Strings
Introduction
Pine Script® strings are immutable values containing sequences of up to 40,960 encoded characters, such as letters, digits, symbols, spaces, control characters, or other Unicode characters and code points. Strings allow scripts to represent a wide range of data as character patterns and human-readable text.
Pine scripts use strings for several purposes, such as defining titles, expressing symbol and timeframe information, setting the contexts of data requests, creating alert and debug messages, and displaying text on the chart. The specialized functions in the str.* namespace provide convenient ways to construct strings, create modified copies of other strings, and inspect or extract substrings.
This page explains how Pine strings work, and how to construct, inspect, and modify strings using the available str.*() functions.
Literal strings
Literal strings in Pine are character sequences enclosed by two ASCII quotation marks (") or apostrophes ('). For example, this code snippet declares two variables with equivalent literal strings containing the text Hello world!:
The " or ' enclosing delimiters in a literal string definition are not parts of the specified character sequence. They only mark the sequence’s start and end boundaries in the code. These characters do not appear in outputs of Pine Logs or drawing objects that display “string” values.
This example calls the log.info() function on the first bar to display the contents of the literal value "Hello world!" in the Pine Logs pane. The message in the pane displays the Hello world! text only, without the " characters:

Note that:
- The script also uses a literal string to define the
titleargument of the indicator() declaration statement. - Only the
"and'ASCII characters are valid enclosing delimiters for literal strings. Other Unicode characters, such as U+FF02 (Fullwidth Quotation Mark), are not allowed as enclosing delimiters. - The timestamp in square brackets (
[and]) at the start of the logged message is an automatic prefix showing the log’s time in the chart’s time zone. For more information, refer to the Pine Logs section of the Debugging page.
Escape sequences
The backslash character (\), also known as the Reverse Solidus in Unicode (U+005C), is an escape character in Pine strings. This character forms an escape sequence when it precedes another character, signaling that the following character has a potentially different meaning than usual.
Characters with a special meaning in “string” value definitions, such as quotation marks and backslashes, become literal characters when prefixed by a backslash (e.g., \\ includes a single \ in the character sequence).
This simple script declares a variable with an assigned literal “string” value enclosed in apostrophes (') and displays the value’s contents in the Pine Logs pane. It uses the \ character to escape an extra apostrophe and another backslash, making them literal characters in the displayed text:
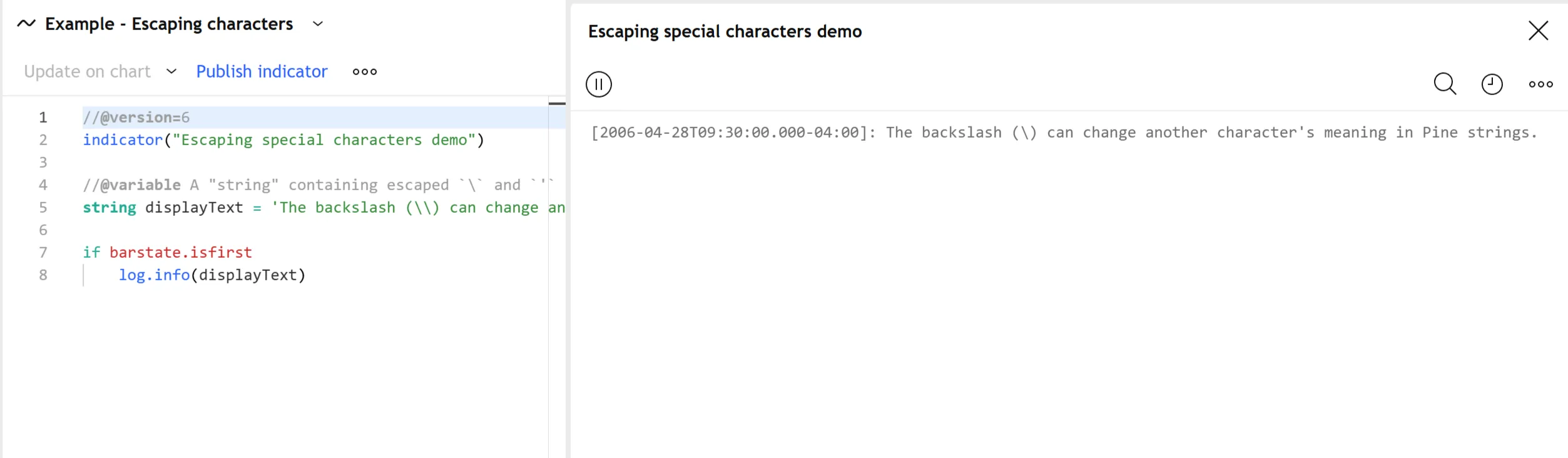
Note that:
- This example must prefix the
'character with a backslash in the string’s sequence because it also uses that character to mark its start and end boundaries. Without the backslash, it causes a compilation error. The script does not need to escape the apostrophe if we change the literal string’s enclosing characters to quotation marks (").
The ASCII characters n and t usually have a literal meaning in Pine strings. However, when prefixed by the backslash character, they form escape sequences representing control characters. The \n sequence represents the newline character (U+000A), a line terminator for multiline text. The \t sequence represents the horizontal tab character (U+0009), which is helpful for indentation.
The script below creates a “string” value with multiline text on a single line of code, which it displays in a label on the last historical bar. The defined value contains several \n and \t escape sequences to include line terminators and tab spaces in the displayed text:

Note that:
- The “string” value also includes
\before theTcharacter. However, that character still appears literally in the displayed text. If a backslash applied to a character does not form a supported escape sequence, the character’s meaning does not change.
Concatenation
The + and += operators signify concatenation when the operands are strings. A concatenation operation appends the second operand’s character sequence to the first operand’s sequence to form a new, combined “string” value.
For example, this script declares a concatString variable that holds the result of a concatenation operation. After declaring the variable, it uses the += operator to concatenate additional strings and reassign the variable’s value. Then, the script calls log.info() to show the result in the Pine Logs pane:
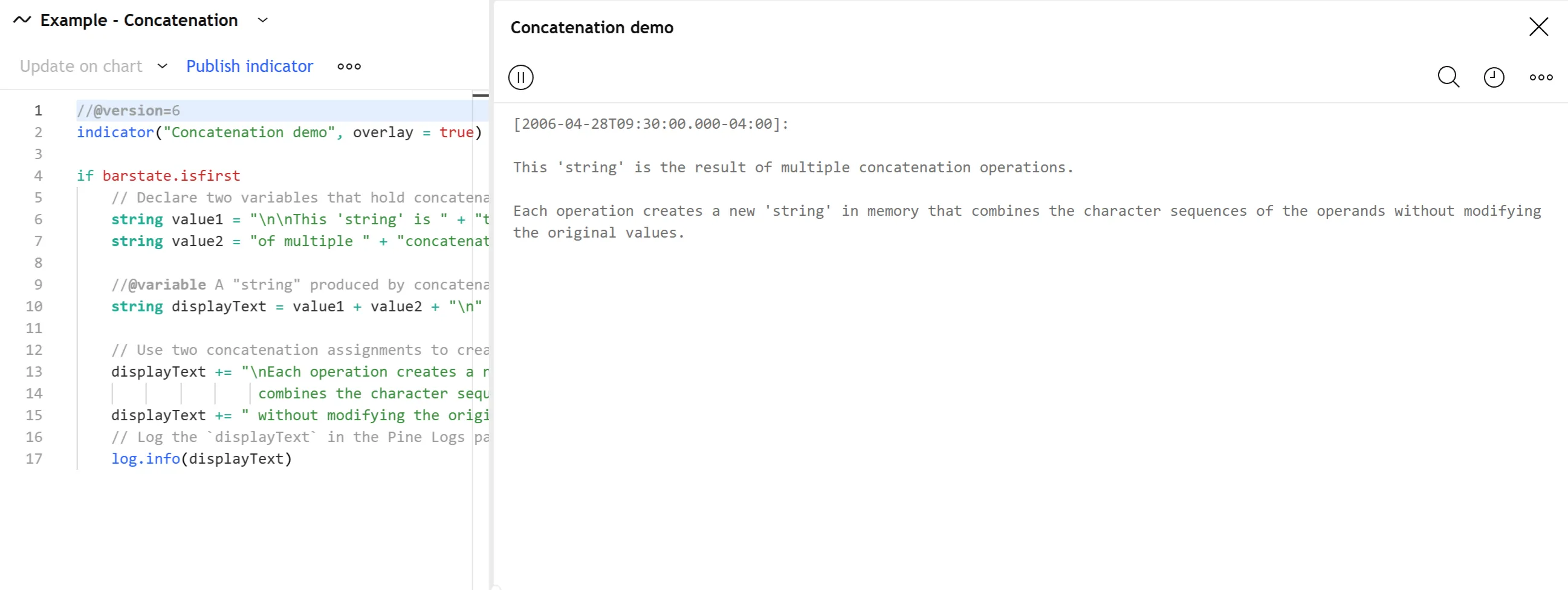
Note that:
- Strings are immutable and cannot change. Therefore, every concatenation operation creates a new “string” value in memory. The operation does not modify either “string” operand directly.
- Another, more advanced way to combine strings is to collect them inside an array and use the array.join() function. For more information, see the Joining section of the Arrays page.
- In many cases, programmers can efficiently create formatted strings with str.format() instead of combining individual strings with concatenation or joining. See the Formatting strings section to learn more.
String conversion and formatting
Programmers can use strings to represent data of virtually any type as human-readable character sequences. Converting data to strings allows scripts to perform many helpful tasks, including:
- Displaying dynamic prices and calculations as text inside labels, tables, or boxes.
- Creating alert messages containing realtime market and indicator information.
- Logging debug messages containing calculated script information in the Pine Logs pane.
- Performing custom calculations and logic, such as constructing symbol or timeframe strings for data requests.
Converting values to strings
The simplest way to convert data to strings is to call the str.tostring() function. The function can represent values of several types as strings, based on predefined or custom formats. It has the following two signatures:
str.tostring(value) → stringstr.tostring(value, format) → stringThe function’s value parameter accepts any “int”, “float”, “bool”, or “string” value; the reference of an array or matrix containing values of these types; or a member of an enum type.
For example, this line of code creates a string representing the “float” value 123.456, with default formatting. The result is usable in “string” operations and any script outputs that display dynamic text, such as labels and tables:
The str.tostring() function’s format parameter determines the numeric format for converted “int” and “float” values, arrays, and matrices. It can use one of the following format.* constants: format.mintick, format.percent, or format.volume. Alternatively, programmers can use strings containing # (number sign), 0 (zero), . (period), , (comma), and % (percent sign) tokens for customized formatting patterns with specific decimal precision. The default numeric format is "#.########", which rounds fractional digits to eight decimal places without trailing zeros.
The script below uses the str.tostring() function to convert numeric values, a “bool” value, arrays, and a matrix into strings and displays the results in a table on the last bar. The str.tostring() calls that convert numeric values and collections contain different format arguments to demonstrate how various formatting patterns affect the results:
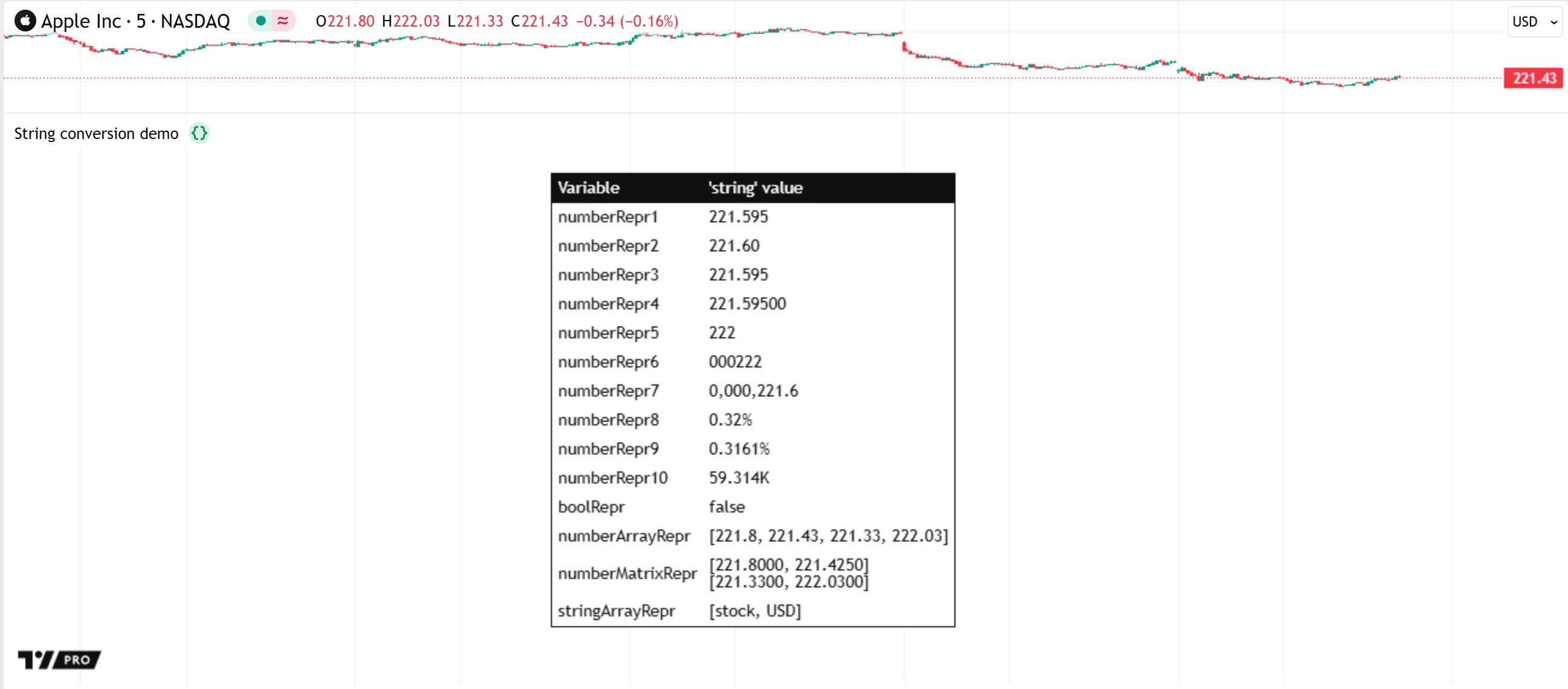
Note that:
- The
#and0tokens control the digits in the represented numbers in a similar way, but with different behaviors for leading and trailing zeros, as shown above. The0token always includes a digit at the specified decimal place, even for a leading or trailing zero, whereas the#token allows a leading or trailing digit only if it is nonzero. - The
formatargument requires a#or0token for each fractional digit in a converted number. These tokens are optional for extra whole digits, because str.tostring() includes the necessary digits automatically. - A single
,token adds repeated comma separation to whole digits. In the str.tostring() call with the format"0000,000.##", the token specifies that the result includes a dividing comma for every set of three digits to the left of the decimal point. - When the
%token is at the end of the formatting string, the representation multiplies numbers by 100 to express them as percentages, as shown by the example that uses"#.####%".
Formatting strings
The str.format() function can combine multiple “int”, “float”, “bool”, “string”, or array arguments into one output string in a specified format. Using this function is a simpler alternative to creating multiple separate strings and combining them with repeated concatenation operations. Below is the function’s signature:
str.format(formatString, arg0, arg1, ...) → stringThe formatString parameter accepts a “string” value that defines the format of the returned string, where the placeholders in curly brackets ({}) refer to the function call’s additional arguments. The placeholder "{0}" represents the first additional argument arg0, "{1}" represents arg1, and so on. The function replaces each placeholder in the formatString with a string representation of the corresponding argument. For instance, the call str.format("The timeframe multiplier is {0}", timeframe.multiplier) on a 1D chart returns "The timeframe multiplier is 1".
The following example constructs a formatted string containing various bar information, then displays the result in a label at the bar’s high. The str.format() call’s formatString argument includes placeholders for 10 values, where each placeholder’s number corresponds to one of the additional “string”, “bool”, “int”, or “float” arguments:
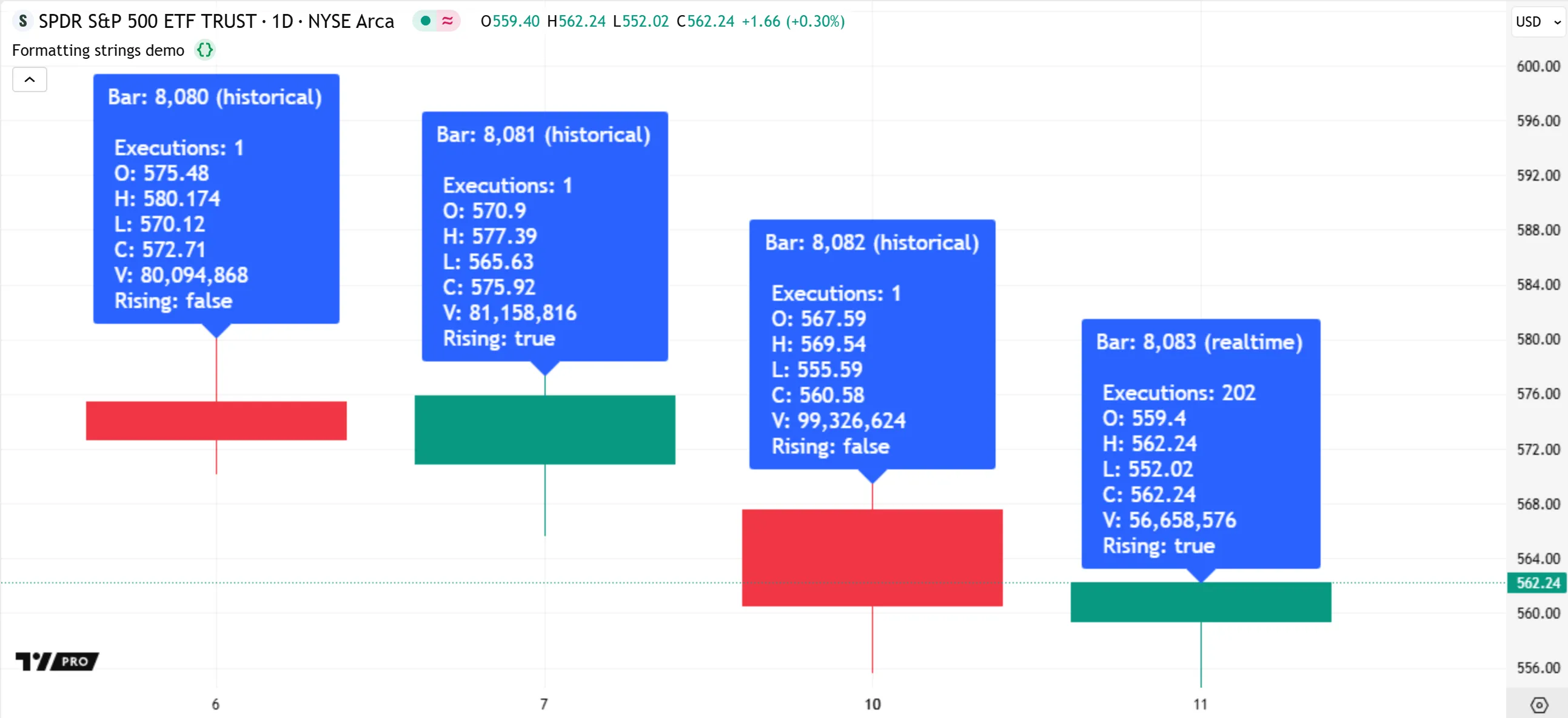
Note that:
- The
formatStringargument can use placeholders in any order and can repeat specific placeholders more than once. The format in this example uses{0}multiple times to insert the first argument ("\n\t") to create multiline text with indentation. - If a placeholder refers to a nonexistent argument, the formatted result treats that placeholder as a literal character sequence. For instance, a placeholder such as
{20}in theformatStringargument above includes those characters literally in the formatted result, because the str.format() call does not contain 21 additional arguments. - Non-quoted left curly brackets (
{) must have corresponding right curly brackets (}) inside formatting strings. If aformatStringcontains unbalanced curly brackets, it causes a runtime error.
It’s important to note that the apostrophe (') acts as a quote character inside formatting strings. When a formatting string contains a character sequence between two apostrophes, the formatted result includes that sequence directly, without treating the characters as placeholders or formatting tokens. This behavior applies even if the formatting string prefixes apostrophes with the backslash character (\). The enclosing apostrophes for a non-empty quoted sequence are not part of the formatted string. To include literal apostrophes in a str.format() call’s result, pass a “string” value containing the character as an extra argument, then use that argument’s placeholder in the specified formatString. Alternatively, use pairs of apostrophes with no characters between them directly in the formatString (e.g., '' adds a single ' character in the result).
The example below demonstrates how using apostrophes directly in formatting strings differs from inserting them via placeholders. The script uses the ' character directly in the str.format() call’s formatString to define a quoted sequence, and it uses the {1} placeholder to insert the character from an extra argument without creating a quoted sequence. The script displays the resulting formattedString value in a single-cell table on the first bar:

When a str.format() call contains “int” or “float” arguments, the placeholders for those arguments in the formatString can include the number modifier followed by a formatting pattern for customized numeric formats (e.g., "{0,number,#.000}").
The possible numeric formatting patterns are similar to those for the format parameter of str.tostring(). They can contain #, 0, and . tokens to specify decimal precision; use the , token for comma separation; and include % at the end for percentage conversion. Alternatively, a placeholder can use one of the following keywords that specify predefined formatting patterns: integer, currency, or percent.
The script below demonstrates how different numeric formats in a formatString placeholder affect the formatted representation of a “float” value. On the last bar, the script generates a pseudorandom value between 0 and 10000 with math.random(), uses several str.format() calls to format the value in different ways, and displays the results in a table:

Note that:
- In contrast to str.tostring(), the str.format() function does not directly support the preset formats defined by the
format.*constants (format.mintick, format.percent, and format.volume). To use those formats on numeric values in a formatted string, convert the values with str.tostring() first, then use the resulting strings in the str.format() call.
The str.format() function’s formatString also supports placeholders with the date or time modifier, which can format an “int” UNIX timestamp into a UTC date or time. For example, this line of code creates a string representing the current bar’s opening timestamp as a date and time in the ISO 8601 standard format:
However, str.format() cannot express dates and times in other time zones. It uses UTC+0 exclusively. The specialized str.format_time() function is more optimal for constructing date-time strings, because it can express dates and times in any time zone. See the Formatting dates and times section of the Time page to learn more about this function and the available formatting tokens.
Custom representations
All built-in functions that create “string” values to represent data support a limited subset of built-in types. They do not support “color” values or objects of most reference types (e.g., labels). Programmers can, however, use custom logic and formatting to create “string” representations of data that the str.tostring() or str.format() functions cannot express as strings directly.
For example, this script demonstrates two ways to represent a “color” value as a string based on its red, green, blue, and transparency components. The first method formats the color components directly. The second calculates and formats each component’s hexadecimal form. The script displays the results of both custom formats in a label on the last historical bar.
After creating the label object, the script also uses log.info() to create formatted text containing the label’s x, y, and text properties and display the result in the Pine Logs pane:
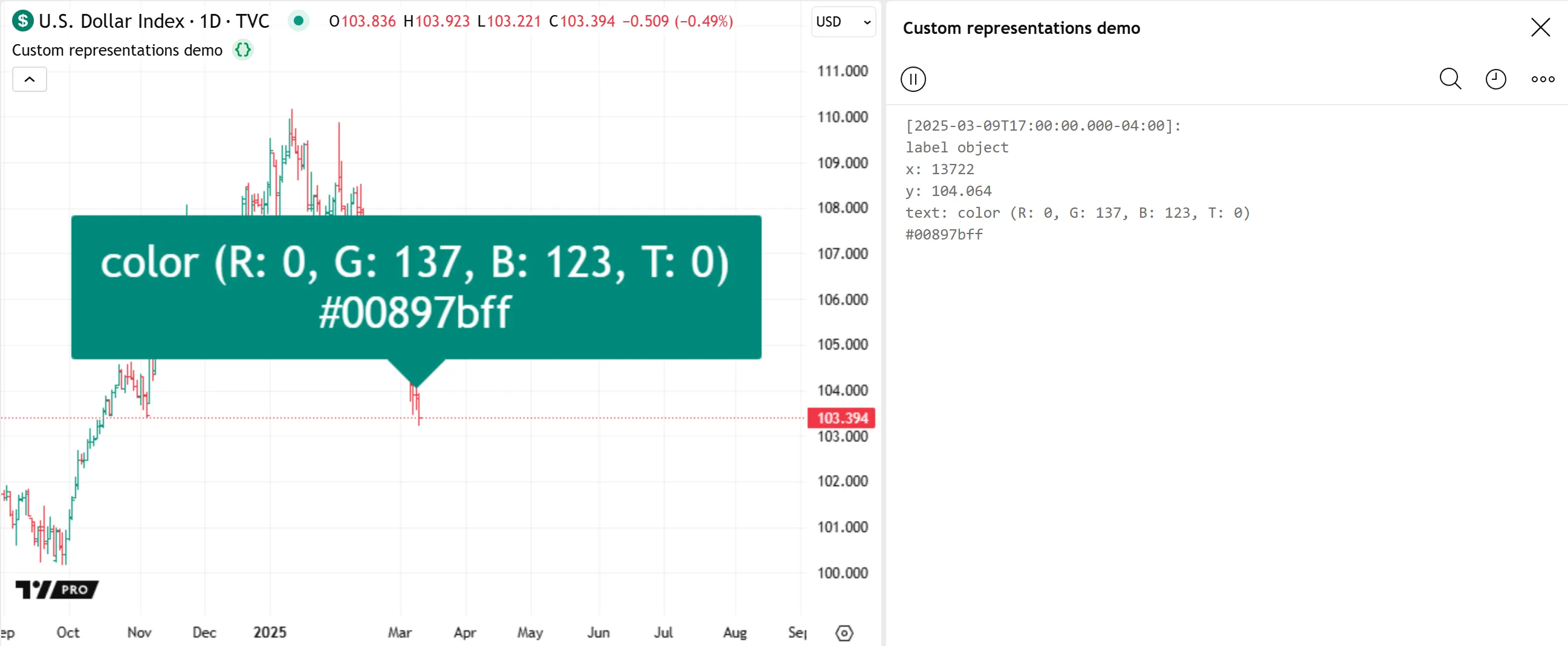
Note that:
- Not all special types have retrievable properties. For instance, scripts cannot retrieve information from polylines or tables. To create strings for these types, track the data used in their creation with separate variables, then format the values of those variables into strings.
- For an example of creating strings from the field values of user-defined types, see the Debugging objects of UDTs section of the Debugging page.
Modifying strings
Several str.*() functions provide simplified ways to modify the character sequence from a “string” value, including str.replace(), str.replace_all(), str.upper(), str.lower(), str.trim(), and str.repeat().
Programmers can use these functions to create copies of strings with replaced character sequences, modified letter cases, trimmed whitespaces, or repeated character patterns.
Replacing substrings
The str.replace() function searches a specified source string for the nth non-overlapping occurrence of a given substring, then returns a copy of the original string containing a specified replacement at that substring’s position.
The str.replace_all() function searches the source for every non-overlapping occurrence of the substring and replaces each one in its returned value.
Below are the functions’ signatures:
str.replace(source, target, replacement, occurrence) → stringstr.replace_all(source, target, replacement) → stringWhere:
sourceis the “string” value containing the substrings to replace with a specifiedreplacement.targetis the substring replaced by thereplacementin the returned copy. If thesourcevalue does not contain the substring, the function returns a copy of the value without modification.replacementis the substring inserted in place of the requiredtargetoccurrences in the result.- The
occurrenceparameter for str.replace() specifies which non-overlapping occurrence of thetargetis swapped for thereplacementin the result. The default value is 0, meaning the function replaces the first occurrence of thetarget. If the specified occurrence does not exist in thesourcevalue, the function returns a copy of the value without modification.
The following script demonstrates the effects of str.replace() and str.replace_all() calls on a string containing the sequence Hello world!. Additionally, it calls these functions to define the formatString value for a str.format() call, which formats all the replacement results into a single “string” value. The script displays the formatted text inside a label anchored to the latest bar’s opening time:

Note that:
- Each
str.replace*()call creates an independent, modified copy of the specifiedsourcevalue. Because each modification of theoriginalStringis assigned to a separate variable, each value does not contain changes from previousstr.replace*()calls. - The
str.replace*()functions can replace zero-width boundaries when thetargetis an empty string, as shown by theformatStringdeclaration. The str.replace_all() call inserts}\n{around every character in the literal string"012345".
Changing case
The str.upper() and str.lower() functions create a copy of a source string with all ASCII letter characters converted to uppercase or lowercase variants, providing a convenient alternative to replacing specific characters with several str.replace*() calls. The str.upper() function replaces all lowercase characters with uppercase characters, and str.lower() does the opposite. These are the functions’ signatures:
str.upper(source) → stringstr.lower(source) → stringThis simple example demonstrates how these functions affect strings with standard letter characters. The script declares an originalString variable to hold a literal string, uses str.upper() on that variable to create a copied string with all letters converted to uppercase, then calls str.lower() to make a copy with only lowercase characters. It logs all three strings in the Pine Logs pane on the first bar:
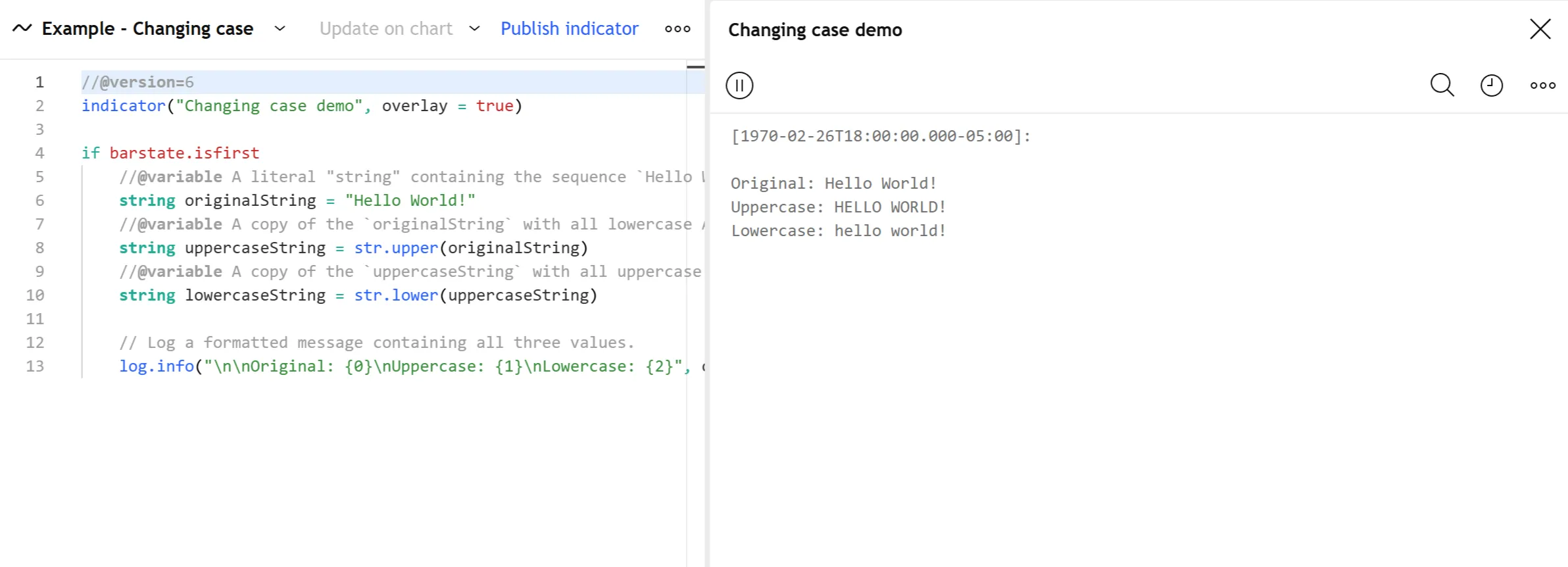
Note that these functions can only change the cases of ASCII letter characters. They cannot convert other Unicode letters outside the ASCII range. For example, this script attempts to create uppercase and lowercase versions of a “string” value containing “Mathematical Sans-Serif” Unicode characters using str.upper() and str.lower(). As shown below, both function calls return identical copies of the value:

Trimming whitespaces
The str.trim() function copies a source string and removes leading and trailing whitespace characters, including the standard space ( ), newline (\n), and tab space (\t). Below is the function’s signature:
str.trim(source) → stringThis simple example demonstrates the str.trim() function’s behavior. The script creates a literal string containing different types of whitespaces at the start and end of the character sequence. Then, it uses str.trim() to create a new “string” value with those characters removed. The script formats both values into a single string, then displays the result in a label on the last historical bar:

Note that:
- The str.trim() function removes only the ASCII whitespaces to the left of the first non-whitespace character and the right of the last non-whitespace character. It does not remove whitespaces between other characters.
- The formatting string in the str.format() call uses
\"to include quotation marks around theoriginalStringandtrimmedStringvalues in the displayed text. See the Escape sequences section above for more information.
The str.trim() function is particularly helpful when supplying calculated or input strings to built-in functions that process “string” arguments, because some function parameters require values without leading or trailing whitespaces.
The following example creates an array of timeframe strings by splitting the value of a text area input based on its comma characters. Within a loop, the script uses each element from the array in a time() call to retrieve an opening time, then concatenates a formatted date and time with the displayText.
Although each item listed in the default string represents a valid timeframe, the time() call causes a runtime error. The script splits the value only by its commas, resulting in a leading space in each timeframes element after the first, and the time() function does not allow whitespaces in its timeframe argument.
If the user enables the input to trim the input string (which is off by default), the script uses str.trim() to remove surrounding whitespaces from the time() call’s argument and prevent the formatting issue and the runtime error.

Repeating sequences
The str.repeat() function creates a “string” value that repeats a source string’s character sequence a specified number of times, providing a convenient way to construct strings with repetitive character patterns. Below is the function’s signature:
str.repeat(source, repeat, separator) → stringWhere:
sourceis the “string” value containing the character sequence to repeat in the result.repeatis an “int” value specifying the number of times the function repeats thesourcesequence. If the value is 0, the function returns an empty string.separatoris an optional “string” value containing a character sequence to insert between each repeated instance of thesourcesequence. The default value is an empty string, meaning the function repeats thesourcesequence without inserting additional characters.
The following script formats two numbers — the ohlc4 price and its Simple Moving Average — with a variable number of fractional digits. The minimum and maximum number of fractional digits are set by user inputs. The script uses a str.repeat() call to repeat 0 characters to create a pattern for the required digits, and another call that repeats # characters to create a pattern for the optional digits, which are displayed only if they are nonzero. The script then concatenates these patterns into one pattern and uses that in a str.format() call to format the two numbers.
The script calls log.info() to log the constructed formatString on the first bar, and it displays the formatted results for each bar using labels:

Note that:
- The apostrophe (
') in the str.format() call serves as a quote character, not a literal character. TheformatStringuses the apostrophe to quote curly brackets ({and}), treating them as literal characters instead of direct placeholder markers.
The example below demonstrates a more creative use of str.repeat(). This script generates an ASCII art representation of the Pine Script logo using alternating sequences of repeated . (period) and @ (at) characters. The user-defined makeLine() function calls str.repeat() seven times to create the repeated sequences, then formats their results into a single “string” value with a str.format() call. On the first bar, the script formats the results of several makeLine() calls into a multiline string and displays the result in a single-cell table in the chart’s top-right corner:
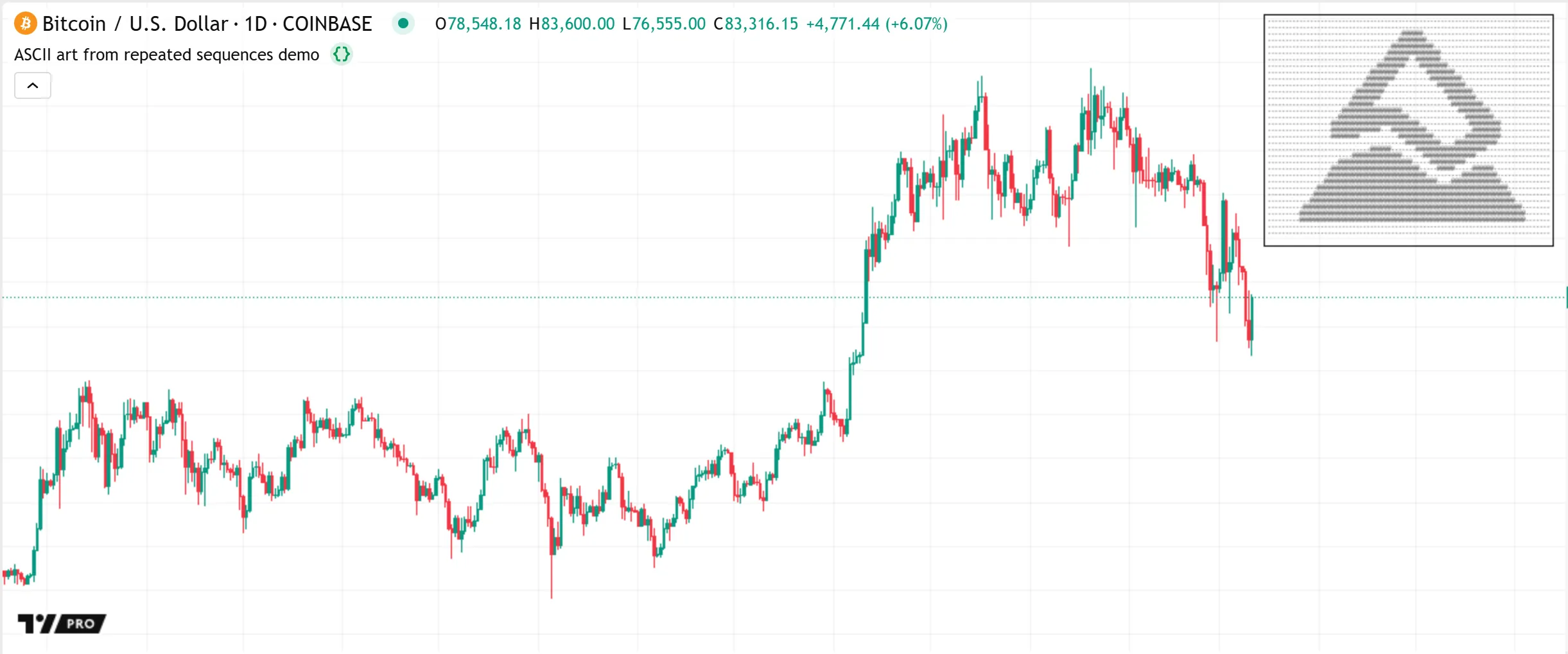
Note that:
- The table.cell() call uses text.align_left as the
text_halignargument and font.family_monospace as thetext_font_familyargument to align the text lines to the left with relatively uniform character width. - The formatted string from each
makeLine()call uses the\nescape sequence at the end to add a line terminator.
String inspection and extraction
Several built-in str.*() functions allow scripts to measure a “string” value, check for substrings and retrieve their positions, split a string into several substrings, and extract substrings based on positions or match patterns. These functions include str.length(), str.contains(), str.startswith(), str.endswith(), str.split(), str.pos(), str.substring(), and str.match().
The sections below explain these functions and some helpful techniques to use them effectively.
Counting characters and substrings
The str.length() function measures the length of a specified “string” value, returning an “int” value representing the number of characters in the argument’s character sequence. It has the following signature:
str.length(string) → intThis function detects every character within a “string” value’s sequence, even those that are hard to see, such as leading or repeated spaces, line terminators, and invisible characters like U+200B (Zero Width Space).
For example, this simple script declares two variables with assigned literal strings and measures their length. The script creates the first “string” value using Em Space characters (U+2003), and creates the second using En Space characters (U+2002) instead. It measures the length of both strings with str.length(), creates modified strings with the "__" parts replaced by the length values, then concatenates the results for display in a single-cell table.
Although the two strings look identical in the output, their lengths differ because one En Space is equivalent to half the width of one Em Space, meaning the second string must include two En Spaces between each word to match the width of each Em Space in the first string:

Note that:
- A simple way to verify the added characters is to split the
testString2value into an array of substrings with str.split() and inspect the array’s elements. See the Splitting strings section to learn more about this function.
The str.length() function is also useful for counting the number of substrings of any size contained within a string’s sequence, which is helpful information when replacing substrings or performing custom routines that depend on recurring characters.
The following example defines a countSubstrings() function, which uses str.replace_all() and str.length() to count the number of times a target substring occurs within a specified source value. The function creates a modified copy of the source with all instances of the target removed, then calls str.length() to measure the length of each separate string. It calculates the number of target occurrences by dividing the length difference in the original and reduced strings by the length of the substring.
The script uses str.repeat() to generate a “string” value that repeats the sequence aba a pseudorandom number of times with baab inserted between each instance, then counts all occurrences of the substring ab in the result with a countSubstrings() call. It then displays a formatted message containing the repeated sequence and the total number of ab substrings in the Pine Logs pane:
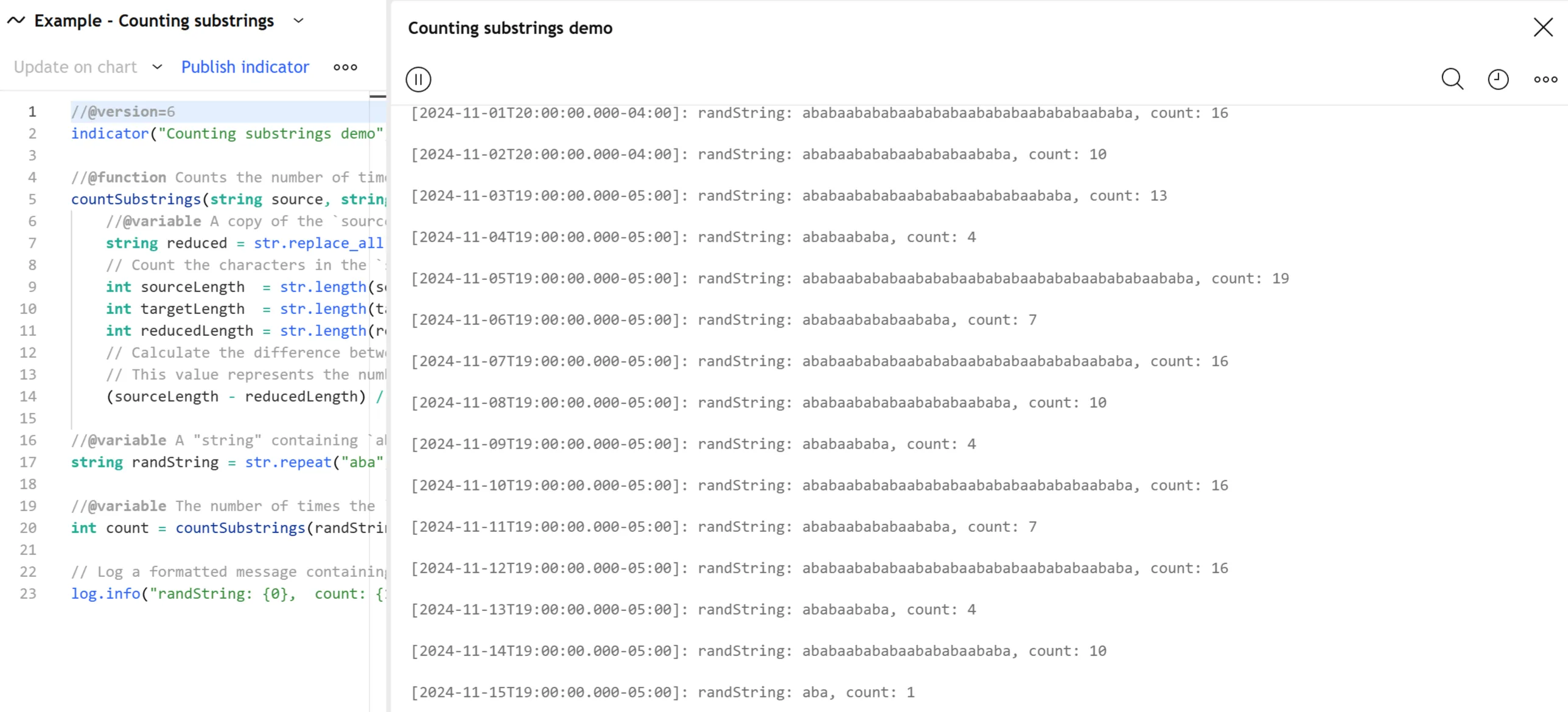
Note that:
- This script uses the second overload of log.info(), which shares the same signature as str.format() but logs a formatted message instead of returning a value. See the Pine Logs section of the Debugging page to learn more about the
log*()functions.
Checking for substrings
The str.contains() function searches a source string for a specified substring, returning a “bool” value representing whether it found the substring. Two similar functions, str.startswith() and str.endswith(), check whether the source starts and ends with a specified substring.
These functions have the following signatures:
str.contains(source, str) → boolstr.startswith(source, str) → boolstr.endswith(source, str) → boolWhere:
sourceis the “string” value that the function searches to find the substring.stris a “string” value containing the substring to find in thesource. The str.contains() function returnstrueif thesourcecontains at least one instance of the substring. The str.startswith() function returnstrueonly if thesourcestarts with the substring, even if the substring exists elsewhere in the character sequence. Likewise, str.endswith() returnstrueonly if thesourceends with the substring.
These functions are convenient when a script needs to check whether a substring exists but does not require the substring in additional calculations. Programmers often use these functions in conditional logic to control script behaviors based on a “string” value’s contents.
The following script creates a spread symbol string from two symbol inputs and requests price information from that spread symbol using a request.security() call. Before executing the request, the script calls str.startswith() to check whether the spreadInput value starts with a leading space and forward slash (/), indicating that the first input is empty. If the call returns true, the script replaces the missing symbol in the “string” value with the chart’s symbol to prevent errors.
The script then plots the retrieved data as candles in a separate pane. The colors of the candles change if the chart is in Bar Replay mode. The script tests for Bar Replay mode by searching for the replay substring in the chart’s ticker identifier (syminfo.tickerid) using a str.contains() call:
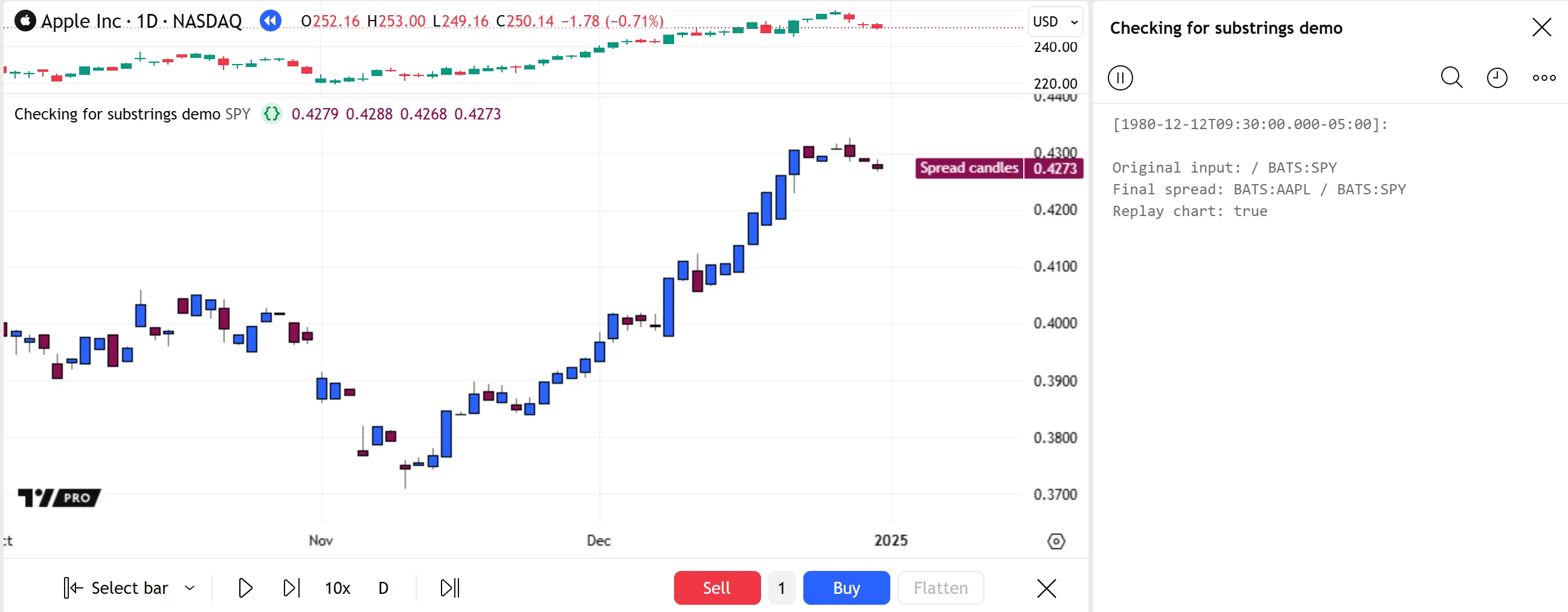
Note that:
- We used
" /"as the substring value in the str.startswith() call because an empty string does not detect the empty input value. When the substring specified in a str.contains(), str.startswith(), or str.endswith() call is empty, the function always returnstruebecause the argument can match any position in a string’s sequence.
Splitting strings
The str.split() function splits a single “string” value into one or more substrings based on a separator substring in the value’s character sequence, then collects the results in an array. Below is the function’s signature:
str.split(string, separator) → array<string>Where:
- The specified
stringis the value to divide into substrings. - The
separatoris a “string” value containing the characters that divide each substring. The resulting array does not include the separator in its elements. If the value is empty, the function splits the string into single-character substrings.
The str.split() function returns an array of strings, unlike the other str.*() functions. Scripts can use array.*() functions on these arrays, or iterate through them directly with for…in loops. Programmers often use str.split() to process “string” inputs and parameters that represent lists of arguments for dynamic requests and other calculations.
The following script requests data from several contexts based on a text area input containing a comma-separated list of symbols. First, the script splits the input value based on its commas with str.split() to construct an array of symbol strings. Then, it uses a for…in loop to iterate over the array’s contents, request data for each symbol, and populate a table with the results. Additionally, the table’s first row contains a “string” representation of the array of symbols:

Note that:
- The symbol strings in the array contain extra whitespaces, which are not visible in the table. However, in contrast to some other function parameters, the
symbolparameter of request.security() ignores leading and trailing whitespaces in its argument. - The script uses str.tostring() and concatenation to create the strings used for the table’s text.
- This script can fetch data from other contexts within a loop using “series string”
symbolvalues because scripts allow dynamic requests by default. See the Dynamic requests section of the Other timeframes and data page for more information.
Locating and retrieving substrings
The str.pos() function searches a source string for the first occurrence of a specified substring and returns an “int” value representing the position of its initial character boundary. The function’s signature is as follows:
str.pos(source, str) → intWhere:
sourceis the “string” value to search for the first occurrence of thestrsubstring.stris a “string” value representing the substring to locate in thesource. If the argument is na or an empty “string” value, the function returns 0 (the first possible position).
The str.substring() function retrieves a substring from a source value at specified character positions. This function has the following signatures:
str.substring(source, begin_pos) → stringstr.substring(source, begin_pos, end_pos) → stringWhere:
sourceis the “string” value containing the substring.begin_posis an “int” value representing the position of the substring’s first character in thesource, where the numbering starts from zero. If the value is na, the function sets the initial position to 0. The script raises an error if the specified position is invalid.- The
end_posis an “int” value representing the position after the substring’s last character in thesource. This position is exclusive, meaning the returned value does not contain this position’s character. If the value is not specified or represents a position outside the string’s length, the substring includes all characters from thebegin_posonward. If the value is less than thebegin_pos, it causes a runtime error.
For example, the begin_pos value of the substring "Trading" in the string "TradingView" is 0, because the substring starts at the source string’s first character position. The end_pos value is 7, because the substring’s last character (g) is at position 6, and end_pos represents the position after that character. To retrieve only the first character of a string as a substring, use a call such as str.substring("TradingView", 0, 1).
Programmers often use these functions together by retrieving positional values with str.pos() and then using those values to extract substrings with str.substring() for additional calculations. This technique is an efficient alternative to matching patterns for substrings at specific positions that have unique characters.
The following simple script uses these functions to extract the “area” and “location” parts of the syminfo.timezone variable’s IANA identifier. The script calls str.pos() to get the position of the / character in the time zone string, which it assigns to the dividerPos variable. Then, it uses that variable in two str.substring() calls. The first call retrieves the substring from position 0 to dividerPos, and the second retrieves the substring from the position at dividerPos + 1 to the end of the string.
The script displays the IANA identifier, the retrieved substrings, and the formatted date and time of the latest execution in a single-cell table on the last bar:

Note that:
- The first str.substring() call does not include the character at the position specified by
dividerPos. Its result contains only the characters from position 0 todividerPos - 1.
It’s important to emphasize that the str.pos() function only finds the first occurrence of a specified substring. However, in some cases, programmers might require the positions of the substring’s other occurrences. One way to achieve this result is by repeatedly reducing a “string” value with str.substring() and locating the substring in the new value with str.pos().
The advanced example script below contains a getPositions() function that returns an array containing every substring position within a specified source. The function first uses str.pos() to get the position of the first substring and creates an array containing that value with array.from(). If the initial position is not na, the function removes all characters up to the substring’s end position with str.substring(). Then, it executes a for…in loop that repeatedly locates the substring, pushes the calculated position into the array, and reduces the character sequence. The loop stops only after the array contains the position of every substring in the source value.
On the first bar, the script uses the function to analyze substring occurrences in four arbitrarily selected strings, then logs formatted messages containing the results in the Pine Logs pane:

Note that:
- Although the
positionsarray starts with one element, the for…in loop performs more than one iteration because Pine loops can have dynamic boundaries. After each execution of the array.push() call, thepositionsarray’s size increases, allowing a new iteration. Refer to the Loops page for more information. - Each reduced version of the string starts at the position after the last character of the detected substring. The script identifies the end position by adding the substring’s str.length() value to its starting position.
Matching patterns
Pine scripts can dynamically match and retrieve substrings using the str.match() function. In contrast to the other str.*() functions, which only match sequences of literal characters, the str.match() function uses regular expressions (regex) to match variable character patterns. The function’s signature is as follows:
str.match(source, regex) → stringWhere:
sourceis the “string” value containing the sequence to match using the regular expression.regexis a “string” value representing the regular expression that specifies the pattern to match in thesource. The function returns the first substring that follows the match pattern. If the regex does not match any substring in thesource, the function returns an empty string.
Because the str.match() function matches patterns in a string’s character sequence rather than strictly literal characters, a single call to this function can perform a wide range of text-matching tasks that would otherwise require multiple calls to other str.*() functions or custom operations.
For example, this script requests data from a FINRA Short Sale Volume series for a specified symbol. It uses separate str.startswith() calls to check whether the symbol string has one of the supported exchange prefixes. It locates and removes the exchange prefix with str.pos() and str.substring(), constructs a FINRA ticker ID with str.format() and logs its value, then executes the request.security() call only if one of the str.startswith() calls returns true. The script plots the retrieved data on the chart as columns:

In the script version below, we replaced the multiple str.startswith() calls with an expression containing a str.match() call. The call matches one of the supported exchange prefixes at the start of the string using the following regular expression:
^(?:BATS|NASDAQ|NYSE|AMEX):We also replaced the str.pos() and str.substring() calls with a str.match() call. The call calculates the noPrefix value with a regex that matches all characters after the input value’s colon (:):
(?<=:).+These changes achieve the same results as the previous script, but with more concise function calls:
Note that:
- The caret (
^) at the beginning of the regex string matches the beginning of thesymbolInput. - The
(?:...)syntax in the regex string creates a non-capturing group. - The pipe character (
|) in the regex acts as an OR operator. The group matches only one of the character sequences separated by the character (BATS,NASDAQ,NYSE, orAMEX). - The
(?<=...)syntax defines a lookbehind assertion, which checks if the specified pattern precedes the match. - The
.(period) character has a special meaning in regex strings. It matches any character, excluding line terminators by default. - The
+(plus sign) character is a quantifier. It specifies that the previous token (.) must match one or more times.
The flexibility of regular expressions also allows str.match() to perform advanced matching tasks that are impractical or infeasible with other str.*() functions.
For instance, suppose we want to create a script that executes dynamic requests for a list of symbols specified in a text area input, and we require a specific input format consisting of only valid ticker patterns, comma separators with optional space characters, and no empty items. This validation is difficult to achieve with the other str.*() functions because they rely on literal character sequences. However, with str.match(), we can define a single regular expression that matches the input only if it meets our required formatting criteria.
The script below demonstrates a single str.match() function call that validates the format of an input list of symbols. The user-defined processList() function combines strings to form the following regex for matching the list value:
^ *(?:(?:\w+:)?\w+(?:\.\w+){0,2}!? *, *)*(?:\w+:)?\w+(?:\.\w+){0,2}!? *$If the str.match() call returns a non-empty string, meaning the constructed pattern matches the list argument, the processList() function uses str.replace_all() to remove all space characters, then calls str.split() to split the string based on its commas to create an array of symbol substrings. Otherwise, it raises a runtime error with the runtime.error() function.
The script loops through the returned array of substrings to request data for each specified symbol and populate a table with the results:

Note that:
- When creating regex strings, it is often helpful to display them in a script’s text outputs to ensure they are formatted as intended. In this script, we included a log.info() call to show the resulting regular expression and its match in the Pine Logs pane.
- Because the backslash (
\) is an escape character in Pine strings, the value used as theregexargument in a str.match() call requires two consecutive backslashes for each single backslash in the regular expression. - The
\\wparts of the regex string specify the\wpattern, a predefined character class that matches word characters (letters, digits, or low lines). - The
*(asterisk) and{0,2}parts of the regular expression are quantifiers, similar to+. The asterisk requires the previous token to match zero or more times. The{0,2}quantifier requires the match to occur exactly zero to two times. - The
$(dollar sign) character in this regular expression matches the end of the input, excluding any final line terminators (\n). - Because the
.(period) character has a special meaning in regex strings, we must prefix it with two backslashes (\\) in the string to match a literal period.
Regex syntax reference
Every programming language’s regex engine has unique characteristics and syntax. Some regex syntax is universal across engines, while other patterns and modifiers are engine-specific.
The tables below provide a categorized overview of the syntax patterns supported by Pine’s regex engine along with descriptions, remarks, and examples to explain how they work.
Escapes and character references
Click to show/hide
| Token/syntax | Description and remarks |
|---|---|
\ | Changes the meaning of the next character. Because Pine strings natively use \ as an escape character, regex strings containing it must include an additional \ to use the token in the pattern. For example, "\\" represents a single \ (escape token) in the regex, and "\\\\" represents \\ (literal backslash).Some other characters always or conditionally represent regex syntax, including ., ^, $, *, +, ?, (, ), [, ], {, }, |, and -.To match a special character literally, include "\\" immediately before it in the string (e.g., "\\+" matches the literal + character).Note that some sequences of otherwise literal characters can also have syntactical meaning. See below for examples. |
\Q...\E | Matches everything between \Q and \E literally, ignoring the syntactical meaning of special characters and sequences.For example, the regex string "\\Q[^abc]\\E" matches the literal sequence of [, ^, a, b, c, and ] characters instead of creating a character class. |
a | Matches the literal character a (U+0061).By default, the regex engine is case-sensitive. If the string includes the (?i) modifier before the token, the match becomes case-insensitive. For example, the regex string "(?i)a" matches the a or A character. |
\t | Matches the tab space character (U+0009). |
\n | Matches the newline character (U+000A). |
\x61 | A two-digit Unicode reference that matches the hexadecimal point U+0061 (the a character).This shorthand syntax works only for codes with leading zeros and up to two nonzero end digits. It cannot reference other Unicode points. For example, the regex string "\\x2014" matches U+0020 (the space character) followed by U+0031 (the 1 character) and U+0034 (the 4 character). It does not match U+2014 (the — character). |
\u2014 | A four-digit Unicode reference that matches the hexadecimal point U+2014 (—, Em Dash).This syntax works only for codes with leading zeros and up to four nonzero end digits. It cannot reference larger Unicode points. For example, the regex string "\\u1F5E0" matches U+1F5E (unassigned) followed by U+0030 (the 0 character), resulting in no match. It does not match U+1F5E0 (the Stock Chart character). |
\x{...} | The full-range Unicode reference syntax. The hexadecimal digits enclosed in the brackets can refer to any Unicode point. Leading zeros in the digits do not affect the matched Unicode point. For example, the regex strings "\\x{61}", "\\x{061}", "\\x{0061}", and "\\x{000061}" all match U+0061 (the a character). |
Character class and logical constructions
Click to show/hide
| Token/syntax | Description and remarks |
|---|---|
[abc] | A character class that matches only one of the characters listed (a, b, or c). It does not match the entire abc sequence.Each listed character, range, or nested class between two [] brackets represents a specific possible match.Note that several special characters have a literal meaning inside classes (e.g., the regex string "[.+$]" matches ., +, or $ literally). However, regex strings should still escape the following characters to treat them literally because they maintain a special meaning in most cases: \, [, ], ^, -. |
[a-z] | A class that matches a single character in the range from a (U+0061) to z (U+007A). It is equivalent to [\x{61}-\x{7A}].Note that the left side of the - character must have a smaller Unicode value than the right.For example, the regex string "[f-a]" is invalid because f has the Unicode value U+0066, which is larger than the value of a.If the dash ( -) is at the start or end of the enclosed text, the regex treats it as a literal character instead of a character range marker (e.g., "[-abc]" matches -, a, b, or c literally). |
[a-zA-Z] | A class containing a list of character ranges. It matches any character from a (U+0061) to z (U+007A) or A (U+0041) to Z (U+005A) only.It is equivalent to [\x{61}-\x{7A}\x{41}-\x{5A}].The syntax [a-z[A-Z]] also produces the same match. |
[^...] | The syntax for a class that matches any character except for the ones specified. For example, the regex string "[^abc\\n ]" matches any character except for a, b, c, \n (newline), or (space).Note that only a caret ( ^) at the start of the enclosed text signifies negation. If the character comes after that point, the regex considers it a possible literal match (e.g., "[ab^c]" matches the a, b, ^, or c character literally). |
[...&&[...]] | The syntax for a nested class structure that matches any character within the intersection of two character classes. Example 1: The regex string "[abc&&[cde]]" matches c exclusively because it is the only character common to both lists.Example 2: The regex string "[a-z&&[^def]]" matches any character from lowercase a to z except for d, e, or f. |
expr1|expr2 | An OR operation that matches either the expr1 or expr2 substring. It does not include both in the match. |
Predefined classes
Click to show/hide
| Token/syntax | Description and remarks |
|---|---|
. | Matches any character on the line. By default, it excludes line terminators (e.g., \n). To include line terminators in the match, add the (?s) modifier before the token in the regex string (e.g., "(?s)."). |
\d | Matches a decimal digit character. By default, it is equivalent to [0-9]. However, if the regex string includes the "(?U)" modifier before the token, it can match other Unicode characters with the “Digit” property.For example, the string "(?U)\\d" can match characters such as U+FF11 (Fullwidth Digit One). In contrast, the only “Digit One” character matched by the [0-9] class, even with the (?U) modifier, is U+0031 (the 1 character). |
\D | Matches a non-digit character. By default, it is equivalent to [^0-9], which does not negate other Unicode digits. To exclude other Unicode digits from the match, include the (?U) modifier before the token in the regex string (e.g., "(?U)\\D"). |
\w | Matches a word character (letter, digit, or low line). By default, it is equivalent to [a-zA-Z0-9_], which excludes other Unicode characters. To include other Unicode letters, digits, or low lines in the match, add the (?U) modifier before the token in the regex string.For example, "(?U)\\w" can match characters such as U+FE4F (Wavy Low Line), whereas the only low line character the [a-zA-Z0-9_] class matches is U+005F (_). |
\W | Matches a non-word character. By default, it is equivalent to [^a-zA-Z0-9_], which does not negate other Unicode characters. To exclude other Unicode word characters from the match, include the (?U) modifier before the token (e.g., "(?U)\\W"). |
\h | Matches a horizontal whitespace character, such as the tab space (\t), standard space, and other characters such as U+2003 (Em Space).The token matches other Unicode characters, even if the regex string includes the (?-U) modifier. |
\H | Matches a character that is not a horizontal whitespace. It also excludes other Unicode spaces, even if the regex string includes the (?-U) modifier |
\s | Matches a whitespace or other control character. In contrast to \h, this token covers a broader range of characters, including vertical spaces such as \n. |
\S | Matches a non-whitespace character. In contrast to \H, this token excludes a broader character range of characters from the match. |
Unicode property classes
Click to show/hide
| Token/syntax | Description and remarks |
|---|---|
\p{...} | The syntax to match a Unicode point that has a specific property, such as script type, block, general category, etc. See the following rows to learn the required syntax for different common Unicode property references. To match any character that does not have a specific Unicode property, use the uppercase P in the syntax (\P{...}) |
\p{IsScriptName} or\p{Script=ScriptName} | Unicode script reference syntax. Matches any code point belonging to the ScriptName Unicode script. The specified name should not contain spaces.For example, the regex strings "\\p{IsLatin}" and "\\p{Script=Latin}" both match any Unicode point that is part of the Latin script. |
\p{InBlockName} or\p{Block=BlockName} | Unicode block reference syntax. Matches any code point belonging to the BlockName Unicode block. The specified name should not contain spaces.For example, the regex string "\\p{InBasicLatin}" matches any Unicode point that is part of the Basic Latin block, and "\\p{Block=Latin-1Supplement}" matches any point belonging to the Latin-1 Supplement block. |
\p{category} or\p{gc=category} | Unicode general category reference syntax. Matches any Unicode point with the assigned category abbreviation.For example, the regex string "\\p{L}" or "\\p{gc=L}" matches any Unicode point in the Letter (L) category, and "\\p{N}" matches any point in the Number (N) category.Note that, unlike some regex engines, Pine’s regex engine does not support the long form of a category name, (e.g., "Letter" instead of "L"). |
\p{ClassName} | The syntax for referencing the Unicode mapping of a POSIX character class, in Java notation. For example, the regex string "\\p{XDigit}" matches a hexadecimal digit. By default, it is equivalent to "[A-Fa-f0-9]".Note that the default behavior for POSIX classes matches only ASCII characters. To allow other Unicode matches for a POSIX class, use the (?U) modifier. For instance, "(?U)\\p{XDigit}" can match non-ASCII characters that represent hexadecimal digits, such as U+1D7D9 (the 𝟙 character). |
Group constructions
Click to show/hide
| Token/syntax | Description and remarks |
|---|---|
(...) | A capturing group that matches the enclosed sequence and stores the matched substring for later reference. Each capturing group construction has an assigned group number starting from 1. The regex can reference a capturing group’s match with the \# syntax, where # represents the group number.For example, the regex string "(a|b)cde\\1" matches a or b, followed by cde, and then another occurrence of the (a|b) group’s initial match. If the group matched a, the \1 reference also matches a. If it matched b, the reference also matches b.If the regex does not need to use a group’s match later, using a non-capturing group is the more efficient choice, e.g., (?:...). |
(?<name>...) | A named capturing group that matches the enclosed sequence and stores the matched substring with an assigned identifier. The regex can use the \k<name> syntax to reference the group’s match, where name is the assigned identifier. For example, the string "(?<myGroup>a|b)cde\\k<myGroup>" matches a or b, followed by cde, and then another instance of the substring (a or b) matched by the capturing group.As with a standard capturing group, a named capturing group contributes to the group count and has a group number, meaning the regex can also reference a named group with the \# syntax, for example, "(?<myGroup>a|b)cde\\1". |
(?:...) | A non-capturing group that matches the enclosed sequence without storing the matched substring. Unlike a capturing group, the regex string cannot reference a previous non-capturing group’s match. For example, the regex string "(?:a|b)\\1" matches a or b, then references an unassigned group match, resulting in no match.In contrast to all other group constructions, standard non-capturing groups can contain pattern modifiers that apply exclusively to their scopes. For example, "(?i)(?-i:a|b)c" matches a or b followed by lowercase c or uppercase C. The (?i) part of the regex activates case-insensitive matching globally, but the -i token deactivates the behavior for the group’s scope only.Note that non-capturing groups typically have a lower computational cost than capturing groups. |
(?>...) | An independent non-capturing group (atomic group). Unlike a standard non-capturing group, an atomic group consumes as many characters as possible without allowing other parts of the pattern to use them. For example, the regex string "(?s)(?>.+).+" fails to produce a match because the atomic group (?>.+) consumes every available character, leaving nothing for the following .+ portion to match.In contrast, the regex string "(?s)(?:.+).+" matches the entire source string because the standard non-capturing group (?:.+) releases characters from its match as needed, allowing .+ to match at least one character. |
Quantifiers
Click to show/hide
| Token/syntax | Description and remarks |
|---|---|
? | Appending ? to a character, group, or class specifies that the matched substring must contain the pattern once or not at all.For example, the regex string "a?bc?" matches abc, ab, bc, or b because a and c are optional.By default, regex quantifiers are greedy, meaning they match as many characters as possible, releasing some as necessary. Adding ? to another quantifier makes it lazy, meaning it matches the fewest characters possible, expanding its match only when required.For example, with a source string of "a12b34b", the regex string "a.*b" matches the entire sequence, whereas "a.*?b" matches the smallest valid substring with the pattern, which is a12b. |
* | Appending * to a character, group, or class specifies that the matched substring must contain the pattern zero or more times consecutively.For example, the regex string "a*b" matches zero or more consecutive a characters followed by a single b character. |
+ | Appending + to a character, group, or class specifies that the matched substring must contain the pattern one or more times consecutively.For example, the regex string "\\w+abc" matches one or more consecutive word characters followed by abc.Adding + to another quantifier makes it possessive. Unlike a greedy quantifier (default), which releases characters from the match as necessary, a possessive quantifier consumes as many characters as possible without releasing them for use in other parts of the pattern.For instance, the regex string "\\w++abc" fails to produce a match because \w++ consumes all word characters in the pattern, including a, b, and c, leaving none for the abc portion to match. |
{n} | Appending {n} to a character, group, or class specifies that the matched substring must contain the pattern exactly n times consecutively, where n >= 0.For example, the regex string "[abc]{2}" matches two consecutive characters from the [abc] class, meaning the possible substrings are aa, ab, ac, ba, bb, bc, ca, cb, or cc. |
{n,} | Appending {n,} to a character, group, or class specifies that the matched substring must contain the pattern at least n times consecutively, where n >= 0.For example, the regex string "a{1,}b{2,}" matches one or more consecutive a characters followed by two or more consecutive b characters. |
{n, m} | Appending {n, m} to a character, group, or class specifies that the matched substring must contain the pattern at least n times but no more than m times, where n >= 0, m >= 0, and m >= n.For example, the regex string "\\w{1,5}b{2,4}" matches one to five consecutive word characters followed by two to four repeated b characters. |
Boundary assertions
Click to show/hide
| Token/syntax | Description and remarks |
|---|---|
\A | Matches the starting point of the source string without consuming characters. It enables the regex to isolate the initial pattern in a string without allowing matches in other locations. For example, the regex string "\\A\\w+" matches a sequence of one or more word characters only if the sequence is at the start of the source string. |
^ | When this character is outside a character class construction (i.e., [^...]), it matches the starting point of a line in the source string without consuming characters.By default, the character performs the same match as \A. However, if the regex string uses the (?m) modifier, it can also match a point immediately after a newline character (\n).For example, the regex string "(?m)^[xyz]" matches x, y, or z if the character is at the start of the source string or immediately after the \n character. |
\Z | Matches the ending point of the source string, or the point immediately before the final character if it is \n, without consuming characters. It enables the regex to isolate the final pattern in a string without allowing matches in other locations.For example, the regex string "\\w+\\Z" matches a sequence of one or more word characters only if the sequence is at the end of the source string or immediately before the final line terminator. |
\z | Matches the absolute ending point of the source string without consuming characters. Unlike \Z (uppercase), this token does not match the point before any final line terminator.For example, the regex string "(?s)\\w+.*\\z" matches a sequence of one or more word characters, followed by zero or more extra characters, only if the sequence is at the absolute end of the source string. |
$ | Matches the ending point of a line in the source string without consuming characters. By default, it performs the same match as \Z (uppercase). However, if the regex string uses the (?m) modifier, it can match any point immediately before a newline (\n) character. For example, the regex string "(?m)[123]$" matches 1, 2, or 3 only if the character is at the end of the source string or immediately before the \n character. |
\b | Matches a word boundary, which is the point immediately before or after a sequence of word characters (members of the \w class).For example, the regex string "\\babc" matches abc only if it is at the starting point of a word character sequence. |
\B | Matches a non-word boundary, which is any point between characters that is not the start or end of a word character sequence. For example, the regex string "\\Babc" matches abc only if it is not at the start of a word character sequence. |
Lookahead and lookbehind assertions
Click to show/hide
| Token/syntax | Description and remarks |
|---|---|
(?=...) | A positive lookahead assertion that checks whether the specified sequence immediately follows the current match location, without consuming characters. For example, the regex string "a(?=b)" matches the a character only if b occurs immediately after that point, and it does not include b in the matched substring. |
(?!...) | A negative lookahead assertion that checks whether the specified sequence does not immediately follow the current match location, without consuming characters. For example, the regex string "a(?!b)" matches the a character only if the b character does not immediately follow it. |
(?<=...) | A positive lookbehind assertion that checks whether the specified sequence immediately precedes the current match location, without consuming characters. For example, the regex string "(?<=a)b" matches the b character only if the a character occurs immediately before that point, and it does not include a in the matched substring. |
(?<!...) | A negative lookbehind assertion that checks whether the specified sequence does not immediately precede the current match location, without consuming characters. For example, the regex string "(?<!a)b" matches the b character only if the a character does not immediately precede it. |
Pattern modifiers
Click to show/hide
| Token/syntax | Description and remarks |
|---|---|
(?...) | This syntax applies a global list of inline pattern modifiers (flags) to the regex string. Pattern modifiers change the matching behaviors of the regex engine. All parts of the regex string that come after this syntax update their behaviors based on the specified modifiers, and those behaviors persist from that point until explicitly overridden. For example, "(?mi)" activates multiline and case-insensitive modes for the rest of the regex string.To deactivate modifiers, include the - character before the list of modifier tokens. For instance, "(?-mi)" deactivates multiline and case-insensitive modes for the rest of the regex string.Standard non-capturing groups can also utilize modifiers locally, allowing different behaviors exclusively within group constructions. For example, "(?U:\\d)123" activates Unicode-aware matching only for the specific group. The modifier does not apply globally, meaning the remaining 123 part of the regex string can only match ASCII characters.See the rows below for details about the most common, useful pattern modifiers for Pine regex strings. |
i | The i character represents case-insensitive mode when used as a global modifier ((?i)) or group modifier ((?i:...)).For example, the regex string "a(?i)b(?-i)c" matches lowercase a, uppercase B or lowercase b, and then lowercase c.Note that case-insensitive mode only applies to ASCII characters unless Unicode-aware mode is active. |
m | The m character represents multiline mode when used as a global modifier ((?m)) or group modifier ((?m:...)).By default, the ^ and $ boundary assertions match the start and end of the source string, excluding final line terminators. With multiline mode enabled, they match the start and end boundaries of any separate line in the string.For example, the regex string "^abc" matches abc only if the source string starts with that sequence, whereas "(?m)^abc" matches abc if it is at the start of the string or immediately follows a newline character (\n). |
s | The lowercase s character represents single-line mode (dotall mode) when used as a global modifier ((?s)) or group modifier ((?s:...)).By default, the . character matches any character except for line terminators such as \n. With single-line mode enabled, the regex treats the source string as one line, allowing the character to match line terminators.For example, using the regex string ".+" on the source string "ab\nc" matches ab only, whereas "(?m).+" matches the entire source string. |
U | The uppercase U character represents Unicode-aware mode when used as a global modifier ((?U)) or group modifier ((?U:...)).By default, most of the regex engine’s predefined character classes and mapped POSIX classes do not match non-ASCII characters. With Unicode-aware mode enabled, the regex allows these classes, and various ASCII character tokens, to match related Unicode characters. For example, the regex string "\\d(?U)\\d+" matches a single ASCII digit followed by one or more Unicode digit characters. |
x | The lowercase x character represents verbose mode (comments mode) when used as a global modifier ((?x)) or group modifier ((?x:...)).In this mode, the regex string ignores whitespace characters and treats sequences starting with # as comments.For example, the regex string "(?x)[a-f ] 1 2\n3 # this is a comment!" produces the same match as "[a-f]123". It does not match the space or newline characters, or anything starting from the # character.Regex strings with this modifier can include multiple comments on separate lines (e.g., "a #match 'a' \nb #followed by 'b'" matches ab).To match whitespaces or the # character in this mode, escape them using backslashes or the \Q...\E syntax. For instance, "(?x)\\#\\ \\# #comment" and "(?x)\\Q# #\\E #comment" both literally match the sequence # #. |