INVITE-ONLY SCRIPT
已更新 Multi-Panel: Trade-Volatility-Probability [Loxx]
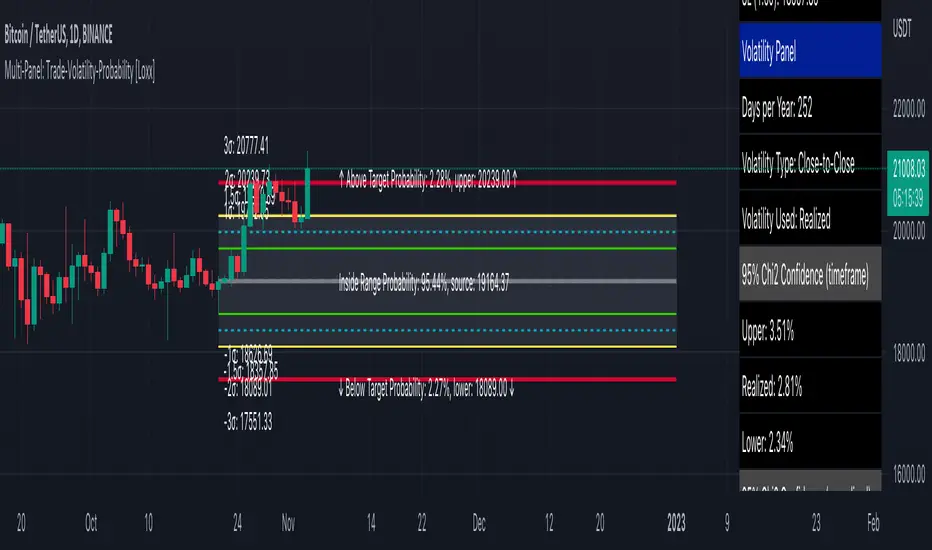
Multi-Panel: Trade-Volatility-Probability [Loxx] shows user selected and volatility-based price levels and probabilities on the chart. This is useful for both options and all styles of up/down trading methods that rely on volatility.
Trading Panel: Shows trading information to take profits and stop-loss based on multiples of volatility. Also shows equity inputs by the user to calculate optimal position size
Key things to note about the Trading Panel
-Trade side: Long or short. you change this this to change the take profit and SL levels in displayed on the table to be used w/ up/down trading styles that rely on volatility stops
-Account size: User enters total balance available for trade
-Risk: Total % of account size you're willing to lose should the SL be hit
-Position size: Size of the position given the SL and your preferred Risk
-Take profit/Stop loss levels: Based on multipliers selected by the user in settings. These shouldn't be changed unless you really know what you're doing with volatility stops
-Entry: Source price. can be 1 of 37 different prices. See Loxx's Expanded Source Types:

Volatility Panel: Shows information about the volatility the user selected to be used to take profit/stop-loss/range calculations. Volatility types included are:
Close-to-Close
Close-to-Close volatility is a classic and most commonly used volatility measure, sometimes referred to as historical volatility .
Volatility is an indicator of the speed of a stock price change. A stock with high volatility is one where the price changes rapidly and with a bigger amplitude. The more volatile a stock is, the riskier it is.
Close-to-close historical volatility calculated using only stock's closing prices. It is the simplest volatility estimator. But in many cases, it is not precise enough. Stock prices could jump considerably during a trading session, and return to the open value at the end. That means that a big amount of price information is not taken into account by close-to-close volatility .
Despite its drawbacks, Close-to-Close volatility is still useful in cases where the instrument doesn't have intraday prices. For example, mutual funds calculate their net asset values daily or weekly, and thus their prices are not suitable for more sophisticated volatility estimators.
Parkinson
Parkinson volatility is a volatility measure that uses the stock’s high and low price of the day.
The main difference between regular volatility and Parkinson volatility is that the latter uses high and low prices for a day, rather than only the closing price. That is useful as close to close prices could show little difference while large price movements could have happened during the day. Thus Parkinson's volatility is considered to be more precise and requires less data for calculation than the close-close volatility.
One drawback of this estimator is that it doesn't take into account price movements after market close. Hence it systematically undervalues volatility. That drawback is taken into account in the Garman-Klass's volatility estimator.
Garman-Klass
Garman Klass is a volatility estimator that incorporates open, low, high, and close prices of a security.
Garman-Klass volatility extends Parkinson's volatility by taking into account the opening and closing price. As markets are most active during the opening and closing of a trading session, it makes volatility estimation more accurate.
Garman and Klass also assumed that the process of price change is a process of continuous diffusion (geometric Brownian motion). However, this assumption has several drawbacks. The method is not robust for opening jumps in price and trend movements.
Despite its drawbacks, the Garman-Klass estimator is still more effective than the basic formula since it takes into account not only the price at the beginning and end of the time interval but also intraday price extremums.
Researchers Rogers and Satchel have proposed a more efficient method for assessing historical volatility that takes into account price trends. See Rogers-Satchell Volatility for more detail.
Rogers-Satchell
Rogers-Satchell is an estimator for measuring the volatility of securities with an average return not equal to zero.
Unlike Parkinson and Garman-Klass estimators, Rogers-Satchell incorporates drift term (mean return not equal to zero). As a result, it provides a better volatility estimation when the underlying is trending.
The main disadvantage of this method is that it does not take into account price movements between trading sessions. It means an underestimation of volatility since price jumps periodically occur in the market precisely at the moments between sessions.
A more comprehensive estimator that also considers the gaps between sessions was developed based on the Rogers-Satchel formula in the 2000s by Yang-Zhang. See Yang Zhang Volatility for more detail.
Yang-Zhang
Yang Zhang is a historical volatility estimator that handles both opening jumps and the drift and has a minimum estimation error.
We can think of the Yang-Zhang volatility as the combination of the overnight (close-to-open volatility ) and a weighted average of the Rogers-Satchell volatility and the day’s open-to-close volatility . It considered being 14 times more efficient than the close-to-close estimator.
Garman-Klass-Yang-Zhang
Garman Klass is a volatility estimator that incorporates open, low, high, and close prices of a security.
Garman-Klass volatility extends Parkinson's volatility by taking into account the opening and closing price. As markets are most active during the opening and closing of a trading session, it makes volatility estimation more accurate.
Garman and Klass also assumed that the process of price change is a process of continuous diffusion (geometric Brownian motion). However, this assumption has several drawbacks. The method is not robust for opening jumps in price and trend movements.
Despite its drawbacks, the Garman-Klass estimator is still more effective than the basic formula since it takes into account not only the price at the beginning and end of the time interval but also intraday price extremums.
Researchers Rogers and Satchel have proposed a more efficient method for assessing historical volatility that takes into account price trends. See Rogers-Satchell Volatility for more detail.
Exponential Weighted Moving Average
The Exponentially Weighted Moving Average (EWMA) is a quantitative or statistical measure used to model or describe a time series. The EWMA is widely used in finance, the main applications being technical analysis and volatility modeling.
The moving average is designed as such that older observations are given lower weights. The weights fall exponentially as the data point gets older – hence the name exponentially weighted.
The only decision a user of the EWMA must make is the parameter lambda. The parameter decides how important the current observation is in the calculation of the EWMA. The higher the value of lambda, the more closely the EWMA tracks the original time series.
Standard Deviation of Log Returns
This is the simplest calculation of volatility . It's the standard deviation of ln(close/close(1))
Pseudo GARCH(2,2)
This is calculated using a short- and long-run mean of variance multiplied by θ.
θavg(var ;M) + (1 − θ) avg (var ;N) = 2θvar/(M+1-(M-1)L) + 2(1-θ)var/(M+1-(M-1)L)
Solving for θ can be done by minimizing the mean squared error of estimation; that is, regressing L^-1var - avg (var; N) against avg (var; M) - avg (var; N) and using the resulting beta estimate as θ.
Average True Range
The average true range (ATR) is a technical analysis indicator, introduced by market technician J. Welles Wilder Jr. in his book New Concepts in Technical Trading Systems, that measures market volatility by decomposing the entire range of an asset price for that period.
The true range indicator is taken as the greatest of the following: current high less the current low; the absolute value of the current high less the previous close; and the absolute value of the current low less the previous close. The ATR is then a moving average, generally using 14 days, of the true ranges.
True Range Double
A special case of ATR that attempts to correct for volatility skew.
Chi-squared Confidence Interval:
Confidence interval of volatility is calculated using an inverse CDF of a Chi-Squared Distribution. You can change the volatility input used to either realized, upper confidence interval, or lower confidence interval. This is included in case you'd like to see how far price can extend if volatility hits it's upper or lower confidence levels. Generally, you'd just used realized volatility, so I wouldn't change this setting.
Inverse CDF of a Chi-Squared Distribution
The chi-square distribution is a one-parameter family of curves. The parameter ν is the degrees of freedom.
The icdf of the chi-square distribution is
x=F^−1(p∣ν) = {x:F(x∣ν) = p}
where
p=F(x∣ν)= ∫ (t^(v-2)/2 * e^t/2) / (2^(v/2) / Γ(v/2))
ν is the degrees of freedom, and Γ( · ) is the Gamma function. The result p is the probability that a single observation from the chi-square distribution with ν degrees of freedom falls in the interval [0, x].
Additional notes on Volatility Panel
-Shows both current timeframe volatility per candle at whatever date backward you select
-Shows annualized volatility basaed on selected days per year and per bar volatility; this is automaitcally caulculated no matter the timeframe used. This means that it'll calculate annualized volatility for the current candle even on the 1 second timeframe. Days per year should be 252 for everything but cryptocurrency; however, for all types of tradable assets, anything over the 3 day timeframe will calculate on 365 days.
Probability Panel
This panel shows the probability levels of a user selected upper and lower price boundary. This includes the inside range of volatility between the lower and upper price levels and the outside probability below the lower price level and above the upper price level. These values are calculated using the CDF (cumulative density function) of a normal distribution. In simpler terms, CDF returns area under a bell curve between two points left and right, or for our purposes, high and low. This yeilds the probabilities you see in the Probability Panel. See the following graphic to visualize how this works:
The red line is the entry bar; the yellow line is the "mean" but in this case just the chosen source price.

Other things to know
You can turn on/off all labels and levels and fills
Trading Panel: Shows trading information to take profits and stop-loss based on multiples of volatility. Also shows equity inputs by the user to calculate optimal position size
Key things to note about the Trading Panel
-Trade side: Long or short. you change this this to change the take profit and SL levels in displayed on the table to be used w/ up/down trading styles that rely on volatility stops
-Account size: User enters total balance available for trade
-Risk: Total % of account size you're willing to lose should the SL be hit
-Position size: Size of the position given the SL and your preferred Risk
-Take profit/Stop loss levels: Based on multipliers selected by the user in settings. These shouldn't be changed unless you really know what you're doing with volatility stops
-Entry: Source price. can be 1 of 37 different prices. See Loxx's Expanded Source Types:
Volatility Panel: Shows information about the volatility the user selected to be used to take profit/stop-loss/range calculations. Volatility types included are:
Close-to-Close
Close-to-Close volatility is a classic and most commonly used volatility measure, sometimes referred to as historical volatility .
Volatility is an indicator of the speed of a stock price change. A stock with high volatility is one where the price changes rapidly and with a bigger amplitude. The more volatile a stock is, the riskier it is.
Close-to-close historical volatility calculated using only stock's closing prices. It is the simplest volatility estimator. But in many cases, it is not precise enough. Stock prices could jump considerably during a trading session, and return to the open value at the end. That means that a big amount of price information is not taken into account by close-to-close volatility .
Despite its drawbacks, Close-to-Close volatility is still useful in cases where the instrument doesn't have intraday prices. For example, mutual funds calculate their net asset values daily or weekly, and thus their prices are not suitable for more sophisticated volatility estimators.
Parkinson
Parkinson volatility is a volatility measure that uses the stock’s high and low price of the day.
The main difference between regular volatility and Parkinson volatility is that the latter uses high and low prices for a day, rather than only the closing price. That is useful as close to close prices could show little difference while large price movements could have happened during the day. Thus Parkinson's volatility is considered to be more precise and requires less data for calculation than the close-close volatility.
One drawback of this estimator is that it doesn't take into account price movements after market close. Hence it systematically undervalues volatility. That drawback is taken into account in the Garman-Klass's volatility estimator.
Garman-Klass
Garman Klass is a volatility estimator that incorporates open, low, high, and close prices of a security.
Garman-Klass volatility extends Parkinson's volatility by taking into account the opening and closing price. As markets are most active during the opening and closing of a trading session, it makes volatility estimation more accurate.
Garman and Klass also assumed that the process of price change is a process of continuous diffusion (geometric Brownian motion). However, this assumption has several drawbacks. The method is not robust for opening jumps in price and trend movements.
Despite its drawbacks, the Garman-Klass estimator is still more effective than the basic formula since it takes into account not only the price at the beginning and end of the time interval but also intraday price extremums.
Researchers Rogers and Satchel have proposed a more efficient method for assessing historical volatility that takes into account price trends. See Rogers-Satchell Volatility for more detail.
Rogers-Satchell
Rogers-Satchell is an estimator for measuring the volatility of securities with an average return not equal to zero.
Unlike Parkinson and Garman-Klass estimators, Rogers-Satchell incorporates drift term (mean return not equal to zero). As a result, it provides a better volatility estimation when the underlying is trending.
The main disadvantage of this method is that it does not take into account price movements between trading sessions. It means an underestimation of volatility since price jumps periodically occur in the market precisely at the moments between sessions.
A more comprehensive estimator that also considers the gaps between sessions was developed based on the Rogers-Satchel formula in the 2000s by Yang-Zhang. See Yang Zhang Volatility for more detail.
Yang-Zhang
Yang Zhang is a historical volatility estimator that handles both opening jumps and the drift and has a minimum estimation error.
We can think of the Yang-Zhang volatility as the combination of the overnight (close-to-open volatility ) and a weighted average of the Rogers-Satchell volatility and the day’s open-to-close volatility . It considered being 14 times more efficient than the close-to-close estimator.
Garman-Klass-Yang-Zhang
Garman Klass is a volatility estimator that incorporates open, low, high, and close prices of a security.
Garman-Klass volatility extends Parkinson's volatility by taking into account the opening and closing price. As markets are most active during the opening and closing of a trading session, it makes volatility estimation more accurate.
Garman and Klass also assumed that the process of price change is a process of continuous diffusion (geometric Brownian motion). However, this assumption has several drawbacks. The method is not robust for opening jumps in price and trend movements.
Despite its drawbacks, the Garman-Klass estimator is still more effective than the basic formula since it takes into account not only the price at the beginning and end of the time interval but also intraday price extremums.
Researchers Rogers and Satchel have proposed a more efficient method for assessing historical volatility that takes into account price trends. See Rogers-Satchell Volatility for more detail.
Exponential Weighted Moving Average
The Exponentially Weighted Moving Average (EWMA) is a quantitative or statistical measure used to model or describe a time series. The EWMA is widely used in finance, the main applications being technical analysis and volatility modeling.
The moving average is designed as such that older observations are given lower weights. The weights fall exponentially as the data point gets older – hence the name exponentially weighted.
The only decision a user of the EWMA must make is the parameter lambda. The parameter decides how important the current observation is in the calculation of the EWMA. The higher the value of lambda, the more closely the EWMA tracks the original time series.
Standard Deviation of Log Returns
This is the simplest calculation of volatility . It's the standard deviation of ln(close/close(1))
Pseudo GARCH(2,2)
This is calculated using a short- and long-run mean of variance multiplied by θ.
θavg(var ;M) + (1 − θ) avg (var ;N) = 2θvar/(M+1-(M-1)L) + 2(1-θ)var/(M+1-(M-1)L)
Solving for θ can be done by minimizing the mean squared error of estimation; that is, regressing L^-1var - avg (var; N) against avg (var; M) - avg (var; N) and using the resulting beta estimate as θ.
Average True Range
The average true range (ATR) is a technical analysis indicator, introduced by market technician J. Welles Wilder Jr. in his book New Concepts in Technical Trading Systems, that measures market volatility by decomposing the entire range of an asset price for that period.
The true range indicator is taken as the greatest of the following: current high less the current low; the absolute value of the current high less the previous close; and the absolute value of the current low less the previous close. The ATR is then a moving average, generally using 14 days, of the true ranges.
True Range Double
A special case of ATR that attempts to correct for volatility skew.
Chi-squared Confidence Interval:
Confidence interval of volatility is calculated using an inverse CDF of a Chi-Squared Distribution. You can change the volatility input used to either realized, upper confidence interval, or lower confidence interval. This is included in case you'd like to see how far price can extend if volatility hits it's upper or lower confidence levels. Generally, you'd just used realized volatility, so I wouldn't change this setting.
Inverse CDF of a Chi-Squared Distribution
The chi-square distribution is a one-parameter family of curves. The parameter ν is the degrees of freedom.
The icdf of the chi-square distribution is
x=F^−1(p∣ν) = {x:F(x∣ν) = p}
where
p=F(x∣ν)= ∫ (t^(v-2)/2 * e^t/2) / (2^(v/2) / Γ(v/2))
ν is the degrees of freedom, and Γ( · ) is the Gamma function. The result p is the probability that a single observation from the chi-square distribution with ν degrees of freedom falls in the interval [0, x].
Additional notes on Volatility Panel
-Shows both current timeframe volatility per candle at whatever date backward you select
-Shows annualized volatility basaed on selected days per year and per bar volatility; this is automaitcally caulculated no matter the timeframe used. This means that it'll calculate annualized volatility for the current candle even on the 1 second timeframe. Days per year should be 252 for everything but cryptocurrency; however, for all types of tradable assets, anything over the 3 day timeframe will calculate on 365 days.
Probability Panel
This panel shows the probability levels of a user selected upper and lower price boundary. This includes the inside range of volatility between the lower and upper price levels and the outside probability below the lower price level and above the upper price level. These values are calculated using the CDF (cumulative density function) of a normal distribution. In simpler terms, CDF returns area under a bell curve between two points left and right, or for our purposes, high and low. This yeilds the probabilities you see in the Probability Panel. See the following graphic to visualize how this works:
The red line is the entry bar; the yellow line is the "mean" but in this case just the chosen source price.
Other things to know
You can turn on/off all labels and levels and fills
發行說明
Updated default UI 發行說明
Updated default volatility to ATR. 發行說明
Updated moving averages. Updated period inputs for ATR/TRD 發行說明
Fixed text sizing發行說明
Updated default settings發行說明
Added additional types of volatility added.Standard Deviation
Standard deviation is a statistic that measures the dispersion of a dataset relative to its mean and is calculated as the square root of the variance. The standard deviation is calculated as the square root of variance by determining each data point's deviation relative to the mean. If the data points are further from the mean, there is a higher deviation within the data set; thus, the more spread out the data, the higher the standard deviation.
Adaptive Deviation
By definition, the Standard Deviation (STD, also represented by the Greek letter sigma σ or the Latin letter s) is a measure that is used to quantify the amount of variation or dispersion of a set of data values. In technical analysis we usually use it to measure the level of current volatility .
Standard Deviation is based on Simple Moving Average calculation for mean value. This version of standard deviation uses the properties of EMA to calculate what can be called a new type of deviation, and since it is based on EMA , we can call it EMA deviation. And added to that, Perry Kaufman's efficiency ratio is used to make it adaptive (since all EMA type calculations are nearly perfect for adapting).
The difference when compared to standard is significant--not just because of EMA usage, but the efficiency ratio makes it a "bit more logical" in very volatile market conditions.
See how this compares to Standard Devaition here:
Adaptive Deviation
![Adaptive Deviation [Loxx]](https://s3.tradingview.com/t/To2emkFR_mid.png)
Median Absolute Deviation
The median absolute deviation is a measure of statistical dispersion. Moreover, the MAD is a robust statistic, being more resilient to outliers in a data set than the standard deviation. In the standard deviation, the distances from the mean are squared, so large deviations are weighted more heavily, and thus outliers can heavily influence it. In the MAD, the deviations of a small number of outliers are irrelevant.
Because the MAD is a more robust estimator of scale than the sample variance or standard deviation, it works better with distributions without a mean or variance, such as the Cauchy distribution.
For this indicator, I used a manual recreation of the quantile function in Pine Script. This is so users have a full inside view into how this is calculated.
Efficiency-Ratio Adaptive ATR
Average True Range (ATR) is widely used indicator in many occasions for technical analysis . It is calculated as the RMA of true range. This version adds a "twist": it uses Perry Kaufman's Efficiency Ratio to calculate adaptive true range
See how this compares to ATR here:
ER-Adaptive ATR
![ER-Adaptive ATR [Loxx]](https://s3.tradingview.com/7/7ywmpaOY_mid.png)
Mean Absolute Deviation
The mean absolute deviation (MAD) is a measure of variability that indicates the average distance between observations and their mean. MAD uses the original units of the data, which simplifies interpretation. Larger values signify that the data points spread out further from the average. Conversely, lower values correspond to data points bunching closer to it. The mean absolute deviation is also known as the mean deviation and average absolute deviation.
This definition of the mean absolute deviation sounds similar to the standard deviation ( SD ). While both measure variability, they have different calculations. In recent years, some proponents of MAD have suggested that it replace the SD as the primary measure because it is a simpler concept that better fits real life.
For Pine Coders, this is equivalent of using ta.dev()
發行說明
Added new volatility type: Static Percent. You can now manually enter the % Static value and then this value will be multiplied by the TP and SL multiples to set targets.僅限邀請腳本
僅作者批准的使用者才能訪問此腳本。您需要申請並獲得使用許可,通常需在付款後才能取得。更多詳情,請依照作者以下的指示操作,或直接聯絡loxx。
TradingView不建議在未完全信任作者並了解其運作方式的情況下購買或使用腳本。您也可以在我們的社群腳本中找到免費的開源替代方案。
作者的說明
For instructions on how to access, send me a private message here on TradingView or message me using the contact information listed in my TradingView profile.
Public Telegram Group, t.me/algxtrading_public
VIP Membership Info: patreon.com/algxtrading/membership
VIP Membership Info: patreon.com/algxtrading/membership
免責聲明
這些資訊和出版物並非旨在提供,也不構成TradingView提供或認可的任何形式的財務、投資、交易或其他類型的建議或推薦。請閱讀使用條款以了解更多資訊。
僅限邀請腳本
僅作者批准的使用者才能訪問此腳本。您需要申請並獲得使用許可,通常需在付款後才能取得。更多詳情,請依照作者以下的指示操作,或直接聯絡loxx。
TradingView不建議在未完全信任作者並了解其運作方式的情況下購買或使用腳本。您也可以在我們的社群腳本中找到免費的開源替代方案。
作者的說明
For instructions on how to access, send me a private message here on TradingView or message me using the contact information listed in my TradingView profile.
Public Telegram Group, t.me/algxtrading_public
VIP Membership Info: patreon.com/algxtrading/membership
VIP Membership Info: patreon.com/algxtrading/membership
免責聲明
這些資訊和出版物並非旨在提供,也不構成TradingView提供或認可的任何形式的財務、投資、交易或其他類型的建議或推薦。請閱讀使用條款以了解更多資訊。