for both sides.
Once a trade is initiated, the opposite side of the trade is converted into a stop-loss order. In the event of a breakout, the script will either place new long and short stop orders (if no existing trade is present) or update the stop-loss orders if a trade is currently running.
As a trend-following strategy, this script does not rely on specific targets or target levels. The objective is to run the trade as long as possible to generate profits. The trade is only stopped when the stop-loss is triggered, which is updated with every breakout to secure potential gains and minimize risks.
🎲 Default trade parameters
Script uses 10% equity per trade and up to 4 pyramid orders. Hence, the maximum invested amount at a time is 40% of the equity. Due to this, the comparison between buy and hold does not show a clear picture for the trade.
Feel free to explore and optimize the parameters further for your favorite symbols.
🎲 Visual representation
The blue line represents the PercentX Oscillator, orange and lime colored lines represent oscillator ranges. And red/green lines represent oscillator boundaries. Oscillator spikes upon breakout are highlighted with color fills.
Volume Forks [Trendoscope]🎲 Volume Forks - Advanced Price Analysis with Recursive Auto-Pitchfork and Angled Volume Profile
The Volume Forks Indicator is a comprehensive research tool that combines two innovative techniques, Recursive Auto-Pitchfork and Angled Volume Profile . This indicator provides traders with valuable insights into price dynamics by integrating accurate pitchfork drawing and volume analysis over angled levels. The indicator does following things
Detects Pitchfork formations automatically on the chart over Recursive Zigzag
Instead of drawing forks based on fib levels, volume distribution over ABC of pitchfork is calculated and drawn in the direction of the handle.
🎲 Brief about Pitchfork
Pitchfork is drawn when price forms ABC pattern. Pitchfork draws a series of parallel lines in the direction of trend which can be used for support and resistance.
There are many methods of drawing pitchfork. In all cases, a line joining BC will make the base of pitchfork and fork lines are drawn from different points of the base. All the fork lines will be parallel. But, the handle of the base defines the direction of fork lines. Classification of pitchfork is mainly based on the starting and ending points of the handle.
🎲 Regular Types
Here, end of the handle is always fixed and it will be the mid point of B and C.
🎯 Andrews Pitchfork
Handle starts from A and joins the base at mid of B and C.
Forks are drawn based on fib ratios from the handle
🎯 Schiff Pitchfork
Handle starts from Bar of A and price of middle of AB and joins the base at mid of B and C
Forks are drawn based on fib ratios from the handle
🎯 Modified Schiff Pitchfork
Handle starts from mid of A and B and joins the base at mid of B and C
Forks are drawn based on fib ratios from the handle
🎲 Inside Types
Here, C will act as end of the handle which joins the Base BC .
🎯 Andrews Pitchfork (Inside)
Handle starts from A and joins the base at C
Forks are drawn based on fib ratios from the handle
🎯 Schiff Pitchfork (Inside)
Handle starts from Bar of A and price of (A+B)/2 and joins the base at C
Forks are drawn based on fib ratios from the handle
🎯 Modified Schiff Pitchfork (Inside)
Handle starts from mid of A and B and joins the base at C
Forks are drawn based on fib ratios from the handle
🎲 Brief about Pitchfork
The Angled Volume Profile technique expands on the concept of volume profile by measuring volume distribution levels over angled levels rather than just horizontal levels. By selecting a starting point and angle interactively, traders can assess volume distribution within specific price trends. This feature is particularly useful for analysing volume dynamics in trending markets.
🎲 Settings
Indicator settings include few things which determine the scanning of pitchforks and few which determines drawing of volume profile lines.
Please note that, due to pine limitations of 500 lines, if there are too many formations on the chart, volume profile may not appear correctly. If that happens, please reduce the number of volume forks per formation.

Recursive Micro Zigzag🎲 Overview
Zigzag is basic building block for any pattern recognition algorithm. This indicator is a research-oriented tool that combines the concepts of Micro Zigzag and Recursive Zigzag to facilitate a comprehensive analysis of price patterns. This indicator focuses on deriving zigzag on multiple levels in more efficient and enhanced manner in order to support enhanced pattern recognition.
The Recursive Micro Zigzag Indicator utilises the Micro Zigzag as the foundation and applies the Recursive Zigzag technique to derive higher-level zigzags. By integrating these techniques, this indicator enables researchers to analyse price patterns at multiple levels and gain a deeper understanding of market behaviour.
🎲 Concept:
Micro Zigzag Base : The indicator utilises the Micro Zigzag concept to capture detailed price movements within each candle. It allows for the visualisation of the sequential price action within the candle, aiding in pattern recognition at a micro level.
Basic implementation of micro zigzag can be found in this link - Micro-Zigzag
Recursive Zigzag Expansion : Building upon the Micro Zigzag base, the indicator applies the Recursive Zigzag concept to derive higher-level zigzags. Through recursive analysis of the Micro Zigzag's pivots, the indicator uncovers intricate patterns and trends that may not be evident in single-level zigzags.
Earlier implementations of recursive zigzag can be found here:
Recursive Zigzag
Recursive Zigzag - Trendoscope
And the libraries
rZigzag
ZigzagMethods
The major differences in this implementation are
Micro Zigzag Base - Earlier implementation made use of standard zigzag as base whereas this implementation uses Micro Zigzag as base
Not cap on Pivot depth - Earlier implementation was limited by the depth of level 0 zigzag. In this implementation, we are trying to build the recursive algorithm progressively so that there is no cap on the depth of level 0 zigzag. But, if we go for higher levels, there is chance of program timing out due to pine limitations.
These algorithms are useful in automatically spotting patterns on the chart including Harmonic Patterns, Chart Patterns, Elliot Waves and many more.
Interactive Motive Wave ChecklistHere is an interactive tool that can be used for learning a bit about Elliott Waves
🎲 How it works?
The script upon load asks users to enter 6 pivots in an order. Once all 6 pivots are selected on the interactive chart, the script will calculate if the structure is a valid motive wave.
When you load the script, you will see a prompt on the chart to select points on the chart to form 6 pivots.
When you select the 6 pivots, the checklists are populated on the chart to notify users which conditions for qualifying the selection has passed and which of them are failed.
🎲 Conditions for Motive Wave
Motive wave can be either Impulse or Diagonal Wave. Diagonal wave can be either expanding or contracting diagonals. To learn more about diagonal waves, please go through this idea.
Rules for generic motive waves are as below
Pivots in order - Checks wether the pivots selected are in progressive order.
Directions in order - Checks if the pivot directions are correct - either PH, PL, PH, PL, PH, PL or PL, PH, PL, PH, PL, PH
Wave 2 never moves beyond the start of wave 1 - Wave 2 retracement is less than 100% of wave1
Wave 3 always moves beyond the end of wave 1 - Wave 3 retracement is more than 100% of wave2
Wave 3 is never the shortest one - Checks if Wave 3 is bigger than either Wave 1 or wave 5 or both.
Now, these are the specific rules for Impulse Waves on top of Motive Wave conditions
Wave 4 never moves beyond the end of Wave 1 - meaning wave 1 and wave 4 never overlap on price scale.
Wave 1, 3, 5 are all not extended. We check for retracement ratios of more than 200% to be considered as extended wave.
Below are the conditions for Diagonal Waves on top of Motive Wave conditions
Wave4 never moves beyond the start of Wave 3 - Wave 4 retracement is less than 100%
Wave 4 always ends within the price territory of Wave 1 - Unlike impulse wave, wave 4 intersects with wave 1 in case of diagonal waves. This is the major difference between impulse and diagonal wave.
Waves are progressively expanding or contracting - Wave1 > Wave3 > Wave5 and Wave2 > Wave4 to be contracting diagonal. Wave1 < Wave3 < Wave5 and Wave2 < Wave4 to be expanding diagonal wave.
Here is an example of diagonal wave projection
Here is an example of impulse wave projection

cphelperLibrary "cphelper"
ACPU helper library - for private use. Not so meaningful for others.
calculate_rr(targetArray, rrArray, breakevenOnTarget1)
calculates risk reward for given targets
Parameters:
targetArray (float ) : array of targets
rrArray (float ) : array of risk reward
breakevenOnTarget1 (simple bool) : option to breakeven
Returns: array rrArray
trendPairs(l1StartX, l1StartY, l1EndX, l1EndY, l2StartX, l2StartY, l2EndX, l2EndY, zgColor)
creates trendline pairs
Parameters:
l1StartX (int) : startX of first line
l1StartY (float) : startY of first line
l1EndX (int) : endX of first line
l1EndY (float) : endY of first line
l2StartX (int) : startX of second line
l2StartY (float) : startY of second line
l2EndX (int) : endX of second line
l2EndY (float) : endY of second line
zgColor (color) : line color
Returns:
find_type(l1t, l2t, channelThreshold)
Finds type based on trendline pairs
Parameters:
l1t (line) : line1
l2t (line) : line2
channelThreshold (simple float) : theshold for channel identification
Returns: pattern type and flags
getFlags(flags)
Flatten flags
Parameters:
flags (bool ) : array of flags
Returns: - flattened flags isChannel, isTriangle, isWedge, isExpanding, isContracting, isFlat, isRising, isFalling
getType(typeNum)
Get type based on type number
Parameters:
typeNum (int) : number representing type
Returns: String value of type
getStatus(status, maxStatus)
Get status based on integer value representations
Parameters:
status (int) : integer representing current status
maxStatus (int) : integer representing max status
Returns: String status value
calculate_simple_targets(trendLines, settingsMatrix, patternTypeMapping, patternType)
Calculate targets based on trend lines
Parameters:
trendLines (line ) : trendline pair array
settingsMatrix (matrix) : matrix containing settings
patternTypeMapping (string ) : array containing pattern type mapping
patternType (int) : pattern type
Returns: arrays containing long and short calculated targets
recalculate_position(patternTypeAndStatusMatrix, targetMatrix, index, pIndex, status, maxStatus, targetValue, stopValue, dir, breakevenOnTarget1)
Recalculate position values
Parameters:
patternTypeAndStatusMatrix (matrix) : matrix containing pattern type and status
targetMatrix (matrix) : matrix containing targets
index (int) : current index
pIndex (int) : pattern index
status (int) : current status
maxStatus (int) : max status reached
targetValue (float) : current target value
stopValue (float) : current stop value
dir (int) : direction
breakevenOnTarget1 (simple bool) : flag to breakeven upon target1
Returns: new status and maxStatus values
draw_targets(longTargets, shortTargets, index, labelColor, patternName, positionIndex, longMaxStatus, longStatus, shortMaxStatus, shortStatus, tempBoxes, tempLines, tempLabels)
Draw targets on chart
Parameters:
longTargets (matrix) : matrix containing long targets
shortTargets (matrix) : matrix containing short targets
index (int) : current index
labelColor (color) : color of lines and labels
patternName (string) : Pattern name
positionIndex (int) : position on the chart
longMaxStatus (int) : max status for long
longStatus (int) : long status value
shortMaxStatus (int) : max status for short
shortStatus (int) : short status value
tempBoxes (box ) : temporary box array
tempLines (line ) : temporary lines array
tempLabels (label ) : temporary labels array
Returns: void
populate_open_stats(patternIdArray, barMatrix, patternTypeAndStatusMatrix, patternColorArray, longTargets, shortTargets, patternRRMatrix, OpenStatPosition, lblSizeOpenTrades)
Populate open stats table
Parameters:
patternIdArray (int ) : pattern Ids
barMatrix (matrix) : matrix containing bars
patternTypeAndStatusMatrix (matrix) : matrix containing pattern type and status
patternColorArray (color ) : array containing current patter colors
longTargets (matrix) : matrix of long targets
shortTargets (matrix) : matrix of short targets
patternRRMatrix (matrix) : pattern risk reward matrix
OpenStatPosition (simple string) : table position
lblSizeOpenTrades (simple string) : text size
Returns: void
draw_pattern_label(trendLines, patternFlagMatrix, patternTypeAndStatusMatrix, patternColorArray, patternFlags, patternLabelArray, zgColor, patternType, drawLabel, clearOldPatterns, safeRepaint, maxPatternsReference)
Parameters:
trendLines (line )
patternFlagMatrix (matrix)
patternTypeAndStatusMatrix (matrix)
patternColorArray (color )
patternFlags (bool )
patternLabelArray (label )
zgColor (color)
patternType (int)
drawLabel (simple bool)
clearOldPatterns (simple bool)
safeRepaint (simple bool)
maxPatternsReference (simple int)
populate_closed_stats(patternTypeAndStatusMatrix, bullishCounts, bearishCounts, bullishRetouchCounts, bearishRetouchCounts, bullishSizeMatrix, bearishSizeMatrix, bullishRR, bearishRR, ClosedStatsPosition, lblSizeClosedTrades, showSelectivePatternStats, showPatternStats, showStatsInPercentage)
Parameters:
patternTypeAndStatusMatrix (matrix)
bullishCounts (matrix)
bearishCounts (matrix)
bullishRetouchCounts (matrix)
bearishRetouchCounts (matrix)
bullishSizeMatrix (matrix)
bearishSizeMatrix (matrix)
bullishRR (matrix)
bearishRR (matrix)
ClosedStatsPosition (simple string)
lblSizeClosedTrades (simple string)
showSelectivePatternStats (simple bool)
showPatternStats (simple bool)
showStatsInPercentage (simple bool)
Master Supertrend Strategy [Trendoscope]Here is the strategy version of the indicator - Master Supertrend
Options and variations are same throughout.
🎲 Variations
Following variations are provided in the form of settings.
🎯 Range Type
Instead of ATR, different types of ranges can be used for stop calculation. Here is the complete list used in the script.
Plus/Minus Range* - Calculates plus range and minus range for each candle and uses them for different sides of stop calculation
Ladder ATR - Based on the existing concept of Ladder ATR defined in Supertrend-Ladder-ATR
True Range - True range derived from standard function ta.tr
Standard Deviation - Standard deviation of close prices
🎯 Applied Calculation
In standard ATR, rma of TR is used for calculations. But, the application calculation provides option to users to use different mechanisms. It can be a type of moving average or few other types of calculations.
Available values are
sma
ema
hma
rma
wma
high
median
🎯 Other options
Few other options provided are
Use Close Price - If selected stops are calculated based on the close price instead of high/low prices
Wait for Close If selected, change of supertrend direction is calculated based on close price instead of high/low prices
Diminishing Stop Distance - When selected, stop distance for the trend direction can only reduce and cannot increase. This option is useful for keeping the tight stops on strong trends.
🎯 Plus Minus Range*
One of the range type used is Plus/Minus Range. What it means and how are these ranges calculated? Let's have a look.
Plus Range is an upward movement of a candle from its last price or open price whichever is lower.
Minus Range is a downward movement of a candle from its last price or open price whichever is higher.
This divides True Range into two separate range for positive and negative side.
Note : Effectiveness on daily charts are quire visible. However, if you want to use it for lower timeframes, please play around with settings before settling on suitable configuration.

Master Supertrend [Trendoscope]Are you a fan of supertrend? Me too!! Here is a supertrend indicator which provides multiple variation options to chose from.
🎲 Introduction
Supertrend is a popular technical indicator used by traders to identify potential trend reversals and determine entry and exit points in financial markets. It is a trend-following indicator that combines price and volatility to generate its signals. Generally supertrend is calculated based on ATR and multiplier value which is used for calculation of stops. In these adaptions, we look to provide few variations to classical methods.
🎲 Variations
Following variations are provided in the form of settings.
🎯 Range Type
Instead of ATR, different types of ranges can be used for stop calculation. Here is the complete list used in the script.
Plus/Minus Range - Calculates plus range and minus range for each candle and uses them for different sides of stop calculation
Ladder ATR - Based on the existing concept of Ladder ATR defined in Supertrend-Ladder-ATR
True Range - True range derived from standard function ta.tr
Standard Deviation - Standard deviation of close prices
🎯 Applied Calculation
In standard ATR, rma of TR is used for calculations. But, the application calculation provides option to users to use different mechanisms. It can be a type of moving average or few other types of calculations.
Available values are
sma
ema
hma
rma
wma
high
median
medianHigh (Highest of the last N medians)
medianLow (Lowest of the last N medians)
🎯 Other options
Few other options provided are
Use Close Price - If selected stops are calculated based on the close price instead of high/low prices
Wait for Close If selected, change of supertrend direction is calculated based on close price instead of high/low prices
Diminishing Stop Distance - When selected, stop distance for the trend direction can only reduce and cannot increase. This option is useful for keeping the tight stops on strong trends.
🎯 Plus Minus Range
One of the range type used is Plus/Minus Range. What it means and how are these ranges calculated? Let's have a look.
Plus Range is an upward movement of a candle from its last price or open price whichever is lower.
Minus Range is a downward movement of a candle from its last price or open price whichever is higher.
This divides True Range into two separate range for positive and negative side.
Here are the simple settings in nutshell which reflects the same.
Recursive Reversal Chart Patterns [Trendoscope]Caution: This algorithm is very heavy and bound to cause timeouts. If that happens, there are few settings you can change to reduce the load. (Will explain them in the description below)
🎲 Recursive Reversal Chart Patterns Indicator
Welcome to another exploration of Zigzag and Pattern ecosystem components. Previously we derived Pitchfork and Recursive Zigzag indicators. This indicator is designed to scan and highlight few popular "Reversal Chart Patterns". Similar to other indicators in the ecosystem, this too is built on recursive zigzags.
Double Taps
Triple Taps
Cup and Handles
Head and Shoulders
Indicator however names the patterns separately for bullish and bearish formations. So, the actual names you see on the screen are
Double Top
Double Bottom
Triple Top
Triple Bottom
Cup and Handle
Inverted Cup and Handle
Head and Shoulders
Inverse Head and Shoulders
Here is a snapshot on how each category of patterns look on the chart.
🎲 Architecture
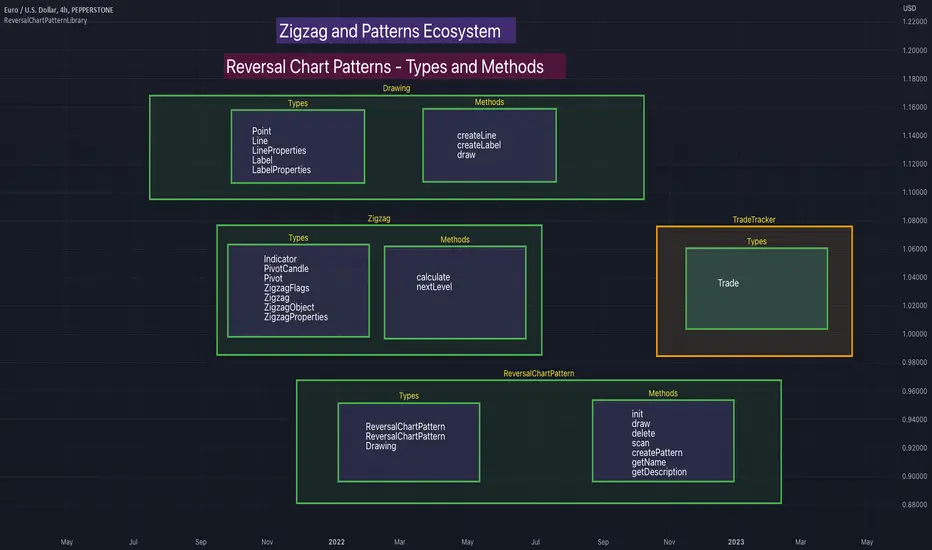
Many of you may be cursing me for publishing too many libraries. But, these are all preparations for something big. Like other indicators in the Zigzag and Patterns Ecosystem, this too uses a bunch of libraries.
🎯Major direct dependencies
ZigzagTypes
ZigzagMethods
ReversalChartPatternLibrary
🎯Indirect dependencies
DrawingTypes
DrawingMethods
🎯Minor dependencies
Utils
TradeTracker
🎲 Indicator Settings
🎯Generic and Zigzag Settings.
Note: In case of timeout, please decrease the value of depth parameter
🎯Pattern Selection
Having all the patterns selected on chart may also cause timeouts and will make the chart look messy. It is better to limit one or two patterns on the chart to have clear picture.
🎯Scanner Settings
🎯Indicators.
These are options to use indicators as secondary confirmation to calculate divergence. If selected, the patterns are shown only if the divergence data is inline. Option also available to plugin external indicator. These calculations are not straightforward and not easy to measure by manual inspection. This feature at present is purely experimental.
Have a go and let me know how you feel :)

ReversalChartPatternLibraryLibrary "ReversalChartPatternLibrary"
User Defined Types and Methods for reversal chart patterns - Double Top, Double Bottom, Triple Top, Triple Bottom, Cup and Handle, Inverted Cup and Handle, Head and Shoulders, Inverse Head and Shoulders
method delete(this)
Deletes the drawing components of ReversalChartPatternDrawing object
Namespace types: ReversalChartPatternDrawing
Parameters:
this (ReversalChartPatternDrawing) : ReversalChartPatternDrawing object
Returns: current ReversalChartPatternDrawing object
method delete(this)
Deletes the drawing components of ReversalChartPattern object. In turn calls the delete of ReversalChartPatternDrawing
Namespace types: ReversalChartPattern
Parameters:
this (ReversalChartPattern) : ReversalChartPattern object
Returns: current ReversalChartPattern object
method lpush(this, obj, limit, deleteOld)
Array push with limited number of items in the array. Old items are deleted when new one comes and exceeds the limit
Namespace types: ReversalChartPattern
Parameters:
this (ReversalChartPattern ) : array object
obj (ReversalChartPattern) : ReversalChartPattern object which need to be pushed to the array
limit (int) : max items on the array. Default is 10
deleteOld (bool) : If set to true, also deletes the drawing objects. If not, the drawing objects are kept but the pattern object is removed from array. Default is false.
Returns: current ReversalChartPattern object
method draw(this)
Draws the components of ReversalChartPatternDrawing
Namespace types: ReversalChartPatternDrawing
Parameters:
this (ReversalChartPatternDrawing) : ReversalChartPatternDrawing object
Returns: current ReversalChartPatternDrawing object
method draw(this)
Draws the components of ReversalChartPatternDrawing within the ReversalChartPattern object.
Namespace types: ReversalChartPattern
Parameters:
this (ReversalChartPattern) : ReversalChartPattern object
Returns: current ReversalChartPattern object
method scan(zigzag, patterns, errorPercent, shoulderStart, shoulderEnd)
Scans zigzag for ReversalChartPattern occurences
Namespace types: zg.Zigzag
Parameters:
zigzag (Zigzag type from HeWhoMustNotBeNamed/ZigzagTypes/2) : ZigzagTypes.Zigzag object having array of zigzag pivots and other information on each pivots
patterns (ReversalChartPattern ) : Existing patterns array. Used for validating duplicates
errorPercent (float) : Error threshold for considering ratios. Default is 13
shoulderStart (float) : Starting range of shoulder ratio. Used for identifying shoulders, handles and necklines
shoulderEnd (float) : Ending range of shoulder ratio. Used for identifying shoulders, handles and necklines
Returns: int pattern type
method createPattern(zigzag, patternType, patternColor, riskAdjustment)
Create Pattern from ZigzagTypes.Zigzag object
Namespace types: zg.Zigzag
Parameters:
zigzag (Zigzag type from HeWhoMustNotBeNamed/ZigzagTypes/2) : ZigzagTypes.Zigzag object having array of zigzag pivots and other information on each pivots
patternType (int) : Type of pattern being created. 1 - Double Tap, 2 - Triple Tap, 3 - Cup and Handle, 4 - Head and Shoulders
patternColor (color) : Color in which the patterns are drawn
riskAdjustment (float) : Used for calculating stops
Returns: ReversalChartPattern object created
method getName(this)
get pattern name of ReversalChartPattern object
Namespace types: ReversalChartPattern
Parameters:
this (ReversalChartPattern) : ReversalChartPattern object
Returns: string name of the pattern
method getDescription(this)
get consolidated description of ReversalChartPattern object
Namespace types: ReversalChartPattern
Parameters:
this (ReversalChartPattern) : ReversalChartPattern object
Returns: string consolidated description
method init(this)
initializes the ReversalChartPattern object and creates sub object types
Namespace types: ReversalChartPattern
Parameters:
this (ReversalChartPattern) : ReversalChartPattern object
Returns: ReversalChartPattern current object
ReversalChartPatternDrawing
Type which holds the drawing objects for Reversal Chart Pattern Types
Fields:
patternLines (Line type from HeWhoMustNotBeNamed/DrawingTypes/1) : array of Line objects representing pattern
entry (Line type from HeWhoMustNotBeNamed/DrawingTypes/1) : Entry price Line
target (Line type from HeWhoMustNotBeNamed/DrawingTypes/1) : Target price Line
patternLabel (Label type from HeWhoMustNotBeNamed/DrawingTypes/1)
ReversalChartPattern
Reversal Chart Pattern master type which holds the pattern components, drawings and trade details
Fields:
pivots (Pivot type from HeWhoMustNotBeNamed/ZigzagTypes/2) : Array of Zigzag Pivots forming the pattern
patternType (series int) : Defines the main type of pattern 1 - Double Tap, 1 - Triple Tap, 3 - Cup and Handle, 4 - Head and Shoulders
patternColor (series color) : Color in which the pattern will be drawn on chart
riskAdjustment (series float) : Percentage adjustment of risk. Used for setting stops
drawing (ReversalChartPatternDrawing) : ReversalChartPatternDrawing object which holds the drawing components
trade (Trade type from HeWhoMustNotBeNamed/TradeTracker/1) : TradeTracker.Trade object holding trade components
TradeTrackerLibrary "TradeTracker"
Simple Library for tracking trades
method track(this)
tracks trade when called on every bar
Namespace types: Trade
Parameters:
this (Trade) : Trade object
Returns: current Trade object
Trade
Has the constituents to track trades generated by any method.
Fields:
id (series int)
direction (series int) : Trade direction. Positive values for long and negative values for short trades
initialEntry (series float) : Initial entry price. This value will not change even if the entry is changed in the lifecycle of the trade
entry (series float) : Updated entry price. Allows variations to initial calculated entry. Useful in cases of trailing entry.
initialStop (series float) : Initial stop. Similar to initial entry, this is the first calculated stop for the lifecycle of trade.
stop (series float) : Trailing Stop. If there is no trailing, the value will be same as that of initial trade
targets (float ) : array of target values.
startBar (series int) : bar index of starting bar. Set by default when object is created. No need to alter this after that.
endBar (series int) : bar index of last bar in trade. Set by tracker on each execution
startTime (series int) : time of the start bar. Set by default when object is created. No need to alter this after that.
endTime (series int) : time of the ending bar. Updated by tracking method.
status (series int) : Integer parameter to track the status of the trade
retest (series bool) : Boolean parameter to notify if there was retest of the entry price
Session Filter [Trendoscope]🎲 Session Filter: A Customisable Trading Indicator for Defining Preferred Trade Sessions
Session Filter is a simple trading indicator that enables traders to define their preferred trading sessions and optimise their approach based on individual preferences. By providing a range of flexible customisation options, Session Filter can help traders reduce risk, increase accuracy, by helping them to adhere to their trading sessions. Features include
🎯 Customisable Trading Sessions
One of the key features of Session Filter is the ability to select from four different trading sessions. These sessions are designed to be flexible, making it easy to tailor your approach to specific markets, assets, and trading styles. By selecting the sessions that are most relevant to your strategy, you can reduce the risk of making trades during less favourable market conditions.
For example, if you prefer to trade during the Asian session, you can set the session times to "Asian Session" in input settings. This will highlight the specific times when the Asian markets are open, allowing you to focus your trading activity during these periods. By doing so, you can avoid trading during times when the market is less active or more volatile.
🎯 Customisable Timezone and Days of the Week:
In addition to customisable trading sessions, Session Filter also allows users to select a timezone and specific days of the week. This ensures that the displayed trading zones and signals are aligned with your local time, and that you can tailor your approach to your preferred schedule. This is particularly useful for traders who have other commitments, or who prefer to focus on specific markets or assets on certain days.
For example, if you are based in New York and prefer to trade during the European session, you can select the "European Session" option in Session Filter and adjust the timezone to reflect your local time. You can also select specific days of the week when you prefer to trade during the European session, such as Tuesday through Thursday. This allows you to optimize your approach based on your personal preferences and schedule.
🎯 Easy Visual Interpretation:
Session Filter uses green and red overlays on the chart to indicate the trading zones, making it easy for users to visually identify their trading sessions
For example, when a green overlay is displayed on the chart, this indicates that the market is within the selected trading session and that it may be a good time to start trade. Conversely, when a red overlay is displayed, this indicates that the market is outside of the selected trading session and that it may be a good time close all trading. By providing this visual feedback, Session Filter helps traders stay focused and disciplined, and avoid making impulsive trading decisions.
🎯Force Exit Signal for Risk Management:
Session Filter also offers the ability to generate a force exit signal when not in any of the selected sessions. This can be used in conjunction with alerts to exit all trades outsize session zone.
For example, if you are using Session Filter to trade during the European session, but the market is particularly volatile during a specific day, the force exit signal will be generated to indicate that it may be a good time to exit your trade. This helps you avoid potential losses and stay disciplined during periods of market turbulence.
🎯External Signal Plots:
In addition to the chart overlays, Session Filter also plots signals on the data window that can be used as external inputs in other indicators and strategies. This feature allows traders to incorporate the signals generated by Session Filter into their existing trading systems and this can be used as additional filters on an existing strategy or methodology.
🎯Alerts using Alert Conditions
Alerts are provided for start and end of session so that users can make use of it to set auto turn on or off their bots.
Settings are pretty simple and are explained here.

HarmonicPatternTrackingLibrary "HarmonicPatternTracking"
Library contains few data structures and methods for tracking harmonic pattern trades via pinescript.
method draw(this)
Creates and draws HarmonicDrawing object for given HarmonicPattern
Namespace types: HarmonicPattern
Parameters:
this (HarmonicPattern) : HarmonicPattern object
Returns: current HarmonicPattern object
method addTrade(this)
calculates HarmonicTrade and sets trade object for HarmonicPattern
Namespace types: HarmonicPattern
Parameters:
this (HarmonicPattern) : HarmonicPattern object
Returns: bool true if pattern trades are valid, false otherwise
method delete(this)
Deletes drawing objects of HarmonicDrawing
Namespace types: HarmonicDrawing
Parameters:
this (HarmonicDrawing) : HarmonicDrawing object
Returns: current HarmonicDrawing object
method delete(this)
Deletes drawings of harmonic pattern
Namespace types: HarmonicPattern
Parameters:
this (HarmonicPattern) : HarmonicPattern object
Returns: current HarmonicPattern object
HarmonicDrawing
Drawing objects of Harmonic Pattern
Fields:
xa (series line) : xa line
ab (series line) : ab line
bc (series line) : bc line
cd (series line) : cd line
xb (series line) : xb line
bd (series line) : bd line
ac (series line) : ac line
xd (series line) : xd line
x (series label) : label for pivot x
a (series label) : label for pivot a
b (series label) : label for pivot b
c (series label) : label for pivot c
d (series label) : label for pivot d
xabRatio (series label) : label for XAB Ratio
abcRatio (series label) : label for ABC Ratio
bcdRatio (series label) : label for BCD Ratio
xadRatio (series label) : label for XAD Ratio
HarmonicTrade
Trade tracking parameters of Harmonic Patterns
Fields:
initialEntry (series float) : initial entry when pattern first formed.
entry (series float) : trailed entry price.
initialStop (series float) : initial stop when trade first entered.
stop (series float) : current stop updated as per trailing rules.
target1 (series float) : First target value
target2 (series float) : Second target value
target3 (series float) : Third target value
target4 (series float) : Fourth target value
status (series int) : Trade status referenced as integer
retouch (series bool) : Flag to show if the price retouched after entry
HarmonicProperties
Display and trade calculation properties for Harmonic Patterns
Fields:
fillMajorTriangles (series bool) : Display property used for using linefill for harmonic major triangles
fillMinorTriangles (series bool) : Display property used for using linefill for harmonic minor triangles
majorFillTransparency (series int) : transparency setting for major triangles
minorFillTransparency (series int) : transparency setting for minor triangles
showXABCD (series bool) : Display XABCD pivot labels
lblSizePivots (series string) : Pivot label size
showRatios (series bool) : Display Ratio labels
useLogScaleForScan (series bool) : Use log scale to determine fib ratios for pattern scanning
useLogScaleForTargets (series bool) : Use log scale to determine fib ratios for target calculation
base (series string) : base on which calculation of stop/targets are made.
entryRatio (series float) : fib ratio to calculate entry
stopRatio (series float) : fib ratio to calculate initial stop
target1Ratio (series float) : fib ratio to calculate first target
target2Ratio (series float) : fib ratio to calculate second target
target3Ratio (series float) : fib ratio to calculate third target
target4Ratio (series float) : fib ratio to calculate fourth target
HarmonicPattern
Harmonic pattern object to track entire pattern trade life cycle
Fields:
id (series int) : Pattern Id
dir (series int) : pattern direction
x (series float) : X Pivot
a (series float) : A Pivot
b (series float) : B Pivot
c (series float) : C Pivot
d (series float) : D Pivot
xBar (series int) : Bar index of X Pivot
aBar (series int) : Bar index of A Pivot
bBar (series int) : Bar index of B Pivot
cBar (series int) : Bar index of C Pivot
dBar (series int) : Bar index of D Pivot
przStart (series float) : Start of PRZ range
przEnd (series float) : End of PRZ range
patterns (bool ) : array representing the patterns
patternLabel (series string) : string representation of list of patterns
patternColor (series color) : color assigned to pattern
properties (HarmonicProperties) : HarmonicProperties object containing display and calculation properties
trade (HarmonicTrade) : HarmonicTrade object to track trades
drawing (HarmonicDrawing) : HarmonicDrawing object to manage drawings
Angled Volume Profile [Trendoscope]Volume profile is useful tool to understand the demand and supply zones on horizontal level. But, what if you want to measure the volume levels over trend line? In trending markets, the feature to measure volume over angled levels can be very useful for traders who use these measures. Here is an attempt to provide such tool.
🎲 How to use
🎯 Interactive input for selecting starting point and angle.
Upon loading the script, you will be prompted to select
Start time and price - this is a point which you can select by moving the maroon highlighted label.
End price - though this is shown as maroon bullet, this is price only input. Hence, when you click on the bullet, a horizontal line will appear. Users can move the line to use different End price.
Start and End price are used for identifying the angle at which volume profile need to be calculated. Whereas start time is used as starting time of the volume profile. Last bar of the chart is considered as ending bar.
🎯 Other settings.
From settings, users can select the colour of volume profile and style. Step multiplier defines the distance at which the profile lines needs to be drawn. Higher multiplier leads to less dense profile lines whereas lower multiplier leads to higher density of profile lines.
🎲 Limitations
🎯 Max 500 lines
Pinescript only allows max 500 lines on an indicator. Due to this, if we set very low multiplier - this can lead to more than 500 profile lines. Due to this some lines can get removed.
On the contrary, if multiplier is too high, then you will see very few lines which may not be meaningful.
Hence, it is important to select optimal multiplier based on your timeframe
🎯 No updates on new bar
Since the profile can spawn many bars, it is not possible to recalculate the whole volume profile when price creates new bars. Hence, there will not be visual update when new bars are created. But, to update the chart, users only need to make another movement of Start or ending point on interactive input.

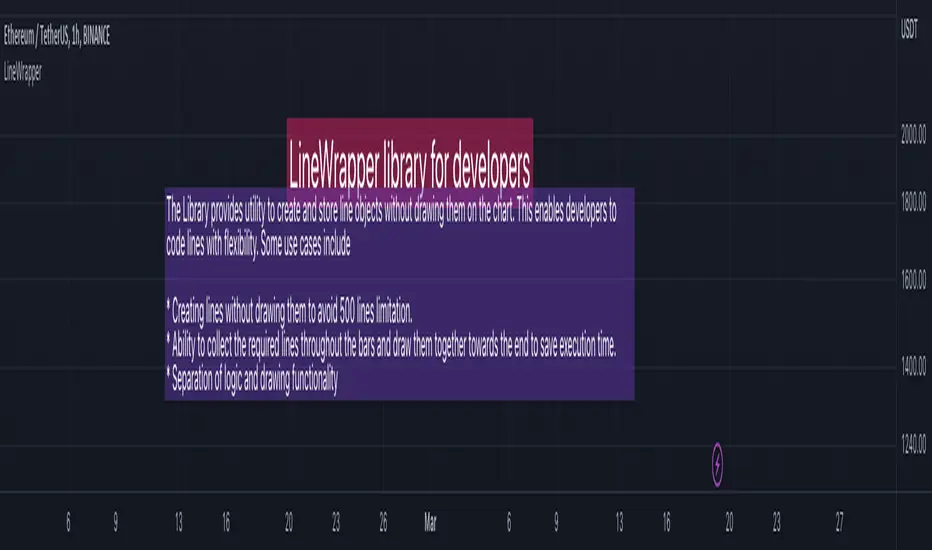
LineWrapperLibrary "LineWrapper"
Wrapper Type for Line. Useful when you want to store the line details without drawing them. Can also be used in scnearios where you collect lines to be drawn and draw together towards the end.
draw(this)
draws line as per the wrapper object contents
Parameters:
this : (series Line) Line object.
Returns: current Line object
draw(this)
draws lines as per the wrapper object array
Parameters:
this : (series array) Array of Line object.
Returns: current Array of Line objects
update(this)
updates or redraws line as per the wrapper object contents
Parameters:
this : (series Line) Line object.
Returns: current Line object
update(this)
updates or redraws lines as per the wrapper object array
Parameters:
this : (series array) Array of Line object.
Returns: current Array of Line objects
get_price(this, bar)
get line price based on bar
Parameters:
this : (series Line) Line object.
bar : (series/int) bar at which line price need to be calculated
Returns: line price at given bar.
get_x1(this)
Returns UNIX time or bar index (depending on the last xloc value set) of the first point of the line.
Parameters:
this : (series Line) Line object.
Returns: UNIX timestamp (in milliseconds) or bar index.
get_x2(this)
Returns UNIX time or bar index (depending on the last xloc value set) of the second point of the line.
Parameters:
this : (series Line) Line object.
Returns: UNIX timestamp (in milliseconds) or bar index.
get_y1(this)
Returns price of the first point of the line.
Parameters:
this : (series Line) Line object.
Returns: Price value.
get_y2(this)
Returns price of the second point of the line.
Parameters:
this : (series Line) Line object.
Returns: Price value.
set_x1(this, x, draw, update)
Sets bar index or bar time (depending on the xloc) of the first point.
Parameters:
this : (series Line) Line object.
x : (series int) Bar index or bar time. Note that objects positioned using xloc.bar_index cannot be drawn further than 500 bars into the future.
draw : (series bool) draw line after setting attribute
update : (series bool) update line instead of redraw. Only valid if draw is set.
Returns: Current Line object
set_x2(this, x, draw, update)
Sets bar index or bar time (depending on the xloc) of the second point.
Parameters:
this : (series Line) Line object.
x : (series int) Bar index or bar time. Note that objects positioned using xloc.bar_index cannot be drawn further than 500 bars into the future.
draw : (series bool) draw line after setting attribute
update : (series bool) update line instead of redraw. Only valid if draw is set.
Returns: Current Line object
set_y1(this, y, draw, update)
Sets price of the first point
Parameters:
this : (series Line) Line object.
y : (series int/float) Price.
draw : (series bool) draw line after setting attribute
update : (series bool) update line instead of redraw. Only valid if draw is set.
Returns: Current Line object
set_y2(this, y, draw, update)
Sets price of the second point
Parameters:
this : (series Line) Line object.
y : (series int/float) Price.
draw : (series bool) draw line after setting attribute
update : (series bool) update line instead of redraw. Only valid if draw is set.
Returns: Current Line object
set_color(this, color, draw, update)
Sets the line color
Parameters:
this : (series Line) Line object.
color : (series color) New line color
draw : (series bool) draw line after setting attribute
update : (series bool) update line instead of redraw. Only valid if draw is set.
Returns: Current Line object
set_extend(this, extend, draw, update)
Sets extending type of this line object. If extend=extend.none, draws segment starting at point (x1, y1) and ending at point (x2, y2). If extend is equal to extend.right or extend.left, draws a ray starting at point (x1, y1) or (x2, y2), respectively. If extend=extend.both, draws a straight line that goes through these points.
Parameters:
this : (series Line) Line object.
extend : (series string) New extending type.
draw : (series bool) draw line after setting attribute
update : (series bool) update line instead of redraw. Only valid if draw is set.
Returns: Current Line object
set_style(this, style, draw, update)
Sets the line style
Parameters:
this : (series Line) Line object.
style : (series string) New line style.
draw : (series bool) draw line after setting attribute
update : (series bool) update line instead of redraw. Only valid if draw is set.
Returns: Current Line object
set_width(this, width, draw, update)
Sets the line width.
Parameters:
this : (series Line) Line object.
width : (series int) New line width in pixels.
draw : (series bool) draw line after setting attribute
update : (series bool) update line instead of redraw. Only valid if draw is set.
Returns: Current Line object
set_xloc(this, x1, x2, xloc, draw, update)
Sets x-location and new bar index/time values.
Parameters:
this : (series Line) Line object.
x1 : (series int) Bar index or bar time of the first point.
x2 : (series int) Bar index or bar time of the second point.
xloc : (series string) New x-location value.
draw : (series bool) draw line after setting attribute
update : (series bool) update line instead of redraw. Only valid if draw is set.
Returns: Current Line object
set_xy1(this, x, y, draw, update)
Sets bar index/time and price of the first point.
Parameters:
this : (series Line) Line object.
x : (series int) Bar index or bar time. Note that objects positioned using xloc.bar_index cannot be drawn further than 500 bars into the future.
y : (series int/float) Price.
draw : (series bool) draw line after setting attribute
update : (series bool) update line instead of redraw. Only valid if draw is set.
Returns: Current Line object
set_xy2(this, x, y, draw, update)
Sets bar index/time and price of the second point
Parameters:
this : (series Line) Line object.
x : (series int) Bar index or bar time. Note that objects positioned using xloc.bar_index cannot be drawn further than 500 bars into the future.
y : (series int/float) Price.
draw : (series bool) draw line after setting attribute
update : (series bool) update line instead of redraw. Only valid if draw is set.
Returns: Current Line object
delete(this)
Deletes the underlying line drawing object
Parameters:
this : (series Line) Line object.
Returns: Current Line object
Line
Line Wrapper object
Fields:
x1 : (series int) Bar index (if xloc = xloc.bar_index) or bar UNIX time (if xloc = xloc.bar_time) of the first point of the line. Note that objects positioned using xloc.bar_index cannot be drawn further than 500 bars into the future.
y1 : (series int/float) Price of the first point of the line.
x2 : (series int) Bar index (if xloc = xloc.bar_index) or bar UNIX time (if xloc = xloc.bar_time) of the second point of the line. Note that objects positioned using xloc.bar_index cannot be drawn further than 500 bars into the future.
y2 : (series int/float) Price of the second point of the line.
xloc : (series string) See description of x1 argument. Possible values: xloc.bar_index and xloc.bar_time. Default is xloc.bar_index.
extend : (series string) If extend=extend.none, draws segment starting at point (x1, y1) and ending at point (x2, y2). If extend is equal to extend.right or extend.left, draws a ray starting at point (x1, y1) or (x2, y2), respectively. If extend=extend.both, draws a straight line that goes through these points. Default value is extend.none.
color : (series color) Line color.
style : (series string) Line style. Possible values: line.style_solid, line.style_dotted, line.style_dashed, line.style_arrow_left, line.style_arrow_right, line.style_arrow_both.
width : (series int) Line width in pixels.
obj : line object
DataChartLibrary "DataChart"
Library to plot scatterplot or heatmaps for your own set of data samples
draw(this)
draw contents of the chart object
Parameters:
this : Chart object
Returns: current chart object
init(this)
Initialize Chart object.
Parameters:
this : Chart object to be initialized
Returns: current chart object
addSample(this, sample, trigger)
Add sample data to chart using Sample object
Parameters:
this : Chart object
sample : Sample object containing sample x and y values to be plotted
trigger : Samples are added to chart only if trigger is set to true. Default value is true
Returns: current chart object
addSample(this, x, y, trigger)
Add sample data to chart using x and y values
Parameters:
this : Chart object
x : x value of sample data
y : y value of sample data
trigger : Samples are added to chart only if trigger is set to true. Default value is true
Returns: current chart object
addPriceSample(this, priceSampleData, config)
Add price sample data - special type of sample designed to measure price displacements of events
Parameters:
this : Chart object
priceSampleData : PriceSampleData object containing event driven displacement data of x and y
config : PriceSampleConfig object containing configurations for deriving x and y from priceSampleData
Returns: current chart object
Sample
Sample data for chart
Fields:
xValue : x value of the sample data
yValue : y value of the sample data
ChartProperties
Properties of plotting chart
Fields:
title : Title of the chart
suffix : Suffix for values. It can be used to reference 10X or 4% etc. Used only if format is not format.percent
matrixSize : size of the matrix used for plotting
chartType : Can be either scatterplot or heatmap. Default is scatterplot
outliersStart : Indicates the percentile of data to filter out from the starting point to get rid of outliers
outliersEnd : Indicates the percentile of data to filter out from the ending point to get rid of outliers.
backgroundColor
plotColor : color of plots on the chart. Default is color.yellow. Only used for scatterplot type
heatmapColor : color of heatmaps on the chart. Default is color.red. Only used for heatmap type
borderColor : border color of the chart table. Default is color.yellow.
plotSize : size of scatter plots. Default is size.large
format : data representation format in tooltips. Use mintick.percent if measuring any data in terms of percent. Else, use format.mintick
showCounters : display counters which shows totals on each quadrants. These are single cell tables at the corners displaying number of occurences on each quadrant.
showTitle : display title at the top center. Uses the title string set in the properties
counterBackground : background color of counter table cells. Default is color.teal
counterTextColor : text color of counter table cells. Default is color.white
counterTextSize : size of counter table cells. Default is size.large
titleBackground : background color of chart title. Default is color.maroon
titleTextColor : text color of the chart title. Default is color.white
titleTextSize : text size of the title cell. Default is size.large
addOutliersToBorder : If set, instead of removing the outliers, it will be added to the border cells.
useCommonScale : Use common scale for both x and y. If not selected, different scales are calculated based on range of x and y values from samples. Default is set to false.
plotchar : scatter plot character. Default is set to ascii bullet.
ChartDrawing
Chart drawing objects collection
Fields:
properties : ChartProperties object which determines the type and characteristics of chart being plotted
titleTable : table containing title of the chart.
mainTable : table containing plots or heatmaps.
quadrantTables : Array of tables containing counters of all 4 quandrants
Chart
Chart type which contains all the information of chart being plotted
Fields:
properties : ChartProperties object which determines the type and characteristics of chart being plotted
samples : Array of Sample objects collected over period of time for plotting on chart.
displacements : Array containing displacement values. Both x and y values
displacementX : Array containing only X displacement values.
displacementY : Array containing only Y displacement values.
drawing : ChartDrawing object which contains all the drawing elements
PriceSampleConfig
Configs used for adding specific type of samples called PriceSamples
Fields:
duration : impact duration for which price displacement samples are calculated.
useAtrReference : Default is true. If set to true, price is measured in terms of Atr. Else is measured in terms of percentage of price.
atrLength : atrLength to be used for measuring the price based on ATR. Used only if useAtrReference is set to true.
PriceSampleData
Special type of sample called price sample. Can be used instead of basic Sample type
Fields:
trigger : consider sample only if trigger is set to true. Default is true.
source : Price source. Default is close
highSource : High price source. Default is high
lowSource : Low price source. Default is low
tr : True range value. Default is ta.tr

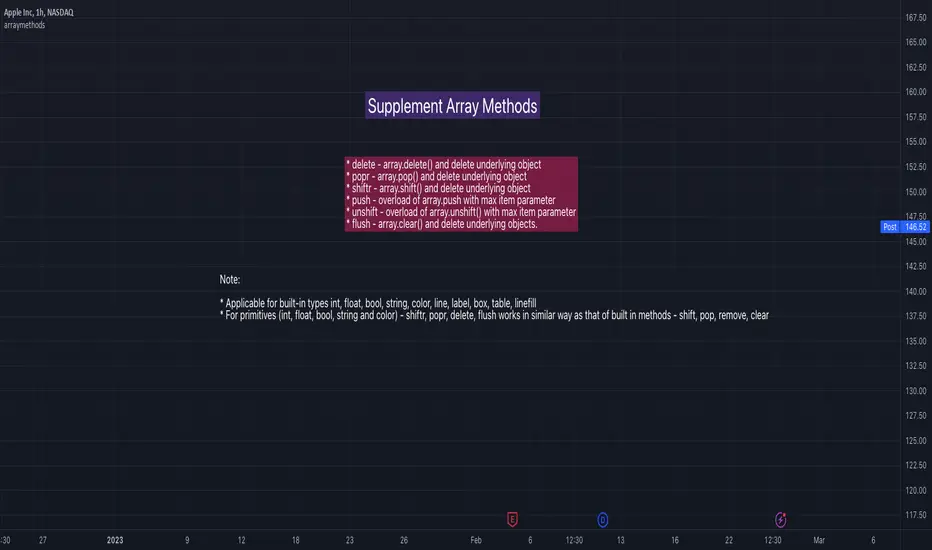
arraymethodsLibrary "arraymethods"
Supplementary array methods.
delete(arr, index)
remove int object from array of integers at specific index
Parameters:
arr : int array
index : index at which int object need to be removed
Returns: void
delete(arr, index)
remove float object from array of float at specific index
Parameters:
arr : float array
index : index at which float object need to be removed
Returns: float
delete(arr, index)
remove bool object from array of bool at specific index
Parameters:
arr : bool array
index : index at which bool object need to be removed
Returns: bool
delete(arr, index)
remove string object from array of string at specific index
Parameters:
arr : string array
index : index at which string object need to be removed
Returns: string
delete(arr, index)
remove color object from array of color at specific index
Parameters:
arr : color array
index : index at which color object need to be removed
Returns: color
delete(arr, index)
remove line object from array of lines at specific index and deletes the line
Parameters:
arr : line array
index : index at which line object need to be removed and deleted
Returns: void
delete(arr, index)
remove label object from array of labels at specific index and deletes the label
Parameters:
arr : label array
index : index at which label object need to be removed and deleted
Returns: void
delete(arr, index)
remove box object from array of boxes at specific index and deletes the box
Parameters:
arr : box array
index : index at which box object need to be removed and deleted
Returns: void
delete(arr, index)
remove table object from array of tables at specific index and deletes the table
Parameters:
arr : table array
index : index at which table object need to be removed and deleted
Returns: void
delete(arr, index)
remove linefill object from array of linefills at specific index and deletes the linefill
Parameters:
arr : linefill array
index : index at which linefill object need to be removed and deleted
Returns: void
popr(arr)
remove last int object from array
Parameters:
arr : int array
Returns: int
popr(arr)
remove last float object from array
Parameters:
arr : float array
Returns: float
popr(arr)
remove last bool object from array
Parameters:
arr : bool array
Returns: bool
popr(arr)
remove last string object from array
Parameters:
arr : string array
Returns: string
popr(arr)
remove last color object from array
Parameters:
arr : color array
Returns: color
popr(arr)
remove and delete last line object from array
Parameters:
arr : line array
Returns: void
popr(arr)
remove and delete last label object from array
Parameters:
arr : label array
Returns: void
popr(arr)
remove and delete last box object from array
Parameters:
arr : box array
Returns: void
popr(arr)
remove and delete last table object from array
Parameters:
arr : table array
Returns: void
popr(arr)
remove and delete last linefill object from array
Parameters:
arr : linefill array
Returns: void
shiftr(arr)
remove first int object from array
Parameters:
arr : int array
Returns: int
shiftr(arr)
remove first float object from array
Parameters:
arr : float array
Returns: float
shiftr(arr)
remove first bool object from array
Parameters:
arr : bool array
Returns: bool
shiftr(arr)
remove first string object from array
Parameters:
arr : string array
Returns: string
shiftr(arr)
remove first color object from array
Parameters:
arr : color array
Returns: color
shiftr(arr)
remove and delete first line object from array
Parameters:
arr : line array
Returns: void
shiftr(arr)
remove and delete first label object from array
Parameters:
arr : label array
Returns: void
shiftr(arr)
remove and delete first box object from array
Parameters:
arr : box array
Returns: void
shiftr(arr)
remove and delete first table object from array
Parameters:
arr : table array
Returns: void
shiftr(arr)
remove and delete first linefill object from array
Parameters:
arr : linefill array
Returns: void
push(arr, val, maxItems)
add int to the end of an array with max items cap. Objects are removed from start to maintain max items cap
Parameters:
arr : int array
val : int object to be pushed
maxItems : max number of items array can hold
Returns: int
push(arr, val, maxItems)
add float to the end of an array with max items cap. Objects are removed from start to maintain max items cap
Parameters:
arr : float array
val : float object to be pushed
maxItems : max number of items array can hold
Returns: float
push(arr, val, maxItems)
add bool to the end of an array with max items cap. Objects are removed from start to maintain max items cap
Parameters:
arr : bool array
val : bool object to be pushed
maxItems : max number of items array can hold
Returns: bool
push(arr, val, maxItems)
add string to the end of an array with max items cap. Objects are removed from start to maintain max items cap
Parameters:
arr : string array
val : string object to be pushed
maxItems : max number of items array can hold
Returns: string
push(arr, val, maxItems)
add color to the end of an array with max items cap. Objects are removed from start to maintain max items cap
Parameters:
arr : color array
val : color object to be pushed
maxItems : max number of items array can hold
Returns: color
push(arr, val, maxItems)
add line to the end of an array with max items cap. Objects are removed and deleted from start to maintain max items cap
Parameters:
arr : line array
val : line object to be pushed
maxItems : max number of items array can hold
Returns: line
push(arr, val, maxItems)
add label to the end of an array with max items cap. Objects are removed and deleted from start to maintain max items cap
Parameters:
arr : label array
val : label object to be pushed
maxItems : max number of items array can hold
Returns: label
push(arr, val, maxItems)
add box to the end of an array with max items cap. Objects are removed and deleted from start to maintain max items cap
Parameters:
arr : box array
val : box object to be pushed
maxItems : max number of items array can hold
Returns: box
push(arr, val, maxItems)
add table to the end of an array with max items cap. Objects are removed and deleted from start to maintain max items cap
Parameters:
arr : table array
val : table object to be pushed
maxItems : max number of items array can hold
Returns: table
push(arr, val, maxItems)
add linefill to the end of an array with max items cap. Objects are removed and deleted from start to maintain max items cap
Parameters:
arr : linefill array
val : linefill object to be pushed
maxItems : max number of items array can hold
Returns: linefill
unshift(arr, val, maxItems)
add int to the beginning of an array with max items cap. Objects are removed from end to maintain max items cap
Parameters:
arr : int array
val : int object to be unshift
maxItems : max number of items array can hold
Returns: int
unshift(arr, val, maxItems)
add float to the beginning of an array with max items cap. Objects are removed from end to maintain max items cap
Parameters:
arr : float array
val : float object to be unshift
maxItems : max number of items array can hold
Returns: float
unshift(arr, val, maxItems)
add bool to the beginning of an array with max items cap. Objects are removed from end to maintain max items cap
Parameters:
arr : bool array
val : bool object to be unshift
maxItems : max number of items array can hold
Returns: bool
unshift(arr, val, maxItems)
add string to the beginning of an array with max items cap. Objects are removed from end to maintain max items cap
Parameters:
arr : string array
val : string object to be unshift
maxItems : max number of items array can hold
Returns: string
unshift(arr, val, maxItems)
add color to the beginning of an array with max items cap. Objects are removed from end to maintain max items cap
Parameters:
arr : color array
val : color object to be unshift
maxItems : max number of items array can hold
Returns: color
unshift(arr, val, maxItems)
add line to the beginning of an array with max items cap. Objects are removed and deleted from end to maintain max items cap
Parameters:
arr : line array
val : line object to be unshift
maxItems : max number of items array can hold
Returns: line
unshift(arr, val, maxItems)
add label to the beginning of an array with max items cap. Objects are removed and deleted from end to maintain max items cap
Parameters:
arr : label array
val : label object to be unshift
maxItems : max number of items array can hold
Returns: label
unshift(arr, val, maxItems)
add box to the beginning of an array with max items cap. Objects are removed and deleted from end to maintain max items cap
Parameters:
arr : box array
val : box object to be unshift
maxItems : max number of items array can hold
Returns: box
unshift(arr, val, maxItems)
add table to the beginning of an array with max items cap. Objects are removed and deleted from end to maintain max items cap
Parameters:
arr : table array
val : table object to be unshift
maxItems : max number of items array can hold
Returns: table
unshift(arr, val, maxItems)
add linefill to the beginning of an array with max items cap. Objects are removed and deleted from end to maintain max items cap
Parameters:
arr : linefill array
val : linefill object to be unshift
maxItems : max number of items array can hold
Returns: linefill
flush(arr)
remove all int objects in an array
Parameters:
arr : int array
Returns: int
flush(arr)
remove all float objects in an array
Parameters:
arr : float array
Returns: float
flush(arr)
remove all bool objects in an array
Parameters:
arr : bool array
Returns: bool
flush(arr)
remove all string objects in an array
Parameters:
arr : string array
Returns: string
flush(arr)
remove all color objects in an array
Parameters:
arr : color array
Returns: color
flush(arr)
remove and delete all line objects in an array
Parameters:
arr : line array
Returns: line
flush(arr)
remove and delete all label objects in an array
Parameters:
arr : label array
Returns: label
flush(arr)
remove and delete all box objects in an array
Parameters:
arr : box array
Returns: box
flush(arr)
remove and delete all table objects in an array
Parameters:
arr : table array
Returns: table
flush(arr)
remove and delete all linefill objects in an array
Parameters:
arr : linefill array
Returns: linefill
Recursive Zigzag [Trendoscope]Here is an another outcome of Object Oriented Zigzag and Pattern Ecosystem of Libraries.
We already have another implementation of recursive zigzag which makes use of earlier library rzigzag . Here in this example, we make use of similar logic but leverage the new type and method based Zigzag system libraries to derive the indicator.
🎲 Design Overview
Similar to Recursive Auto Pitchfork, here too the indicator code is around 50 lines. Whereas most of the heavy lifting is done by the libraries.
🎲 Base Libraries
Base libraries are those which does not have any dependency. They form basic structures which are later used in other libraries. These libraries need to be crafted carefully so that minimal updates are done later on. Any updates on these libraries will impact all the dependent libraries and scripts.
🎯 Drawing
DrawingTypes - Defines basic drawing types Point, Line, Label, Box, Linefill and related property types.
DrawingMethods - All the methods or functionality surrounding Basic types are defined here.
🎲 Layer 1 Libraries
These are the libraries which has direct dependency on base libraries.
🎯 Zigzag
ZigzagTypes - Types required for defining Zigzag and Divergence
ZigzagMethods - Methods associated with Zigzag Type definitions.
🎲Indicator
Indicator draws zigzags based on given length. And then recursively derives next level zigzags based on previous levels. As per the utility, indicator is useful in several ways
Visualising price structure based on zigzag pivots - which in turn can help visualise patterns.
Ability to add any oscillator makes it easy to spot divergences with choice of indicators.
Programmers can use the derived values to build complex algorithms such as automatic pattern recognition.
🎯 Settings
Settings are explained via tooltips. These are very much straight forward and directly related to zigzag, oscillators and divergence.
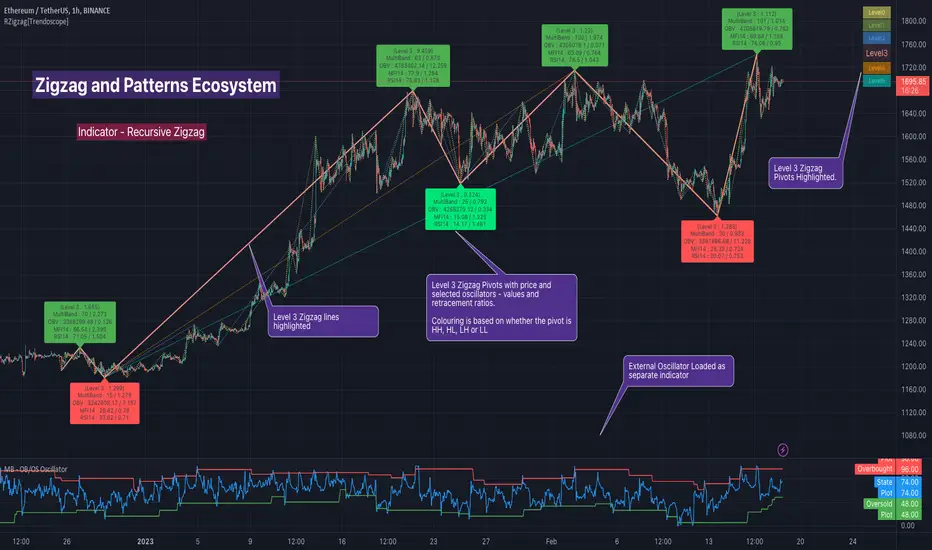
Recursive Auto-Pitchfork [Trendoscope]"Say Hi" to object oriented programming with Pinescript using types and methods. This is the beginning of new era of Pinescript where we are moving from isolated scripts containing indicator and strategies to whole ecosystem of Object Oriented Programming with libraries of highly reusable components. Those who are familiar with programming would have already realised how big these improvements are and what it brings to the table.
With this script, I am not just providing an indicator for traders but also an introduction for programmers on how to design and build object oriented components in Pinescript using types and methods. Big thanks to Tradingview and Pine development team for making this happen. We look forward for many such gifts in the future :)
🎲 Architecture
As mentioned before, we are not just building an indicator here. But, an ecosystem of components. Using Types and Methods we can visualise libraries as Classes. Thus, we can build an ecosystem of libraries in layered approach to enhance effective code reusability.
Generic architecture can be visualised as below
Coming to the specific case of Auto Pitchfork indicator, the indicator code is less than 50 lines for logic and around 100 lines of inputs. But, most of the heavy-lifting is done by the libraries underneath. Here is a snapshot of related libraries and how they are connected.
All libraries are divided into two portions.
Types - Contains only type definitions
Methods - Contains only method definitions related to the types defined in the Types library
Together, these libraries can be visualised as Class. Methods are defined in such a way all exported methods are related to Types and no other functions or features are defined. If we need further functionality which does not depend on the types, we need to do this via some other library and use them here. Similarly, we should not define any methods related to these types in other libraries.
Reason for splitting the libraries to types and methods is to enable updating methods without disturbing types. Since libraries create interdependencies due to versioning, it is best if we do less updates on the type definitions. Splitting the two enables adding more features while keeping the type definition version intact.
🎲 Base Libraries
Base libraries are those which does not have any dependency. They form basic structures which are later used in other libraries. These libraries need to be crafted carefully so that minimal updates are done later on. Any updates on these libraries will impact all the dependent libraries and scripts.
🎯 Drawing
DrawingTypes - Defines basic drawing types Point, Line, Label, Box, Linefill and related property types.
DrawingMethods - All the methods or functionality surrounding Basic types are defined here.
🎲 Layer 1 Libraries
These are the libraries which has direct dependency on base libraries.
🎯 Zigzag
ZigzagTypes - Types required for defining Zigzag and Divergence
ZigzagMethods - Methods associated with Zigzag Type definitions.
🎯Pitchfork
PitchforkTypes - Basic and Drawing Types for Pitchfork objects
PitchforkMethods - Methods associated with Pitchfork type definitions
🎲 Indicator and Settings
Indicator draws pitchfork based on recursive zigzag configurations. Recursive zigzag is derived with following logic:
Base level zigzag is calculated with regular zigzag algorithm with given length and depth
Next level zigzag is calculated based on base zigzag. And we recursively calculate higher level zigzags until we are left with 4 or less pivots or when no further reduction is possible
On every level of zigzag, we then check the last 3 pivots and draw pitchfork based on the retracement ratio.
Indicator settings are summarised in the tooltips and are as below.
Finally, big thanks to my partner @CryptoArch_ for bringing up the topic of pitchfork for our next development.
PitchforkMethodsLibrary "PitchforkMethods"
Methods associated with Pitchfork and Pitchfork Drawing. Depends on the library PitchforkTypes for Pitchfork/PitchforkDrawing objects which in turn use DrawingTypes for basic objects Point/Line/LineProperties. Also depends on DrawingMethods for related methods
tostring(this)
Converts PitchforkTypes/Fork object to string representation
Parameters:
this : PitchforkTypes/Fork object
Returns: string representation of PitchforkTypes/Fork
tostring(this)
Converts Array of PitchforkTypes/Fork object to string representation
Parameters:
this : Array of PitchforkTypes/Fork object
Returns: string representation of PitchforkTypes/Fork array
tostring(this, sortKeys, sortOrder)
Converts PitchforkTypes/PitchforkProperties object to string representation
Parameters:
this : PitchforkTypes/PitchforkProperties object
sortKeys : If set to true, string output is sorted by keys.
sortOrder : Applicable only if sortKeys is set to true. Positive number will sort them in ascending order whreas negative numer will sort them in descending order. Passing 0 will not sort the keys
Returns: string representation of PitchforkTypes/PitchforkProperties
tostring(this, sortKeys, sortOrder)
Converts PitchforkTypes/PitchforkDrawingProperties object to string representation
Parameters:
this : PitchforkTypes/PitchforkDrawingProperties object
sortKeys : If set to true, string output is sorted by keys.
sortOrder : Applicable only if sortKeys is set to true. Positive number will sort them in ascending order whreas negative numer will sort them in descending order. Passing 0 will not sort the keys
Returns: string representation of PitchforkTypes/PitchforkDrawingProperties
tostring(this, sortKeys, sortOrder)
Converts PitchforkTypes/Pitchfork object to string representation
Parameters:
this : PitchforkTypes/Pitchfork object
sortKeys : If set to true, string output is sorted by keys.
sortOrder : Applicable only if sortKeys is set to true. Positive number will sort them in ascending order whreas negative numer will sort them in descending order. Passing 0 will not sort the keys
Returns: string representation of PitchforkTypes/Pitchfork
createDrawing(this)
Creates PitchforkTypes/PitchforkDrawing from PitchforkTypes/Pitchfork object
Parameters:
this : PitchforkTypes/Pitchfork object
Returns: PitchforkTypes/PitchforkDrawing object created
createDrawing(this)
Creates PitchforkTypes/PitchforkDrawing array from PitchforkTypes/Pitchfork array of objects
Parameters:
this : array of PitchforkTypes/Pitchfork object
Returns: array of PitchforkTypes/PitchforkDrawing object created
draw(this)
draws from PitchforkTypes/PitchforkDrawing object
Parameters:
this : PitchforkTypes/PitchforkDrawing object
Returns: PitchforkTypes/PitchforkDrawing object drawn
delete(this)
deletes PitchforkTypes/PitchforkDrawing object
Parameters:
this : PitchforkTypes/PitchforkDrawing object
Returns: PitchforkTypes/PitchforkDrawing object deleted
delete(this)
deletes underlying drawing of PitchforkTypes/Pitchfork object
Parameters:
this : PitchforkTypes/Pitchfork object
Returns: PitchforkTypes/Pitchfork object deleted
delete(this)
deletes array of PitchforkTypes/PitchforkDrawing objects
Parameters:
this : Array of PitchforkTypes/PitchforkDrawing object
Returns: Array of PitchforkTypes/PitchforkDrawing object deleted
delete(this)
deletes underlying drawing in array of PitchforkTypes/Pitchfork objects
Parameters:
this : Array of PitchforkTypes/Pitchfork object
Returns: Array of PitchforkTypes/Pitchfork object deleted
clear(this)
deletes array of PitchforkTypes/PitchforkDrawing objects and clears the array
Parameters:
this : Array of PitchforkTypes/PitchforkDrawing object
Returns: void
clear(this)
deletes array of PitchforkTypes/Pitchfork objects and clears the array
Parameters:
this : Array of Pitchfork/Pitchfork object
Returns: void
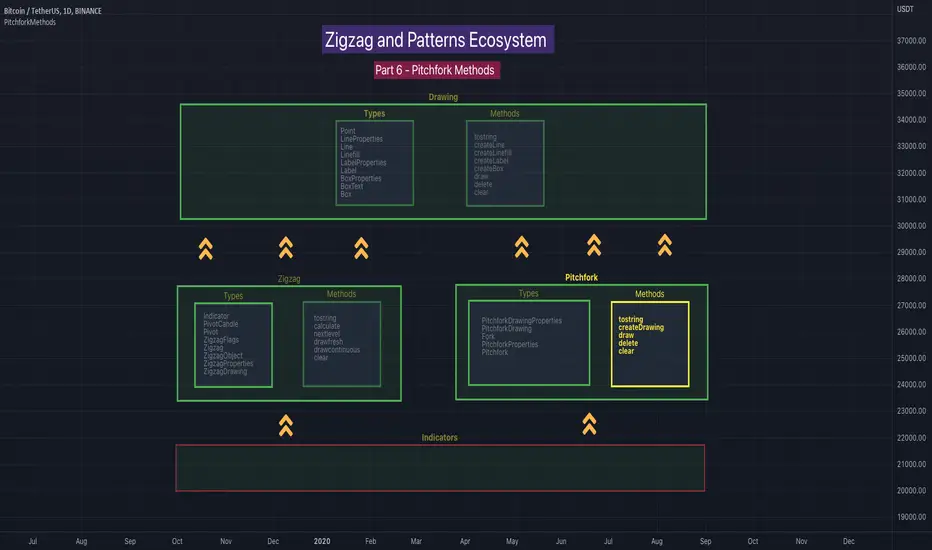
PitchforkTypesLibrary "PitchforkTypes"
User Defined Types to be used for Pitchfork and Drawing elements of Pitchfork. Depends on DrawingTypes for Point, Line, and LineProperties objects
PitchforkDrawingProperties
Pitchfork Drawing Properties object
Fields:
extend : If set to true, forks are extended towards right. Default is true
fill : Fill forklines with transparent color. Default is true
fillTransparency : Transparency at which fills are made. Only considered when fill is set. Default is 80
forceCommonColor : Force use of common color for forks and fills. Default is false
commonColor : common fill color. Used only if ratio specific fill colors are not available or if forceCommonColor is set to true.
PitchforkDrawing
Pitchfork drawing components
Fields:
medianLine : Median line of the pitchfork
baseLine : Base line of the pitchfork
forkLines : fork lines of the pitchfork
linefills : Linefills between forks
Fork
Fork object property
Fields:
ratio : Fork ratio
forkColor : color of fork. Default is blue
include : flag to include the fork in drawing. Default is true
PitchforkProperties
Pitchfork Properties
Fields:
forks : Array of Fork objects
type : Pitchfork type. Supported values are "regular", "schiff", "mschiff", Default is regular
inside : Flag to identify if to draw inside fork. If set to true, inside fork will be drawn
Pitchfork
Pitchfork object
Fields:
a : Pivot Point A of pitchfork
b : Pivot Point B of pitchfork
c : Pivot Point C of pitchfork
properties : PitchforkProperties object which determines type and composition of pitchfork
dProperties : Drawing properties for pitchfork
lProperties : Common line properties for Pitchfork lines
drawing : PitchforkDrawing object
