CapitalFlowsResearch: Returns Regime MapCapitalFlowsResearch: Returns Regime Map — Two-Asset Behaviour & Correlation Lens
CapitalFlowsResearch: Returns Regime Map is a two-asset regime overlay that shows how a primary market and a linked macro series are really moving together over short rolling windows. Instead of just eyeballing two separate charts, the tool classifies each bar into one of four states based on the combined direction of recent returns:
Up / Up
Up / Down
Down / Up
Down / Down
These states are calculated from aggregated, windowed returns (using configurable return definitions for each asset), then painted directly onto the price chart as background regimes. On top of that, the indicator monitors the correlation of the same return streams and can optionally tint periods where correlation sits within a user-defined “low-correlation” band—highlighting moments when the usual relationship between the two series is weak, unstable, or breaking down.
In practice, this turns the chart into a compact co-movement map: you can see at a glance whether price and rates (or any two chosen markets) are trending together, diverging in a meaningful way, or moving in choppy, low-conviction fashion. It’s especially powerful for macro traders who need to frame trades in terms of “risk asset vs. rates,” “index vs. volatility,” or similar pairs—while keeping the actual construction details of the regime logic abstracted.
Statistics

CapitalFlowsResearch: CB LevelsCapitalFlowsResearch: CB Levels — Policy Path Mapping for STIR & Rates Traders
CapitalFlowsResearch: CB Levels provides a structured, policy-anchored framework for interpreting short-term interest rate futures. Instead of treating STIR pricing as an abstract number, the indicator converts central bank settings—such as the official cash rate, expected hike/cut increments, and basis adjustments—into a clear ladder of explicit rate levels. These levels are then projected directly onto the price chart as horizontal reference bands.
The tool automatically builds a series of future policy steps (e.g., +25bp, +50bp, –25bp, etc.) based on user-defined increments and direction, allowing traders to visualise where the current contract sits relative to hypothetical central bank actions. By plotting settlement levels and multiple forward steps, the script creates a transparent “policy grid” that traders can anchor against when evaluating mispricings, risk/reward asymmetry, or scenario outcomes.
Discreet labels—placed periodically to avoid clutter—identify each policy step in bp terms, making the chart readable even when zoomed out. Whether the mode is set to Cuts or Hikes, the tool instantly recalibrates the entire ladder, offering a consistent structure for comparing different contracts or central bank paths.
In practice, CB Levels acts as a policy-path overlay for futures traders, helping them contextualise market pricing relative to central bank intent, quantify potential repricing ranges, and understand where key inflection levels lie—without revealing the underlying calculation methods that generate the steps.

CapitalFlowsResearch: Vol RangesCapitalFlowsResearch: Vol Ranges — Multi-Timeframe ATR Expansion Map
CapitalFlowsResearch: Vol Ranges creates a structured volatility “roadmap” by projecting expected price extensions across multiple timeframes using ATR-based ranges. Instead of relying on a single ATR reading, the tool pulls in higher-timeframe volatility measures—such as daily and monthly expansions—and uses them to build a set of reference levels that anchor the current market against where it should trade under normal volatility conditions.
The script does two things simultaneously:
Projects volatility-derived target bands
It computes a set of upper and lower expansion levels (e.g., +100%, +50%, –50%, –100%) around prior closing levels on different timeframes. These levels act as structural markers for expected movement, allowing traders to quickly recognise when price is behaving within typical bounds or pressing into statistically stretched territory.
Displays a live dashboard for interpretation
A fully configurable on-chart table displays:
Recent volatility readings
Today's reference ranges
Distance from current price to each expansion level
Whether today's movement is expanding or contracting relative to prior volatility
This gives traders a compact situational summary without cluttering the price chart.
Optional high-timeframe projection lines can also be plotted directly on the chart, updating once per new day or new month, making it easy to visually align intraday price action with broader volatility structure.
In practical terms, Vol Ranges functions as a multi-timeframe volatility compass—highlighting when markets are trading inside normal ranges, when they are beginning to stretch, and when they may be entering conditions supportive of momentum or reversal behaviour. All core mechanics remain abstracted, preserving the proprietary nature of the volatility framework.

CapitalFlowsResearch: CS CorrelationCapitalFlowsResearch: CS Correlation — Multi-Asset Correlation Radar
CapitalFlowsResearch: CS Correlation provides a real-time view of how closely a chosen “base” market is moving relative to a basket of other assets. Instead of relying on a single method, the tool allows you to transform each series (price, log-price, normalized score, or short-term returns) before correlation is calculated. This gives traders the flexibility to analyse relationships on the basis most relevant to their strategy—whether they care about trend alignment, return co-movement, or standardized behaviour.
Each comparison asset is evaluated independently using a rolling lookback window, producing a clean set of correlation lines that update bar-by-bar. The tool is deliberately modular: symbols can be switched on or off individually, and the chart remains uncluttered while still capturing broad cross-asset dynamics. A compact on-chart legend displays the latest correlation reading for each active symbol, making it easy to interpret at a glance.
Conceptually, the indicator helps highlight when normally-linked assets begin to diverge, when new relationships begin to strengthen, or when markets move into low-correlation regimes often associated with macro shifts, liquidity changes, or turning points. It functions as a correlation heatmap in time-series form, offering structural insight without exposing the underlying computation or weighting logic.

CapitalFlowsResearch: PEMA ThresholdCapitalFlowsResearch: PEMA Threshold — Forward Regime Projection
CapitalFlowsResearch: PEMA Threshold extends the logic of the standard PEMA framework by not only identifying when price is in an extended regime, but also calculating the exact price levels where the next regime flip would occur. Instead of waiting for a signal to trigger, the tool projects the thresholds forward in real time, showing traders the points at which the current regime would shift from positive to negative extension (or vice versa).
Conceptually, the script takes the behaviour of price around its moving equilibrium and determines how far price would need to travel for the underlying extension score to breach its upper or lower band. These projected “flip prices” can be displayed as guide lines or labelled directly on the chart, providing a live map of where key behavioural shifts would take place.
This transforms PEMA from a reactive overlay into an anticipatory one—helping traders plan entries, stops, and scenario paths with a clear understanding of where the market’s statistical pressure points sit, without exposing the underlying calculations.

Shezab AlgoLabs EMA Trend UtilityOverview
This tool is a clean and practical EMA trend utility built to help traders quickly understand market direction, trend regime, and momentum shifts. It plots a fast EMA and slow EMA using a branded color theme and highlights transitions between bullish and bearish conditions. The script also includes optional visual crossover markers to make regime changes easier to spot.
How it works
The relationship between the fast and slow EMA is used to classify the trend environment:
When the fast EMA is above the slow EMA, the market is considered in a bullish phase.
When the fast EMA is below the slow EMA, the market is considered in a bearish phase.
The script also provides optional:
Colored bars reflecting trend direction
Crossover labels to highlight momentum shifts
Background cloud to visually emphasize trending or neutral conditions
Optional alerts for crossover events
These visual features help traders recognize potential trend transitions without implying a complete trading system.
How to use it
This tool is designed as a supplemental decision aid. Traders can combine it with their preferred structure analysis, volume tools, oscillators, or confirmation methods. The crossover markers and alerts highlight shifts in trend behavior but are informational rather than mechanical buy/sell signals. Users should apply their own risk-management and entry criteria.
Originality
This script goes beyond a standard EMA by combining multiple elements into a single, cohesive trend-clarification tool:
• regime coloring
• optional cloud regions
• crossover markers
• visual dynamic styling using a unified aesthetic palette
It is not a mashup of existing scripts; all components are integrated specifically to support traders who prefer a simple-yet-clear visual framework for understanding trend behavior.

Position Size Tool [Riley]Automatically determine number of shares for an entry. Quantity based on a stop set at the low of day for long positions or a stop set at the high of the day for short positions. As well as inputs like account balance risk per trade. Also includes a user-defined maximum for percentage of daily dollar volume to consume with entry.

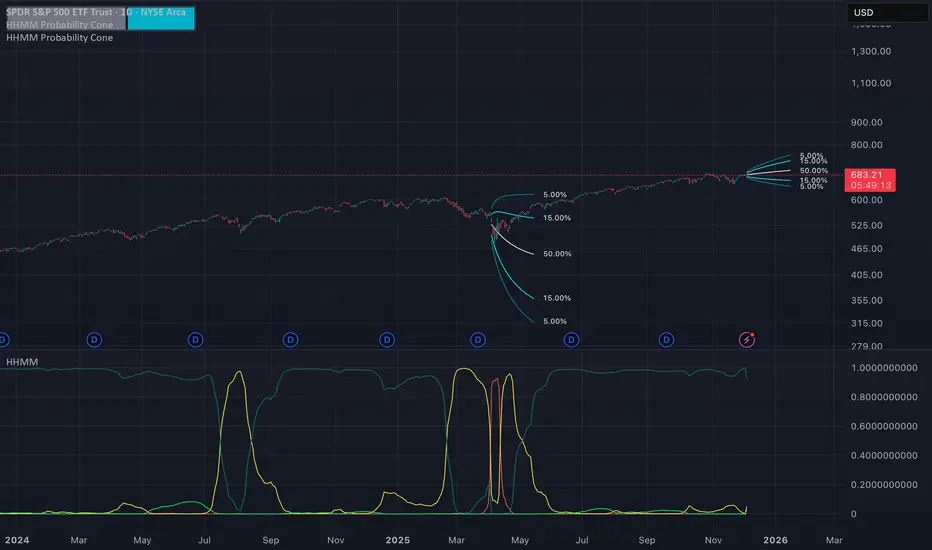
Hierarchical Hidden Markov Model - Probability Cone
The Hierarchical Hidden Markov Model - Probability Cone Indicator employs Hierarchical Hidden Markov Models for forecasting future price movements in financial markets. HHMMs are statistical tools that predict transitions between hidden states, such as different market regimes, based on observed data. This makes them valuable for understanding market behaviours and projecting future price trajectories. As discussed in the Hierarchical Hidden Markov Model indicator, HHMMs predict future states and their associated outputs based on the current state and model parameters. This tool is fundamentally very similar to the traditional HMM . The application of the HHMM for generating a probability cone forecast is therefore also fundamentally the same between HMM and HHMM. Despite their significant similarity I will go through the same fundamental examples of how probability cone is generated for the HHMM as I did for the HMM probability cone .
As you might know by now the probability cone indicator uses the knowledge about the current identified "state" or "regime" and with the help of transition probabilities, emission probabilities and initial probabilities generate a probabilistic forecast of the expected future price movements. To better understand the behind the Probability Cone we encourage you to use and learn about our free version of the Probability Cone as well as for even deeper understanding the Probability Cone Pro.
WHAT ARE REGIME DEPENDENT FORECASTS
We established that the indicator creates probabilistic forecasts of future price movements dependent on the current identified "state" or market "regime" via the Hidden Markov Model. In the image below we can see an example.
In this example we can see 4 different probability cones forecasting a 70% and 90% probability range (15% and 5% quantiles respectively). What you may notice is that the 4 probability cones look vastly different, despite using the same probability ranges as well as being generated from the same model trained on virtually the same data. What allows for this difference in the forecast, is conditioning the forecast on the current most likely identified state by the HHMM.
The first most cone is generating a forecast taking into account that the model identified the current market condition to be a extremely low in volatility this is a characteristic of the state identified by the light green coloured posterior probability. The second cone is significantly wider as well as has a negative drift, this is the case because that state identified by the red posterior probability is characterised by the most extreme volatility along with significant negative returns. The cone after that remains quite wide however is again associated with positive returns, this is characteristic of the state that the model identified via a high yelow coloured posterior probability. The last probability cone is again generated from a state that is characterised by quite low volatility albeit not the lowest. We can also see the state associated with that behaviour is identified by the high dark green posterior probability which is the highest at that time.
NOTE! Those are within sample forecasts, you can find more information on the difference between within sample model fit and out of sample prediction in the HHMM indicator description
This indicator also allows you to specify whether you wish to display probability based labels at the edges of the cone or whether you would prefer to display percent change based labels. With percent change labels you get the exact percentage value of the probabilistic increase or decrease of the price. See the example below
BARS BACK OFFSET vs DATE BASED OFFSET
The cones position can be offset by specifying the number of bars we wish to move it back similarly as with the rest of probability cone indicators. This indicator has however an additional, date based offset implemented. A user can therefore specify the position of the cone by specifying a date in the settings. The advantage of using the date based offset is that once it is turned on the user can also slide the cone up and down the chart with their mouse without having to manually adjust the date in the settings.
DIFFICULTIES WITH GENERATING FORECASTS (advanced):
The estimation of the probability cone, gets more difficult the more complex the model gets. A simple normal distribution probability cone can scale the distribution over time by simply multiplying the drift by the number of time steps and the volatility by the square root of time steps we wish to forecast for. More complex distributions often have to rely on mode advanced methods like convolutions, monte carlo or other kinds of approximations.
To estimate the probability cone forecast for the Hierarchial Hidden Markov Model, the indicator integrates two primary methodologies: Gaussian approximation and importance sampling. The Gaussian approximation is utilised for estimating the central 90% of future prices. This method provides a quick and efficient estimation within this central range, capturing the most likely price movements. The gaussian approximation will result in a forecast with an equal mean and variance as the true forecast, it will however not accurately reflect higher moments like skewness and kurtosis. For that reason the tail quantiles, which represent extreme price movements beyond the central range (90%), are estimated via importance sampling. This approach ensures a more accurate estimation of the skewness and kurtosis associated with extreme scenarios. While importance sampling leverages the flexibility of Monte Carlo as well as attempts to increase its efficiency by sampling from more precise areas of the distribution, the importance sampling may still underestimate most extreme quantiles associated with the lowest probabilities which is an inherent limitation of the indicator.
Example of gaussian approximation cone for probabilities above 5% (90% range):
Example of importance sampling cone for tail probabilities lower than 5% (beyond 90% range):
WARNING!
As per usual understand that the probabilities are estimations and best guesses based on the historical data and the patterns identified by the model and do not represent the true probability which is unknown in reality.
Settings:
- Source: Data source used for the model
- Forecast Period: Number of bars ahead for generating forecasts.
- Simulation Number: Number of Monte Carlo simulations to run in the case of importance sampling
-Body Probability: Specifies the inner range of the probability cone. The probability specifies the ammount of observations that are expected to fall outside of this range
- Tail Probability: Specifies the outter range of the probability cone. When this probability is under 5%, importance sampling will turn on
- Lock Cone: When ticked on, the cone will be locked at its current position.
- Offset Cone Based on Date: When ticked on, the position of the cone will be determined by the selected date.
- Offset: When "Offset Cone Based on Date" is turned off, you can use offset setting to specify the position of the cone projection.
- Date: When "Offset Cone Based on Date" is turned on, you can use the date setting to specify the date from which the forecast starts.
- Reestimate Model Every N Bars: This is especially useful if you wish to use the indicator on lower timeframes where model estimation might take longer than for the new datapoint to arrive. In that case you can specify after how many bars the model should be reestimated.
- Training Period: Length of historical data used to train the HMM.
- Expectation Maximization Iterations: Number of iterations for the EM algorithm.
- Cone Colors: Customizable colors for the probability cone, when approximation is on and when importance sampling is on
NY 8-11 Statistical Bias NQ 【Donkey】This indicator analyzes historical session patterns to predict directional bias during the NY 8:00-11:00 AM trading window for Micro NQ futures.
Simple Logic:
Monitors 3 sessions: Asian (20:00-02:00), London (02:00-08:00), NY (08:00-11:00)
Identifies current pattern based on: ranges, opening positions, and sweep behaviors
Searches database of 2.080 historical sessions for matching patterns
Displays statistical probability: "X% reached HIGH" vs "Y% reached LOW"
Shows expected drawdown levels for risk management
Example: If pattern shows "77% HIGH bias" → historically, 77 out of 100 similar sessions reached London high during NY 8-11 window.
Key Features
✅ Statistical Database:2.080 real sessions analyzed, 236 unique patterns
✅ 4-Level Pattern Matching: Finds best match with minimum 25 occurrences
✅ Live Bias Display: Shows HIGH% vs LOW% probability in real-time table
✅ Risk Management Zones: Visual drawdown levels (50%, 75%, 90%) + stop-loss suggestion
✅ No Repainting: Calculations made in real-time, no look-ahead bias
✅ Session Visualization: Color-coded boxes for Asian/London/NY ranges
How Pattern Matching Works
5 Components Analyzed:
Asian Range: Above/Below average
London Open: Above/Below Asian 50%
London Sweep: H, L, DH (double high→low), DL (double low→high), N (none)
London Range: Above/Below average
NY Open: Above/Below London 50%
Cascade Search (finds best available match):
Level 1: All 5 components (most specific)
Level 2: 4 components (drops London Range)
Level 3: 3 components (core pattern)
Level 4: 2 components (minimal pattern)
Validity: Only displays patterns with ≥25 historical occurrences.
Interpretation
Bias Table Shows:
Pattern match level (1-4) and historical count
Session characteristics (ranges, sweeps, positions)
TOTAL HIGH % = probability of reaching London high
TOTAL LOW % = probability of reaching London low
Bias strength: ⭐⭐⭐ STRONG (≥70%), ⭐⭐ MEDIUM (60-69%), ⭐ WEAK (<60%)
Drawdown Zones (for winning trades):
🟢 Green: 50% of winners stayed within this level
🟡 Yellow: 75% of winners stayed within this level
🟠 Orange: 90% of winners stayed within this level
🔴 Red Line: Suggested stop-loss (95th percentile + buffer)
Settings
Fully Customizable:
Timezone selection (auto-detects sessions correctly)
Minimum session threshold (default: 25)
Toggle boxes, lines, labels, drawdown zones
Complete color customization
Table size and position
Best Use Cases
✅ Optimal Setup:
Instrument: Micro NQ (MNQ) futures
Timeframe: Only 1-minute
Timezone: America/New_York
Historical data: 8+ years loaded
✅ Trading Approach:
Wait for pattern confirmation (≥25 sessions)
Prefer STRONG bias (≥70%) for higher confidence
Use drawdown zones for stop placement
Combine with price action confirmation
Avoid major news events (FOMC, NFP)
⚠️ Required Disclaimers
IMPORTANT RISK WARNINGS:
Past Performance ≠ Future Results: Historical statistics do NOT guarantee future outcomes
Not Financial Advice: Educational tool for statistical analysis only
Risk of Loss: Futures trading involves substantial risk of loss
No Guarantees: Individual trades WILL result in losses regardless of percentages shown
Requires Knowledge: Best for traders familiar with session analysis and risk management
Instrument-Specific: Optimized for Micro NQ - test before using elsewhere
Never risk more than you can afford to lose. Always use proper risk management.

Hidden Markov Model - Probability Cone
The Hidden Markov Model - Probability Cone Indicator employs Hidden Markov Models (HMMs) for forecasting future price movements in financial markets. HMMs are statistical tools that predict transitions between hidden states, such as different market regimes, based on observed data. This makes them valuable for understanding market behaviours and projecting future price trajectories. As discussed in the Hidden Markov Model indicator, HMMs predict future states and their associated outputs based on the current state and model parameters.
The probability cone indicator therefore uses the knowledge about the current identified "state" or "regime" and with the help of transition probabilities, emission probabilities and initial probabilities generate a probabilistic forecast of the expected future price movements. To better understand the behind the Probability Cone we encourage you to use and learn about our free version of the Probability Cone as well as for even deeper understanding the Probability Cone Pro.
WHAT ARE REGIME DEPENDENT FORECASTS
As mentioned above the indicator creates probabilistic forecasts of future price movements dependent on the current identified "state" or market "regime" via the Hidden Markov Model. In the image below we can see an example.
In this example we can see 3 different probability cones forecasting a 70% and 90% probability range (15% and 5% quantiles respectively). What you may notice is that the 3 probability cones look vastly different, despite using the same probability ranges as well as being generated from the same model trained on virtually the same data. What allows for this difference in the forecast is conditioning the forecast on the current most likely identified state by the HMM.
The first most wide cone is generating a forecast taking into account that the model identified the current market condition to be a very volatile which is a characteristic of the state identified by the orange coloured posterior probability. The second cone is significantly more narrow as that state identified by the purple posterior probability is characterised by lower volatility. Nevertheless, the last probability cone is generated from the state that is characterised by the lowest volatility, we can also see the light blue posterior probability to be the highest at that time.
The indicator also allows you to specify whether you wish to display probability based labels at the edges of the cone or whether you would prefer to display percent change based labels. With percent change labels you get the exact percentage value of the probabilistic increase or decrease of the price. See the example below
BARS BACK OFFSET vs DATE BASED OFFSET
The cones position can be offset by specifying the number of bars we wish to move it back similarly as with the rest of probability cone indicators. This indicator has however an additional, date based offset implemented. A user can therefore specify the position of the cone by specifying a date in the settings. The advantage of using the date based offset is that once it is turned on the user can also slide the cone up and down the chart with their mouse without having to manually adjust the date in the settings.
DIFFICULTIES WITH GENERATING FORECASTS (advanced):
The estimation of the probability cone, gets more difficult the more complex the model gets. A simple normal distribution probability cone can scale the distribution over time by simply multiplying the drift by the number of time steps and the volatility by the square root of time steps we wish to forecast for. More complex distributions often have to rely on mode advanced methods like convolutions, monte carlo or other kinds of approximations.
To estimate the probability cone forecast for the Hidden Markov Model, the indicator integrates two primary methodologies: Gaussian approximation and importance sampling. The Gaussian approximation is utilized for estimating the central 90% of future prices. This method provides a quick and efficient estimation within this central range, capturing the most likely price movements. The gaussian approximation will result in a forecast with an equal mean and variance as the true forecast, it will however not accurately reflect higher moments like skewness and kurtosis. For that reason the tail quantiles, which represent extreme price movements beyond the central range (90%), are estimated via importance sampling. This approach ensures a more accurate estimation of the skewness and kurtosis associated with extreme scenarios. While impoortance sampling leverages the flexibility of monte carlo as well as attempts to increase its efficiency by sampling from more precise areas of the distribution, the importance sampling may still underestimate most extreme quantiles associated with the lowest probabilties which is an inherent limitation of the indicator.
Example of gaussian approximation cone for probabilities above 5% (90% range):
Example of importance sampling cone for tail probabilities lower than 5% (beyond 90% range):
WARNING!
As per usual understand that the probabilities are estimations and best guesses based on the historical data and the patterns identified by the model and do not represent the true probability which is unknown in reality.
Settings:
- Source: Data source used for the model
- Forecast Period: Number of bars ahead for generating forecasts.
- Simulation Number: Number of Monte Carlo simulations to run in the case of importance sampling
-Body Probability: Specifies the inner range of the probability cone. The probability specifies the ammount of observations that are expected to fall outside of this range
- Tail Probability: Specifies the outter range of the probability cone. When this probability is under 5%, importance sampling will turn on
- Lock Cone: When ticked on, the cone will be locked at its current position.
- Offset Cone Based on Date: When ticked on, the position of the cone will be determined by the selected date.
- Offset: When "Offset Cone Based on Date" is turned off, you can use offset setting to specify the position of the cone projection.
- Date: When "Offset Cone Based on Date" is turned on, you can use the date setting to specify the date from which the forecast starts.
- Reestimate Model Every N Bars: This is especially useful if you wish to use the indicator on lower timeframes where model estimation might take longer than for the new datapoint to arrive. In that case you can specify after how many bars the model should be reestimated.
- Training Period: Length of historical data used to train the HMM.
- Expectation Maximization Iterations: Number of iterations for the EM algorithm.
- Cone Colors: Customizable colors for the probability cone, when approximation is on and when importance sampling is on

Watermark | Bar Time | Average Daily RangeMulti Info Panel & Watermark
Multi Info Panel & Watermark is a utility indicator that displays several pieces of chart information in a single, customizable panel. It is designed to support intraday and swing analysis by making key data—such as symbol details, date, and average daily range—easy to see at a glance, as well as providing simple tools for notes and backtesting.
Features
Watermark / Custom Note
Optional text overlay that can be used as a watermark or personal note.
Can display a strategy name, reminder, or any other user-defined label on the chart.
Ticker Info
Shows information about the currently active symbol on the chart (for example, symbol name and other basic details depending on the inputs).
Helps keep track of which market or pair is being analyzed, especially when using multiple charts.
Current Date
Displays the current date directly on the chart.
Useful for screenshots, journaling, and documenting analysis.
Average Daily Range (ADR)
Calculates the average daily range of the active symbol over a user-defined number of recent days.
Helps visualize how much price typically moves in a day, which can support position sizing, target setting, or volatility awareness within your own trading approach.
Open Bar Time Marker
Marks the open time of a selected bar (for example, a session open or a specific reference bar).
Primarily intended as a visual aid for manual backtesting and reviewing historical price action.
Usage
Use the watermark and ticker info to keep your charts labeled and organized.
Refer to the ADR readout to understand typical daily volatility of the instrument you are studying.
Use the date and open bar time marker when creating screenshots, trade journals, or when replaying historical sessions for review.
This script does not generate trading signals and does not guarantee any performance or results. It is provided solely as an informational and visualization tool. Always combine it with your own analysis, risk management, and decision-making. Nothing in this indicator or description should be considered financial advice.

Probability Cone ProProbability Cone Pro is based on the Expected Move Pro . While Expected Move only shows the historical value band on every bar, probability cone extend the period in the future and plot a cone or curve shape of the probable range. It plots the range from bar 1 all the way to any specified number of bars up to 1000.
Probability Cone Pro is an upgraded version of the Probability Cone indicator that uses a Normal Distribution to model the returns. This newer version uses a maximum likelihood estimation for Asymmetric Laplace distribution parameters. Asymmetric Laplace distribution takes into account fatter tails and volatility clustering during low volatility. So it will be thinner in the body (eg: <70% range) and fatter in the tails (>95% range) which fits the stock return better. Despite a better fit users should not blindly follow the probabilities derived from the indicator and should understand that these are very precise estimations of probability based on historical data, not the true probability which is in reality unknown.
When we compare the more peaked asymmetric laplace to the bell curve shaped normal distribution we can see that the asymmetric laplace fits the empirical data (blue histogram) significantly better. The fit is improved in both the body (middle peaked part) as well as in the fatter tails (more of extreme occurrences far from the center)
The area of probability range is based on an inverse cumulative distribution function. The inverse cumulative distribution gives the range of price for given input probability. People can adjust the range by adjusting the input probability in the settings. The entered probability will be shown at the edges of the cone when the “show probability” setting is on.
The indicator allows for specifying the probability for 2 quantiles on each side of the distribution , therefore 4 distinct probability values. The exact probability input is another distinction compared to the Normal Distribution based Probability Cone, in which the probability range is determined by the input of a standard deviation. Additionally now the displayed labels at the edges of the probability cone no longer correspond to the total number of outcomes that are expected to occur within the specific range, instead we chose to display the inverse which is the probability of outcomes outside of the specified range. See comparison below:
Probability cone pro with 68% and 95% ranges also defined by 16% and 2.5% probabilities at the tails on both sides:
Normal Probability cone with 68% and 95% ranges defined by 1st and 2nd standard deviation
SETTINGS:
Bars Back : Number of bars the cone is offset by.
Forecast Bar: Number of bars we forecast the cone for in the future.
Lock Cone : Specify whether we wish t lock the cone to the current bar, so it does not move when new bars arrive.
Show Probability : Specify whether you wish to show the probability labels at the edges of the cone.
Source : Source for computation of log returns whose distribution we forecast
Drift : Whether to take into account the drift in returns or assume 0 mean for the distribution.
Period: The sampling period or lookback for both the drift and the volatility estimation (full distribution estimation).
Up/Down Probabilities: 4 distinct probabilities are specified, 2 for the upper and 2 for the lower side of the distribution.

Expected Move ProExpected Move is the amount that an asset is predicted to increase or decrease from its current price, based on the current levels of volatility.
This Expected Move Pro indicator uses a maximum likelihood estimation for Asymmetric Laplace distribution parameters, and is an upgrade from the regular Expected Move indicator that uses a Normal Distribution. The use of the Asymmetric Laplace distribution ensures a probability range more accurate than the more common expected moves based on a normal distribution assumption for returns. Asymmetric Laplace distribution takes in account fatter tails and volatility clustering during low volatility. So it will be thinner in the body (eg: <70% range) and fatter in the tails (>95% range) which fits the stock return better.
When we compare the more peaked asymmetric laplace to the bell curve shaped normal distribution we can see that the asymmetric laplace fits the empirical data (blue histogram) significantly better. The fit is improved in both the body (middle peaked part) as well as in the fatter tails (more of extreme occurrences far from the center)
EXPECTED MOVE PROBABILITY:
In the expected move settings, the user can specify the range probability they wish to display. In a normal distribution a 1 standard deviation range corresponds to a range within which just under 70% of observations fall. So to specify a 70% probability range one would set 15% probability for both the upper and lower range.
For the more extreme ranges a two tail function is used so the user can only specify one probability. When 5% probability is specified the range will cover 95% and on each side of the range the probability of an occurence that extreme will be 2.5%. In the above Image we can see two tail probabilities specified at 5% and 1%, covering the 95% and 99% ranges respectively.
The indicator also allows for multi timeframe usecases. One can request a daily or perhaps even weekly expected move on an hourly chart, like we see below.
SETTINGS:
Resolution: Specify the timeframe and if you want to use the multi timeframe functionality.
Real Time : Do you wish the expected move to adjust with the current open price or do you wish it to be a forecast based on the yesterdays close. If latter, keep it OFF.
Sample Size : Lookback or the number of bars we sample in the calculation.
Optimization : Keep it on for speed purposes, only slightly higher precision will be achieved without optimization.
Probabilities: One tail - left and right, specify probability for each side of the range, two tail - single probability split in half for each side of the range
Center : Displays the central line which is the central tendency of a distribution / the median
Hide History : Hides expected moves and only the expected move for the current bar remains.
Plot Style Settings : One can adjust the line styles, box styles as well as width and transparency.

Probability Cone█ Overview:
Probability Cone is based on the Expected Move . While Expected Move only shows the historical value band on every bar, probability panel extend the period in the future and plot a cone or curve shape of the probable range. It plots the range from bar 1 all the way to bar 31.
In this model, we assume asset price follows a log-normal distribution and the log return follows a normal distribution.
Note: Normal distribution is just an assumption; it's not the real distribution of return.
The area of probability range is based on an inverse normal cumulative distribution function. The inverse cumulative distribution gives the range of price for given input probability. People can adjust the range by adjusting the standard deviation in the settings. The probability of the entered standard deviation will be shown at the edges of the probability cone.
The shown 68% and 95% probabilities correspond to the full range between the two blue lines of the cone (68%) and the two purple lines of the cone (95%). The probabilities suggest the % of outcomes or data that are expected to lie within this range. It does not suggest the probability of reaching those price levels.
Note: All these probabilities are based on the normal distribution assumption for returns. It's the estimated probability, not the actual probability.
█ Volatility Models :
Sample SD : traditional sample standard deviation, most commonly used, use (n-1) period to adjust the bias
Parkinson : Uses High/ Low to estimate volatility, assumes continuous no gap, zero mean no drift, 5 times more efficient than Close to Close
Garman Klass : Uses OHLC volatility, zero drift, no jumps, about 7 times more efficient
Yangzhang Garman Klass Extension : Added jump calculation in Garman Klass, has the same value as Garman Klass on markets with no gaps.
about 8 x efficient
Rogers : Uses OHLC, Assume non-zero mean volatility, handles drift, does not handle jump 8 x efficient.
EWMA : Exponentially Weighted Volatility. Weight recently volatility more, more reactive volatility better in taking account of volatility autocorrelation and cluster.
YangZhang : Uses OHLC, combines Rogers and Garmand Klass, handles both drift and jump, 14 times efficient, alpha is the constant to weight rogers volatility to minimize variance.
Median absolute deviation : It's a more direct way of measuring volatility. It measures volatility without using Standard deviation. The MAD used here is adjusted to be an unbiased estimator.
You can learn more about each of the volatility models in out Historical Volatility Estimators indicator.
█ How to use
Volatility Period is the sample size for variance estimation. A longer period makes the estimation range more stable less reactive to recent price. Distribution is more significant on larger sample size. A short period makes the range more responsive to recent price. Might be better for high volatility clusters.
People usually assume the mean of returns to be zero. To be more accurate, we can consider the drift in price from calculating the geometric mean of returns. Drift happens in the long run, so short lookback periods are not recommended.
The shape of the cone will be skewed and have a directional bias when the length of mean is short. It might be more adaptive to the current price or trend, but more accurate estimation should use a longer period for the mean.
Using a short look back for mean will make the cone having a directional bias.
When we are estimating the future range for time > 1, we typically assume constant volatility and the returns to be independent and identically distributed. We scale the volatility in term of time to get future range. However, when there's autocorrelation in returns( when returns are not independent), the assumption fails to take account of this effect. Volatility scaled with autocorrelation is required when returns are not iid. We use an AR(1) model to scale the first-order autocorrelation to adjust the effect. Returns typically don't have significant autocorrelation. Adjustment for autocorrelation is not usually needed. A long length is recommended in Autocorrelation calculation.
Note: The significance of autocorrelation can be checked on an ACF indicator.
ACF
Time back settings shift the estimation period back by the input number. It's the origin of when the probability cone start to estimation it's range.
E.g., When time back = 5, the probability cone start its prediction interval estimation from 5 bars ago. So for time back = 5 , it estimates the probability range from 5 bars ago to X number of bars in the future, specified by the Forecast Period (max 1000).
█ Warnings:
People should not blindly trust the probability. They should be aware of the risk evolves by using the normal distribution assumption. The real return has skewness and high kurtosis. While skewness is not very significant, the high kurtosis should be noticed. The Real returns have much fatter tails than the normal distribution, which also makes the peak higher. This property makes the tail ranges such as range more than 2SD highly underestimate the actual range and the body such as 1 SD slightly overestimate the actual range. For ranges more than 2SD, people shouldn't trust them. They should beware of extreme events in the tails.
The uncertainty in future bars makes the range wider. The overestimate effect of the body is partly neutralized when it's extended to future bars. We encourage people who use this indicator to further investigate the Historical Volatility Estimators , Fast Autocorrelation Estimator , Expected Move and especially the Linear Moments Indicator .
The probability is only for the closing price, not wicks. It only estimates the probability of the price closing at this level, not in between.

EMA + Sessions + RSI Strategy v1.0A professional trading strategy that combines multiple technical indicators for high-probability entries. This system uses EMA crossovers, RSI zone filtering, and trend confirmation to identify optimal trading opportunities while managing risk with advanced position management tools.
Key Features:
✅ Dual Entry Signals (EMA21 + EMA100 crossover conditions)
✅ Trend Filter EMA750 (trade only with the major trend)
✅ Complete Risk Management (SL 1%, TP 3% default)
✅ Trailing Stop & Breakeven (maximize profits, protect capital)
✅ Compact Statistics Table (real-time performance metrics)
✅ RSI & Session Filters (avoid low-probability setups)
✅ Optional Pyramiding (scale into winning positions)
Perfect for swing trading and trend-following on any timeframe. Fully customizable to match your trading style.

Position Size Calculator + Live R/R Panel — SMC/ICT (@PueblaATH)Position Size + Live R/R Panel — SMC/ICT (@PueblaATH)
Position Size + Live R/R Panel — SMC/ICT (@PueblaATH) is a professional-grade risk management and execution module built for Smart Money Concepts (SMC) and ICT Traders who require accurate, repeatable, institution-style trade planning.
This tool delivers precise position sizing, R:R modeling, leverage and margin projections, fee-adjusted PnL outcomes, and real-time execution metrics—all directly on the chart. Optimized for crypto, forex, and futures, it provides scalpers, day traders, and swing traders with the clarity needed to execute high-quality trades with confidence and consistency.
What the Indicator Does
Institutional Position Sizing Engine
Calculates position size based on account balance, % risk, and SL distance.
Supports custom minimum lot size rounding across crypto, FX, indices, and derivatives.
Intelligent direction logic (Auto / Long / Short) based on SMC/ICT structure.
Advanced Risk/Reward & Profit Modeling
Real-time R:R ratio using actual rounded position size.
Live PnL readout that updates with price movements.
Gross & net profit projections with full fee deduction.
Execution Planning with Draggable Levels
Entry, SL, and TP levels fully draggable for fast scenario modeling.
Automatic projected lines backward/forward with clean label alignment.
TP and SL tags include % movement from Entry, ideal for SMC/ICT journaling.
Precise modeling of real exchange fee structures
Maker fee per side
Taker fee per side
Mixed fee modes (Maker entry, Taker exit, Average, etc.)
Leverage & Margin Forecasting
Margin requirements displayed for 3 customizable leverage settings.
Helps traders understand capital commitment before executing the trade.
Useful for futures, crypto perps, and CFD setups.
Clean HUD Panel for Rapid Decision-Making
A full professional trading panel displays:
Target & actual risk
Position size
Entry / SL / TP
TP/SL percentage distance
Gross profit
Net profit (after fees)
Fees @ TP and @ SL
Live PnL
Margin requirements
Optimized for SMC & ICT Workflows
Perfect for traders using:
Breakers, FVGs, OBs
Liquidity sweeps
Session models
Precision entries (OTE, Displacement, Rebalancing)
Leverage-based execution (crypto perps, futures)
How to Use It
Attach the indicator to your chart.
Set account balance, risk %, fee model, and leverage presets.
Drag Entry, SL, and TP to shape the setup.
View instant calculations of: Position size; R:R; Net PnL after fees; Margin required
Use it as your pre-trade checklist & execution model.
Originality & Credits
This script is an original creation by @PueblaATH, released under the MPL 2.0 license.
It does not copy, modify, or repackage any existing TradingView code.
All logic—including the fee engine, margin calculator, responsive HUD, dynamic risk model, and visual execution system—is authored specifically for this indicator.



Yesterday Low LineTraces a red dotted line on the low of yesterdays session for the present graph - and extends into the future

ORB Algo - BitcoinGENERAL SUMMARY
We present our new ORB Algo indicator! ORB stands for "Opening Range Breakout," a common trading strategy. The indicator can analyze the market trend in the current session and generate Buy/Sell, Take Profit, and Stop Loss signals. For more information about the indicator's analysis process, you can read the “How Does It Work?” section of the description.
Features of the new ORB Algo indicator:
Buy/Sell Signals
Up to 3 Take Profit Signals
Stop Loss Signals
Buy/Sell, Take Profit, and Stop Loss Alerts
Fully Customizable Algorithm
Session Control Panel
Backtesting Control Panel
HOW DOES IT WORK?
This indicator works best on the 1-minute timeframe. The idea is that the trend of the current session can be predicted by analyzing the market for a period of time after the session begins. However, each market has its own dynamics, and the algorithm will require fine-tuning to achieve the best possible performance. For this reason, we implemented a Backtesting Panel that shows the past performance of the algorithm on the current ticker with your current settings. Always remember that past performance does not guarantee future results.
Here are the steps of the algorithm explained briefly:
The algorithm follows and analyzes the first 30 minutes (adjustable) of the session.
Then, it checks for breakouts above or below the opening range high or low.
If a breakout occurs in either direction, the algorithm will look for retests of the breakout. Depending on the sensitivity setting, there must be 0 / 1 / 2 / 3 failed retests for the breakout to be considered reliable.
If the breakout is reliable, the algorithm will issue an entry signal.
After entering the position, the algorithm will wait for the Take-Profit or Stop-Loss zones to be reached and send a signal if any of them occur.
If you wonder how the indicator determines the Take-Profit and Stop-Loss zones, you can check the Settings section of the description.
UNIQUENESS
Although some indicators display the opening range of the session, they often fall short in features such as indicating breakouts, entries, and Take-Profit & Stop-Loss zones. We are also aware that different markets have different dynamics, and tuning the algorithm for each market is crucial for better results. That is why we decided to make the algorithm fully customizable.
In addition to this, our indicator includes a detailed backtesting panel so you can see the past performance of the algorithm on the current ticker. While past performance does not guarantee future results, we believe that a backtesting panel is necessary to fine-tune the algorithm. Another strength of the indicator is that it offers multiple options for detecting Take-Profit and Stop-Loss zones, allowing traders to choose the one that fits their style best.
⚙️ SETTINGS
Keep in mind that the best timeframe for this indicator is the 1-minute timeframe.
TP = Take-Profit
SL = Stop-Loss
EMA = Exponential Moving Average
OR = Opening Range
ATR = Average True Range
1. Algorithm
ORB Timeframe → This setting determines how long the algorithm will analyze the market after a new session begins before issuing signals. It is important to experiment with this option and find the optimal setting for the current ticker. More volatile stocks will require a higher value, while more stable stocks can use a shorter one.
Sensitivity → Determines how many failed retests are required before taking an entry. Higher sensitivity means fewer retests are needed to consider the breakout reliable.
If you believe the ticker makes strong moves after breaking out, use high sensitivity.
If the ticker doesn’t define the trend immediately after a breakout, use low sensitivity.
(High = 0 Retests, Medium = 1 Retest, Low = 2 Retests, Lowest = 3 Retests)
Breakout Condition → Determines how the algorithm detects breakouts.
Close = The bar must close above OR High for bullish breakouts or below OR Low for bearish breakouts.
EMA = The bar’s EMA must be above/below the OR Lines instead of relying on the closing price.
TP Method → Method used to determine TP zones.
Dynamic = Searches for the bar where price stops following the current trend and reverses. It uses an EMA, and when the bar’s close crosses the EMA, a TP is placed.
ATR = Determines TP zones before the trade happens, using the ATR of the entry bar. This option also displays the TP zones on the ORB panel.
→ The Dynamic method generally performs better, while the ATR method is safer and more conservative.
EMA Length → Sets the length of the EMA used in both the Dynamic TP method and the “EMA Breakout Condition.” The default value usually performs well, but you can experiment to find the optimal length for the current ticker.
Stop-Loss → Defines where the SL zone will be placed.
Safer = SL is placed closer to OR High in bullish entries and closer to OR Low in bearish entries.
Balanced = SL is placed in the middle of OR High & OR Low.
Risky = SL is placed farther away, giving more room for movement.
Adaptive SL → Activates only if the first TP zone is reached.
Enabled = After the 1st TP hits, SL moves to the entry price, making the position risk-free.
Disabled = SL never changes.

RS Rating Multi-TimeframeRS Rating Multi-Timeframe (IBD-Style Relative Strength)
Short Description:
IBD-style Relative Strength Rating (1-99) comparing any stock's performance vs the S&P 500 across multiple timeframes.
Full Description:
Overview
This indicator calculates an IBD-style Relative Strength (RS) Rating that measures a stock's price performance relative to the S&P 500 over the past 12 months. The rating scale ranges from 1 (weakest) to 99 (strongest), telling you how a stock ranks against all other stocks in terms of relative performance.
How It Works
The RS Rating uses a weighted formula based on quarterly performance:
Last 63 days (1 quarter): 40% weight
Last 126 days (2 quarters): 20% weight
Last 189 days (3 quarters): 20% weight
Last 252 days (4 quarters): 20% weight
This weighting emphasizes recent performance while still accounting for longer-term strength.
Rating Interpretation
90-99 (Elite): Top 10% of all stocks - exceptional relative strength
80-89 (Excellent): Top 20% - strong leadership candidates
50-79 (Average): Middle of the pack
30-49 (Below Average): Underperforming the market
1-29 (Weak): Bottom 30% - avoid or consider shorting
Features
Multi-Timeframe: Works on any timeframe from 1-hour to weekly (always uses daily data for calculation)
Moving Average: Optional EMA or SMA of the RS Rating to smooth signals
Visual Zones: Color-coded zones for quick identification of strength/weakness
Signal Markers: Triangles appear when RS crosses key levels (80 and 30)
Info Table: Displays current RS Rating, change, MA value, and raw score
Alerts: Built-in alerts for key crossover events
Settings
Show Moving Average: Toggle MA line on/off
MA Length: Period for the moving average (default: 10)
MA Type: Choose between EMA or SMA
Benchmark Index: Change the comparison index (default: SP:SPX)
Show Rating Table: Toggle the info table on/off
How To Use
Buy candidates: Look for stocks with RS Rating above 80, ideally rising
Avoid: Stocks with RS Rating below 30 or falling rapidly
Confirmation: Use RS above its moving average as additional confirmation
Divergence: Watch for RS making new highs before price (bullish) or new lows before price (bearish)
Credits
RS Rating calculation methodology inspired by Investor's Business Daily (IBD) and adapted from Fred6724's RS Rating script. Percentile calibration based on analysis of ~6,600 US stocks.
Tags: relative strength, RS rating, IBD, momentum, CAN SLIM, benchmark, SPX, market leaders, stock ranking
Category: Relative Strength

PoC Migration Map [BackQuant]PoC Migration Map
A volume structure tool that builds a side volume profile, extracts rolling Points of Control (PoCs), and maps how those PoCs migrate through time so you can see where value is moving, how volume clusters shift, and how that aligns with trend regime.
What this is
This indicator combines a classic volume profile with a segmented PoC trail. It looks back over a configurable window, splits that window into bins by price, and shows you where volume has concentrated. On top of that, it slices the lookback into fixed bar segments, finds the local PoC in each segment, and plots those PoCs as a chain of nodes across the chart.
The result is a "migration map" of value:
A side volume profile that shows how volume is distributed over the recent price range.
A sequence of PoC nodes that show where local value has been accepted over time.
Lines that connect those PoCs to reveal the path of value migration.
Optional trend coloring based on EMA 12 and EMA 21, so each PoC also encodes trend regime.
Used together, this gives you a structural read on where the market has actually traded size, how "value" is moving, and whether that movement is aligned or fighting the current trend.
Core components
Lookback volume profile - a side histogram built from all closes and volumes in the chosen lookback window.
Segmented PoC trail - rolling PoCs computed over fixed bar segments, plotted as nodes in time.
Trend heatmap - optional color mapping of PoC nodes using EMA 12 versus EMA 21.
PoC labels - optional labels on every Nth PoC for easier reading and referencing.
How it works
1) Global lookback and binning
You choose:
Lookback Bars - how far back to collect data.
Number of Bins - how finely to split the price range.
The script:
Finds the highest high and lowest low in the lookback.
Computes the total price range and divides it into equal binCount slices.
Assigns each bar's close and volume into the appropriate price bin.
This creates a discretized volume distribution across the entire lookback.
2) Side volume profile
If "Show Side Profile" is enabled, a right-hand volume profile is drawn:
Each bin becomes a horizontal bar anchored at a configurable "Right Offset" from the current bar.
The horizontal width of each bar is proportional to that bin's volume relative to the maximum volume bin.
Optionally, volume values and percentages are printed inside the profile bars.
Color and transparency are controlled by:
Base Profile Color and its transparency.
A gradient that uses relative volume to modulate opacity between lower volume and higher volume bins.
Profile Width (%) - how wide the maximum bin can extend in bars.
This gives you an at-a-glance view of the volume landscape for the chosen lookback window.
3) Segmenting for PoC migration
To build the PoC trail, the lookback is divided into segments:
Bars per Segment - bars in each local cluster.
Number of Segments - how many segments you want to see back in time.
For each segment:
The script uses the same price bins and accumulates volume only from bars in that segment.
It finds the bin with the highest volume in that segment, which is the local PoC for that segment.
It sets the PoC price to the center of that bin.
It finds the "mid bar" of the segment and places the PoC node at that time on the chart.
This is repeated for each segment from older to newer, so you get a chain of PoCs that shows how local value has migrated over time.
4) Trend regime and color coding
The indicator precomputes:
EMA 12 (Fast).
EMA 21 (Slow).
For each PoC:
It samples EMA 12 and EMA 21 at the mid bar of that segment.
It computes a simple trend score as fast EMA minus slow EMA.
If trend heatmap is enabled, PoC nodes (and the lines between them) are colored by:
Trend Up Color if EMA 12 is above EMA 21.
Trend Down Color if EMA 12 is below EMA 21.
Trend Flat Color if they are roughly equal.
If the trend heatmap is disabled, PoC color is instead based on PoC migration:
If the current PoC is above the previous PoC, use the Up PoC Color.
If the current PoC is below the previous PoC, use the Down PoC Color.
If unchanged, use the Flat PoC Color.
5) Connecting PoCs and labels
Once PoC prices and times are known:
Each PoC is connected to the previous one with a dotted line, using the PoC's color.
Optional labels are placed next to every Nth PoC:
Label text uses a simple "PoC N" scheme.
Label background uses a configurable label background color.
Label border is colored by the PoC's own color for visual consistency.
This turns the PoCs into a visual path that can be read like a "value trajectory" across the chart.
What it plots
When fully enabled, you will see:
A right-sided volume profile for the chosen lookback window, built from volume by price.
Colored horizontal bars representing each price bin's relative volume.
Optional volume text showing each bin's volume and its percentage of the profile maximum.
A series of PoC nodes spaced across the chart at the mid point of each segment.
Dotted lines connecting those PoCs to show the migration path of value.
Optional PoC labels at each Nth node for easier reference.
Color-coding of PoCs and lines either by EMA 12 / 21 trend regime or by up/down PoC drift.
Reading PoC migration and market pressure
Side profile as a pressure map
The side profile shows where trading has been most active:
Thick, opaque bars represent high volume zones and possible high interest or acceptance areas.
Thin, faint bars represent low volume zones, potential rejection or transition areas.
When price trades near a high volume bin, the market is sitting on an area of prior acceptance and size.
When price moves quickly through low volume bins, it often does so with less friction.
This gives you a static map of where the market has been willing to do business within your lookback.
PoC trail as a value migration map
The PoC chain represents "where value has lived" over time:
An upward sloping PoC trail indicates value migrating higher. Buyers have been willing to transact at increasingly higher prices.
A downward sloping trail indicates value migrating lower and sellers pushing the center of mass down.
A flat or oscillating trail indicates balance or rotational behaviour, with no clear directional acceptance.
Taken together, you can interpret:
Side profile as "where the volume mass sits", a static pressure field.
PoC trail as "how that mass has moved", the dynamic path of value.
Trend heatmap as a regime overlay
When PoCs are colored by the EMA 12 / 21 spread:
Green PoCs mark segments where the faster EMA is above the slower EMA, that is, a local uptrend regime.
Red PoCs mark segments where the faster EMA is below the slower EMA, that is, a local downtrend regime.
Gray PoCs mark flat or ambiguous trend segments.
This lets you answer questions like:
"Is value migrating higher while the trend regime is also up?" (trend confirming value).
"Is value migrating higher but most PoCs are red?" (value against the prevailing trend).
"Has value started to roll over just as PoCs flip from green to red?" (early regime transition).
Key settings
General Settings
Lookback Bars - how many bars back to use for both the global volume profile and segment profiles.
Number of Bins - how many price bins to split the high to low range into.
Profile Settings
Show Side Profile - toggle the right-hand volume profile on or off.
Profile Width (%) - how wide the largest volume bar is allowed to be in terms of bars.
Base Profile Color - the starting color for profile bars, with transparency.
Show Volume Values - if enabled, print volume and percent for each non-zero bin.
Profile Text Color - color for volume text inside the profile.
PoC Migration Settings
Show PoC Migration - toggle the PoC trail plotting.
Bars per Segment - the number of bars contained in each segment.
Number of Segments - how many segments to build backwards from the current bar.
Horizontal Spacing (bars) - spacing between PoC nodes when drawn. (Used to separate PoCs horizontally.)
Label Every Nth PoC - draw labels at every Nth PoC (0 or 1 to suppress labels).
Right Offset (bars) - horizontal offset to anchor the side profile on the right.
Up PoC Color - color used when a PoC is higher than the previous one, if trend heatmap is off.
Down PoC Color - color used when a PoC is lower than the previous one, if trend heatmap is off.
Flat PoC Color - color used when the PoC is unchanged, if trend heatmap is off.
PoC Label Background - background color for PoC labels.
Trend Heatmap Settings
Color PoCs By Trend (EMA 12 / 21) - when enabled, overrides simple up/down coloring and uses EMA-based trend colors.
Fast EMA - length for the fast EMA.
Slow EMA - length for the slow EMA.
Trend Up Color - color for PoCs in a bullish EMA regime.
Trend Down Color - color for PoCs in a bearish EMA regime.
Trend Flat Color - color for neutral or flat EMA regimes.
Trading applications
1) Value migration and trend confirmation
Use the PoC path to see if value is following price or lagging it:
In a healthy uptrend, price, PoCs, and trend regime should all lean higher.
In a weakening trend, price may still move up, but PoCs flatten or start drifting lower, suggesting fewer participants are accepting the new highs.
In a downtrend, persistent downward PoC migration confirms that sellers are winning the value battle.
2) Identifying acceptance and rejection zones
Combine the side profile with PoC locations:
High volume bins near clustered PoCs mark strong acceptance zones, good areas to watch for re-tests and decision points.
PoCs that quickly jump across low volume areas can indicate rejection and fast repricing between value zones.
High volume zones with mixed PoC colors may signal balance or prolonged negotiation.
3) Structuring entries and exits
Use the map to refine trade location:
Fade trades against value migration are higher risk unless you see clear signs of exhaustion or regime change.
Pullbacks into prior PoC zones in the direction of the current PoC slope can offer higher quality entries.
Stops placed beyond major accepted zones (clusters of PoCs and high volume bins) are less likely to be hit by random noise.
4) Regime transitions
Watch how PoCs behave as the EMA regime changes:
A flip in EMA 12 versus EMA 21, coupled with a turn in PoC slope, is a strong signal that value is beginning to move with the new trend.
If EMAs flip but PoC migration does not follow, the trend signal may be early or false.
A weakening PoC path (lower highs in PoCs) while trend colors are still green can warn of a late-stage trend.
Best practices
Start with a moderate lookback such as 200 to 300 bars and a moderate bin count such as 20 to 40. Too many bins can make the profile overly granular and sparse.
Align "Bars per Segment" with your trading horizon. For example, 5 to 10 bars for intraday, 10 to 20 bars for swing.
Use the profile and PoC trail as structural context rather than as a direct buy or sell signal. Combine with your existing setups for timing.
Pay attention to clusters of PoCs at similar prices. Those are areas where the market has repeatedly accepted value, and they often matter on future tests.
Notes
This is a structural volume tool, not a complete trading system. It does not manage execution, position sizing or risk management. Use it to understand:
Where the bulk of trading has occurred in your chosen window.
How the center of volume has migrated over time.
Whether that migration is aligned with or fighting the current trend regime.
By turning PoC evolution into a visible path and adding a trend-aware heatmap, the PoC Migration Map makes it easier to see how value has been moving, where the market is likely to feel "heavy" or "light", and how that structure fits into your trading decisions.

TF7 Option vs Index Change RatioOverview
This indicator helps traders visualise the strength and direction of an option's price movement compared to its underlying index (NIFTY or SENSEX).
It calculates a Change Ratio, which is the percentage move in the option compared to the index movement during the same bar. This is especially useful for intraday traders looking for signs of momentum, divergence, or unusual strength/weakness in option pricing.
How It Works
The ratio is calculated as:
(Option LTP − Option Open) / (Index Close − Index Open)
The value is capped between −10 and +10 to filter out extreme or invalid spikes.
The ratio is displayed as a color-coded column chart:
🟩 Green bars: Option is moving in the same direction as the index.
🟥 Red bars: Option is underperforming or moving opposite to the index.
A compact table shows the last 5 bars of:
Option price change (with +/− sign)
Index price change
Calculated ratio (also color-coded)
You can toggle the table visibility in the settings.
Inputs & Features
Select underlying index: NIFTY or SENSEX
Toggle the data table display
Clean formatting with signed values and conditional color highlights
⚠️ Disclaimer
This is a visual analysis tool, not a buy/sell signal. Always validate with your trading strategy and risk management
#OptionsTrading, #NIFTY, #SENSEX, #ChangeRatio, #IndexAnalysis, #Momentum, #Divergence, #Intraday
