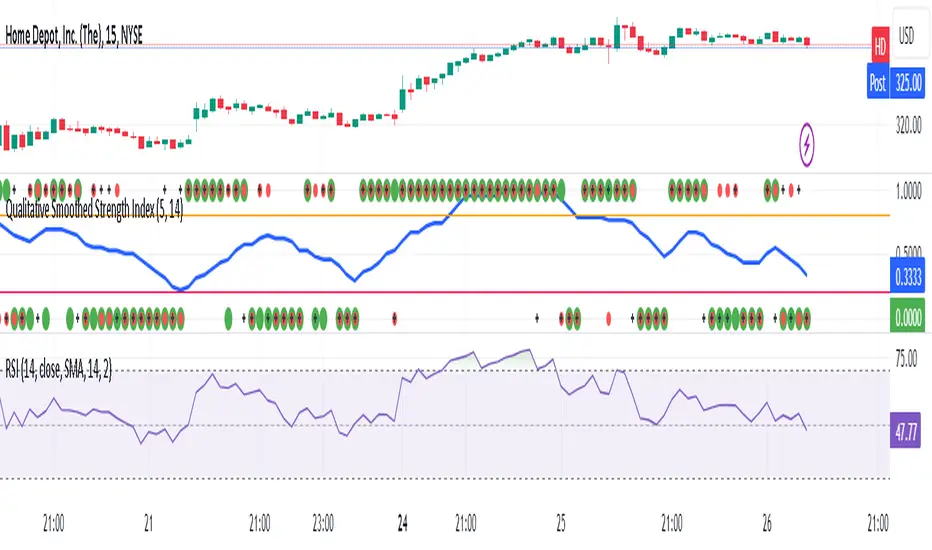
Wick Detection (1 and 0) - AYNETDetailed Scientific Explanation
1. Wick Detection Logic
Definition of a Wick:
A wick, also known as a shadow, represents the price action outside the range of a candlestick's body (the region between open and close).
Upper Wick: Occurs when the high value exceeds the greater of open and close.
Lower Wick: Occurs when the low value is lower than the smaller of open and close.
Upper Wick Detection:
pinescript
Kodu kopyala
bool has_upper_wick = high > math.max(open, close)
This checks if the high price of the candle is greater than the maximum of the open and close prices. If true, an upper wick exists.
Lower Wick Detection:
pinescript
Kodu kopyala
bool has_lower_wick = low < math.min(open, close)
This checks if the low price of the candle is less than the minimum of the open and close prices. If true, a lower wick exists.
2. Binary Representation
The presence of a wick is encoded as a binary value for simplicity and computational analysis:
Upper Wick: Represented as 1 if present, otherwise 0.
pinescript
Kodu kopyala
float upper_wick_binary = has_upper_wick ? 1 : 0
Lower Wick: Represented as 1 if present, otherwise 0. This value is inverted (-1) for visualization purposes.
pinescript
Kodu kopyala
float lower_wick_binary = has_lower_wick ? 1 : 0
3. Visualization with Histograms
The plot function is used to create histograms for visualizing the binary wick data:
Upper Wicks: Plotted as positive values with green columns:
pinescript
Kodu kopyala
plot(upper_wick_binary, title="Upper Wick", color=color.new(color.green, 0), style=plot.style_columns, linewidth=2)
Lower Wicks: Plotted as negative values with red columns:
pinescript
Kodu kopyala
plot(lower_wick_binary * -1, title="Lower Wick", color=color.new(color.red, 0), style=plot.style_columns, linewidth=2)
Features and Applications
1. Wick Visualization:
Upper wicks are displayed as positive green columns.
Lower wicks are displayed as negative red columns.
This provides a clear visual representation of wick presence in historical data.
2. Technical Analysis:
Wick formations often indicate market sentiment:
Upper Wicks: Sellers pushed the price lower after buyers drove it higher, signaling rejection at the top.
Lower Wicks: Buyers pushed the price higher after sellers drove it lower, signaling rejection at the bottom.
3. Signal Generation:
Traders can use wick detection to build strategies, such as identifying key price levels or market reversals.
Enhancements and Future Improvements
1. Wick Length Measurement
Instead of binary detection, measure the actual length of the wick:
pinescript
Kodu kopyala
float upper_wick_length = high - math.max(open, close)
float lower_wick_length = math.min(open, close) - low
This approach allows for thresholds to identify significant wicks:
pinescript
Kodu kopyala
bool significant_upper_wick = upper_wick_length > 10 // For wicks longer than 10 units.
bool significant_lower_wick = lower_wick_length > 10
2. Alerts for Long Wicks
Trigger alerts when significant wicks are detected:
pinescript
Kodu kopyala
alertcondition(significant_upper_wick, title="Long Upper Wick", message="A significant upper wick has been detected.")
alertcondition(significant_lower_wick, title="Long Lower Wick", message="A significant lower wick has been detected.")
3. Combined Wick Analysis
Analyze both upper and lower wicks to assess volatility:
pinescript
Kodu kopyala
float total_wick_length = upper_wick_length + lower_wick_length
bool high_volatility = total_wick_length > 20 // Combined wick length exceeds 20 units.
Conclusion
This script provides a compact and computationally efficient way to detect candlestick wicks and represent them as binary data. By visualizing the data with histograms, traders can easily identify wick formations and use them for technical analysis, signal generation, and volatility assessment. The approach can be extended further to measure wick length, detect significant wicks, and integrate these insights into automated trading systems.
Pine Script®指標